RAG systems look simple in demos - upload some docs, ask questions, get answers. Reality? Your vector database crashed three times this week eating 200GB of RAM, your OpenAI bill hit $8,247 last month (still fighting accounting over that), and you've debugged why embeddings return garbage results at 3AM more times than you want to count.
I've deployed dozens of these systems over the past two years. Here's what actually happens when you try to scale RAG beyond toy examples.
The Five Things That Will Ruin Your Week
Vector databases are memory-hungry beasts. That "sub-100ms" Pinecone marketing claim? Sure, if you're okay paying $3,000/month for their performance tier. Weaviate clusters crash when they run out of memory, which happens faster than you think with real datasets.
Embedding models break in weird ways. OpenAI occasionally updates embedding models without notice - happened to us with ada-002 in early 2024, making all cached embeddings worthless overnight. Multiple GitHub threads document this problem with dozens of frustrated developers.
LLM APIs go down at the worst times. OpenAI has had major outages during high-traffic periods before. Anthropic's Claude went offline during our quarterly review last year. If your entire product depends on external APIs, you're one outage away from disaster.
Data ingestion pipelines are fragile. PDF parsing breaks on documents with weird fonts. Text extraction fails on scanned images. That 500-page compliance manual? Half the pages will parse as gibberish.
Context windows fill up fast. GPT-4's 128K context sounds huge until you stuff it with retrieved documents. You'll hit limits faster than expected, and truncation strategies either lose important info or break coherence.
What Actually Works in Production
Skip the academic papers and vendor marketing bullshit. After burning through $50K+ in failed deployments, here's what survives contact with real users:
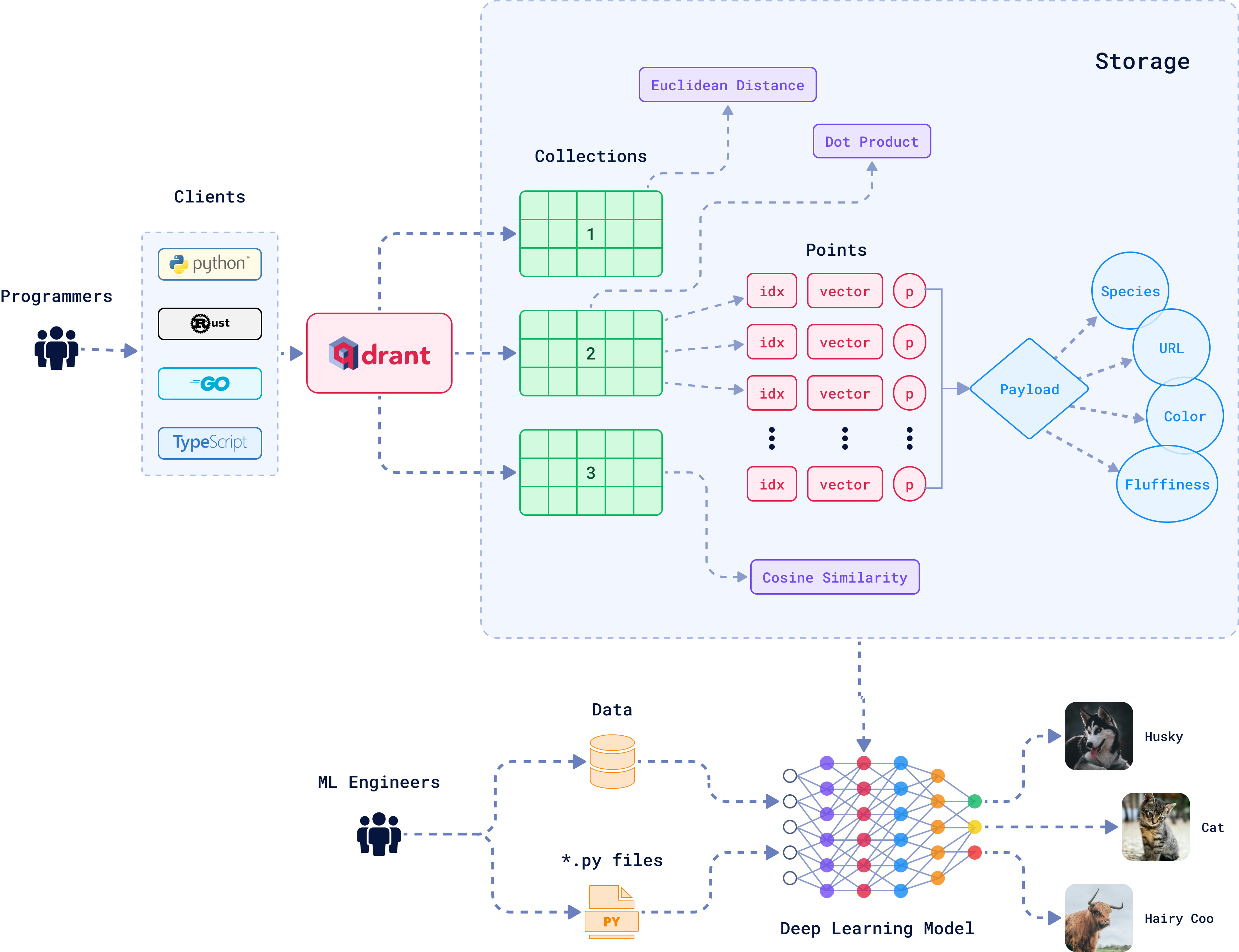
Start with self-hosted Qdrant or Weaviate. Both handle memory pressure better than the alternatives. Qdrant's quantization reduces RAM usage by 75% without destroying accuracy. Memory-mapped indices keep costs sane.
Cache everything aggressively. Semantic caching at the query level prevents duplicate LLM calls. Redis cluster with 50GB+ memory sounds expensive until you see your first $10K OpenAI bill.
Plan for model changes. Every embedding model update breaks existing indices. Version your embeddings and plan migration strategies. Sentence-transformers models are more stable than proprietary APIs.
Monitor token usage religiously. Claude costs $0.025 per 1K input tokens. A chatbot with long contexts burns through $500/day fast. Implement hard limits before users bankrupt you.
The hardest lesson: RAG systems that work in notebooks fall apart under real traffic. Budget 3x longer than you think for production deployment.