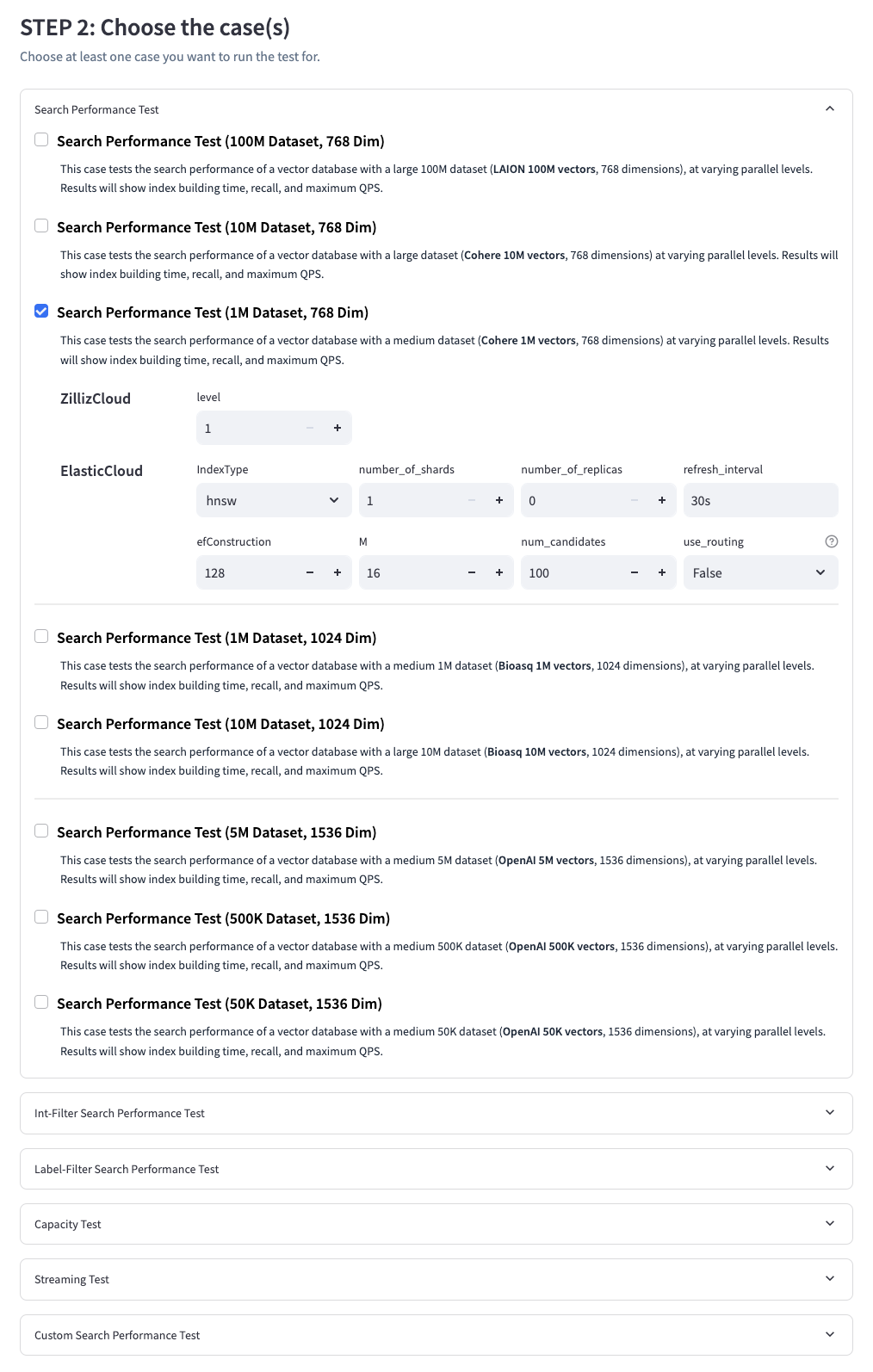
Look, I've been down this rabbit hole. You're trying to pick a vector database and every vendor shows you these beautiful benchmark charts where their database absolutely destroys the competition. Problem is, those benchmarks are testing toy scenarios that have nothing to do with your actual workload.
VectorDBBench exists because someone at Zilliz got as frustrated as I did with this bullshit. Version 1.0.8 released in September 2025 represents a major step forward and it's the first benchmarking tool that actually tries to break databases the way production will.
The Three Ways Traditional Benchmarks Lie to You
They Test Ancient Data Formats: Most benchmarks still use SIFT datasets with 128 dimensions. Meanwhile, your OpenAI embeddings are 1536D and Cohere's latest models push 4096D. The performance characteristics are completely different - what works for 128D vectors will fall over when you hit it with modern embedding sizes.
They Show You Vanity Metrics: "Look, 50,000 QPS!" Yeah, for 30 seconds with no concurrent writes and perfect cache conditions. Real production cares about P99 latency when your database has been running for 6 hours straight with users hammering it. Average latency is meaningless when half your queries take 2+ seconds.
They Ignore Production Chaos: Traditional benchmarks test the happy path - build index, run queries, done. Real systems have streaming ingestion happening while users are searching, metadata filters that eliminate 99.9% of vectors, and the kind of concurrent load that makes poorly designed databases shit themselves.
How VectorDBBench Actually Tests Reality

Instead of synthetic bullshit, VectorDBBench uses vectors from real embedding models: Wikipedia dumps processed through Cohere embeddings, BioASQ datasets at 1024D, and web-scale corpora with 138 million vectors. You know, the kind of data you'll actually be indexing.
It tests streaming workloads where data keeps coming in while queries are running. It throws high-selectivity filters at databases and watches them die. It measures sustainable throughput over hours, not peak performance over seconds.
Most importantly, it focuses on the metrics that actually matter in production: P95/P99 latencies, recall accuracy under load, and whether your database can handle Friday afternoon traffic without falling over.
I tested this against our production Pinecone setup and the results were scary accurate. If VectorDBBench says a database will handle 10k QPS sustained, it probably will. If traditional benchmarks say it'll handle 50k QPS, it definitely won't.