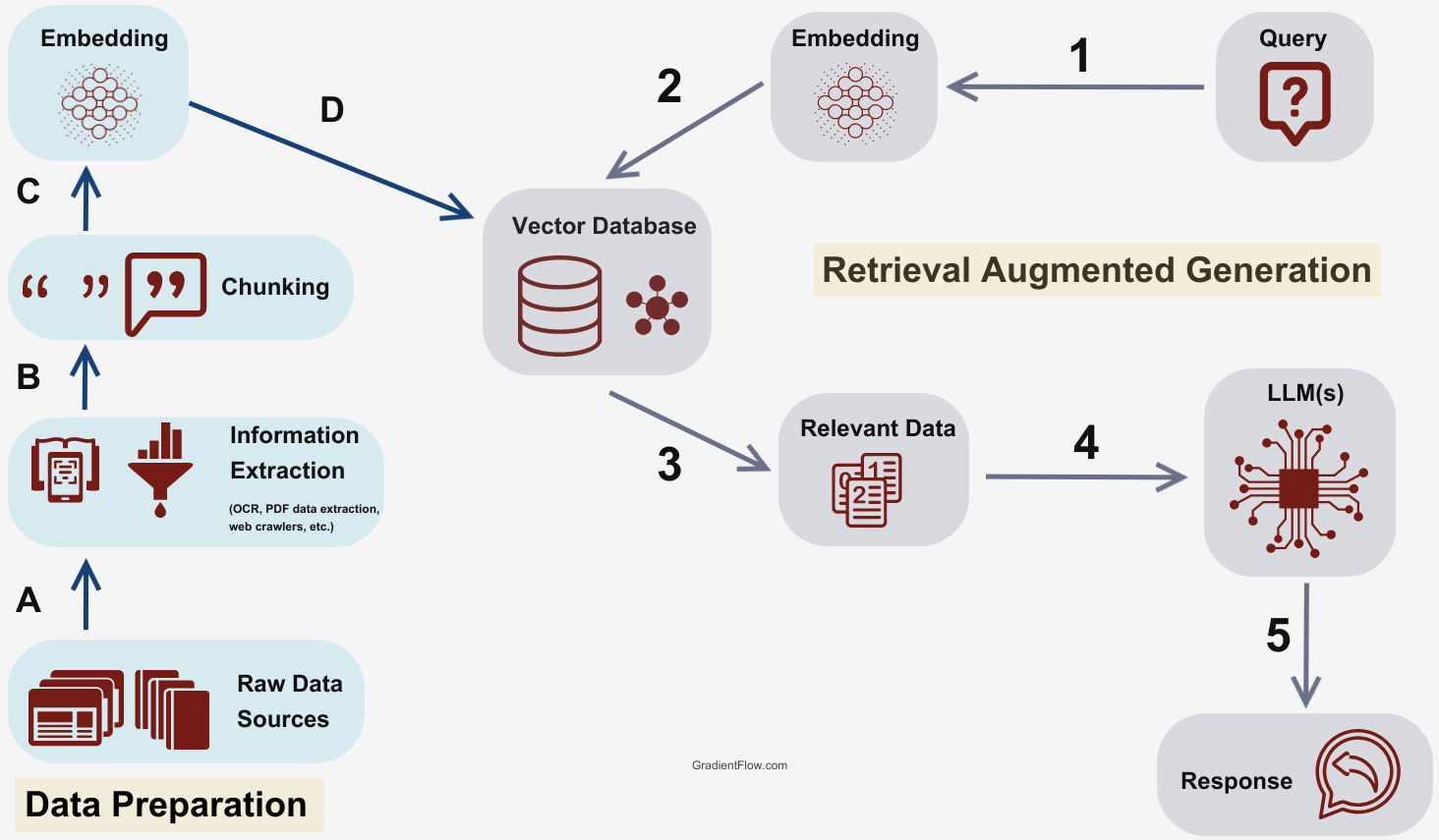
Tutorials make this shit look easy: install LangChain, create an index, upload your docs, done. Then you deploy to production and everything breaks. Pinecone's pricing calculator is complete bullshit - multiply everything by 3 and you'll be closer to reality. Started with their "starter" plan thinking we'd spend maybe $100/month. Six months later? $800+ bills and our traffic hadn't even grown.
Here's what breaks your budget: read operations. Every fucking similarity search costs you. That innocent k=10 parameter in your search? Each of those 10 results is a billable read. Scale that across thousands of user queries and you're absolutely fucked.
The Architecture That Actually Works (After 3 Rewrites)


Our RAG system shit the bed during a product demo. Here's what I figured out:
Serverless vs Pods: The Real Difference
- Serverless: Scales automatically but takes 10-30 seconds to wake up from cold starts after 15 minutes of inactivity. Perfect for demos, terrible for production traffic spikes. S1 pods start at $70/month, P1 pods at $100/month.
- Pods: Always on, predictable 20-80ms responses, but you pay $70-400+ per pod monthly whether you use them or not. Like renting vs buying - expensive but reliable.
The Pinecone docs won't tell you this: serverless cold starts will kill your user experience. We learned this when our chatbot took 45 seconds to respond after periods of low traffic. Users thought it was broken.
LangChain Integration: What Actually Breaks
![]()

The LangChain integration looks clean in tutorials. Reality is messier:
## This timeout is crucial - Pinecone randomly hangs sometimes
from langchain_pinecone import PineconeVectorStore
import os
## Don't use the docs example - it breaks in production
pc = Pinecone(
api_key=os.getenv("PINECONE_API_KEY"),
timeout=30 # Found this the hard way during a production outage
)
## Rate limiting because Pinecone will fuck you on quotas
import asyncio
await asyncio.sleep(0.2) # Magic sleep or you get 429'd to hell
Production Gotchas That Will Ruin Your Weekend:
- Connection timeouts aren't handled by default - Your app will hang for 60+ seconds on network issues. Default timeout is 5 minutes.
- Rate limits hit without warning - 429 errors start flying when you exceed 100 operations/second on starter, 200/sec on standard plans
- Metadata filtering breaks with complex queries - OR operations, nested arrays, and date range filters have documented limitations. String filters are case-sensitive.
- Namespace operations are eventually consistent - Deleting a namespace? Wait 30-60 seconds or your queries return stale data. No error, just wrong results.
Cost Optimization: Hard-Won Lessons
Expensive lesson: I used the big embedding model for everything like an idiot. Burned something like two, maybe three grand before switching to text-embedding-3-small, which works fine for most stuff. The small one has 1536 dimensions vs 3072 for the large model - half the storage cost, thank fuck.
Finally got smart and added Redis caching for frequent queries. Cut Pinecone read operations by like 70%, saves us hundreds monthly. Should've done this shit from day one.
## Nuclear option: cache everything for 1 hour
import redis
import json
import hashlib
cache = redis.Redis(host='localhost', port=6379)
def cached_search(query_text, k=5):
cache_key = f"pinecone:{hashlib.md5(query_text.encode()).hexdigest()}"
# Check cache first
cached = cache.get(cache_key)
if cached:
return json.loads(cached)
# Query Pinecone if not cached
results = vectorstore.similarity_search(query_text, k=k)
# Cache for 1 hour
cache.setex(cache_key, 3600, json.dumps([doc.page_content for doc in results]))
return results
Regional Selection Matters: US-East-1 is cheapest but EU-West-1 costs 20% more. Data residency requirements for European customers mean you're stuck with the higher costs. Check the regional pricing breakdown before choosing your deployment region.
Index Configuration That Actually Matters:
- Use `cosine` similarity unless you have a damn good reason not to
- `dot_product` is faster but only works if your embeddings are normalized
- `euclidean` is usually wrong for text embeddings - here's why
Production Monitoring: The Stuff That Keeps You Sane
Set up these alerts or prepare for 3am debugging sessions:
## This monitoring shit saved my ass when everything died at 3am
from prometheus_client import Counter, Histogram
pinecone_errors = Counter('pinecone_errors_total', 'Pinecone failures')
pinecone_latency = Histogram('pinecone_query_seconds', 'Query duration')
## Wrap every Pinecone operation
def monitored_query(query_text):
start_time = time.time()
try:
results = vectorstore.similarity_search(query_text)
pinecone_latency.observe(time.time() - start_time)
return results
except Exception as e:
pinecone_errors.inc()
# Log the actual error - Pinecone's error messages are fucking useless
logger.error(f"Pinecone shat itself: {str(e)}, Query: {query_text[:100]}")
raise
Critical Alerts:
- Query latency > 5 seconds (something's wrong)
- Error rate > 1% (API issues or quota problems)
- Monthly cost variance > 25% (usage spike or configuration change)
It works, but it's nowhere near as smooth as their marketing bullshit suggests. Budget twice what you think... no, fuck that, make it three times. You'll still be wrong. Implement caching from day one and monitor everything, because production deployments are way messier than they admit.
Architecture and costs are just the beginning though. The real nightmare starts when you need to process actual documents and get them into your vector database reliably...
For more production insights, check out the Pinecone community forum, AWS reference architecture, and monitoring best practices.