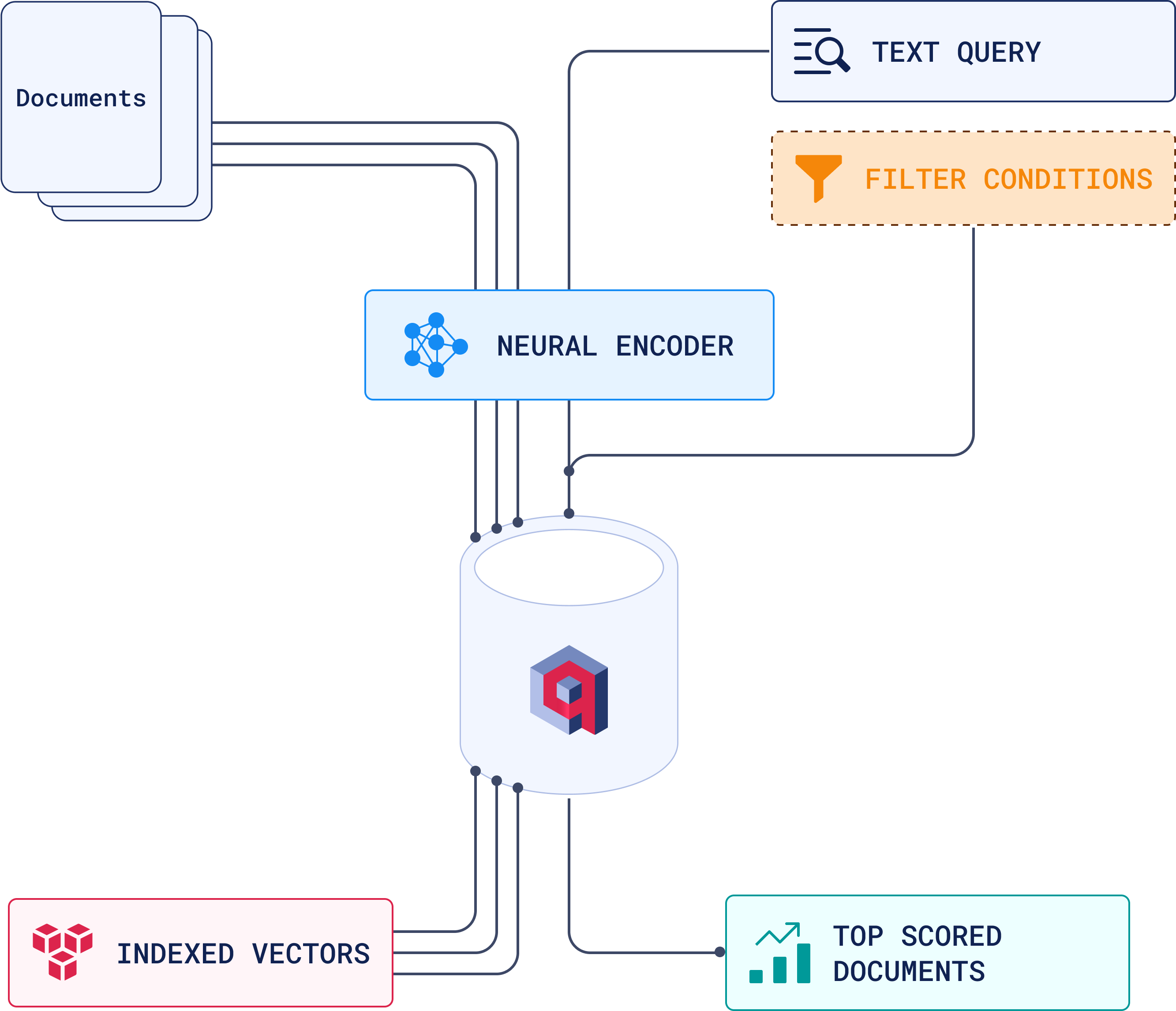

Started using Pinecone about 3 years ago because it was the path of least resistance. Good docs, worked out of the box, no Docker setup required. Classic build vs buy decision - we had a product to ship, not database expertise to build.
The Bill That Made Me Lose My Shit
So we're trucking along, embedding search is working fine, about 4M vectors in Pinecone. Bill was predictably around $180/month. Then we pushed a big content update, got up to around 10M vectors.
Next billing cycle: $847.32.
I stared at that invoice for like 10 minutes thinking it was a mistake. Called their support - nope, just crossed some magic threshold into "enterprise" pricing. No heads up, no email saying "hey you're about to get fucked," just surprise enterprise prices.
That's when I got stubborn and decided to test every vector database on the planet.
What Actually Drove Me Crazy
Query performance got shittier as we scaled. Started seeing 20-30ms responses at 2M vectors. By 8M vectors, we're hitting 60-100ms consistently. Their "auto-scaling" basically just spins up more pods that seem to hate talking to each other.
The API syntax is from another planet. Look at this garbage: filter={"$and":[{"genre":{"$in":["action","comedy"]}},{"year":{"$gte":2020}}]}. Every other database on earth uses SQL or at least normal REST queries. Who approved this filtering syntax?
Complete black box. When shit breaks, you get error messages like "Request failed with status 500." Cool, thanks. No logs, no metrics you can see, no way to tune anything. It either works or it doesn't.
What I Found After Testing Everything
Spent about 3 weeks going through Qdrant, Weaviate, ChromaDB, pgvector, even tried setting up FAISS from scratch (don't).
Qdrant was the winner - same 8M vector dataset, query times dropped to around 15-20ms. Turns out it wasn't our data or embeddings that were slow, it was Pinecone. Though I did hit a weird bug in Qdrant 1.7.3 where the REST API would randomly return 504s under heavy load. Fixed in 1.7.4 but caused a fun afternoon of debugging.
pgvector surprised me - if you're already running Postgres, just use this. Added it to our existing tables and had semantic search working in maybe an hour. Performance isn't amazing but it's totally fine for most apps. One gotcha: the HNSW index creation will lock your table for like 20 minutes on big datasets. Found that out the hard way during business hours.
ChromaDB works great until it doesn't - incredible developer experience, got a demo running in minutes. Then I tried it with real data and watched it consume 40GB of RAM before dying with some cryptic "index corruption" error. Turns out their persistent storage in version 0.4.x was basically broken with large datasets. They've since released 1.0+ which supposedly fixes a lot of this, but I haven't had time to test it thoroughly in production. Still using it for prototypes only.
The Migration Nightmare (And Happy Ending)
Getting data out of Pinecone is a pain in the ass. They export in some proprietary binary format that took me way too long to figure out. Ended up writing a shitty Python script to convert everything to standard vectors.
The actual migration to Qdrant took most of a weekend - not because Qdrant is hard, but because I kept second-guessing myself and testing different configurations.
Final result: went from ~$800/month to around $60/month in AWS costs. Same search quality, better performance, and I can actually see what's happening when things break.