I've Been Fooled Before - Here's What Actually Happens
Pinecone's benchmarks showed 8ms P95 latency. Looked perfect. Spent three weeks integrating it, deployed to prod, and immediately hit 800ms P95 - over 2 seconds at P99. Their benchmarks never tested metadata filtering with realistic cardinality. Spent two weeks rebuilding our search with a different database while explaining to the CTO why our "lightning-fast" search was now slower than our old Postgres full-text setup.
The problem isn't just Pinecone - every vendor does this shit:
They Test Perfect Scenarios: Elasticsearch vector search benchmarks show millisecond queries, but they don't mention indexing takes 6+ hours and performance goes to hell once your index hits memory limits. I've debugged this at 3am way too many times.
Fake Data That Doesn't Match Reality: Most benchmarks still use SIFT datasets with 128 dimensions. Meanwhile, I'm running OpenAI embeddings at 1,536 dimensions and Cohere Wikipedia embeddings at 768 dimensions. Higher dimensions absolutely destroy memory performance - 768D vectors take 6x more memory than SIFT's 128D.
Vanity Metrics That Don't Matter: Peak QPS looks great in slides, but what happens when you have 50 concurrent connections, random query patterns, and memory fragmentation? Your "100k QPS" database suddenly can't handle 1000 QPS consistently.
So What Makes VectorDBBench Different?
After getting burned too many times, I was suspicious when VectorDBBench launched. Another vendor benchmark? But I dug into their methodology, and honestly, they're doing several things right:
They Test With Real Embedding Models: Finally, someone using Cohere's 768D Wikipedia embeddings and OpenAI's 1536D vectors instead of that ancient SIFT garbage. Performance patterns are completely different with high-dimensional data - my production costs jumped 3x when I switched from SIFT-like datasets to real embeddings.
They Actually Test Concurrent Load: Most benchmarks test single queries. VectorDBBench hammers the database with concurrent streaming ingestion and queries - you know, like what happens in actual production.
It's Open Source and Reproducible: You can check their code, verify their configurations, and run your own tests. Can't do that with vendor benchmarks that just show you pretty charts.
They Measure What Actually Breaks: P95/P99 latency, sustained throughput degradation, memory usage spikes - all the shit that takes down your production system when traffic spikes.
But here's the catch: it's built by Zilliz, the company behind Milvus. So obviously there's potential for bias. The question is whether they're being honest about it or just building more sophisticated marketing.
The Bias Test: Does Milvus Always Win?
Here's my litmus test for any vendor benchmark: does their product magically win every category? If so, it's marketing bullshit.
I spent time digging through the VectorDBBench leaderboard, expecting to see Milvus crushing everyone. But actually:
- Pinecone beats ZillizCloud in several test cases, especially for small-scale workloads
- Qdrant outperforms Milvus on some memory-constrained scenarios
- Weaviate shows competitive results for specific embedding models
- Self-hosted Milvus performs differently than their cloud offering - which is realistic, not fake consistency
This doesn't immediately scream "rigged benchmark." But I've seen subtle bias before - maybe they chose test scenarios where Milvus naturally performs well, or tuned configurations more carefully for their own product. Here's where it gets tricky.
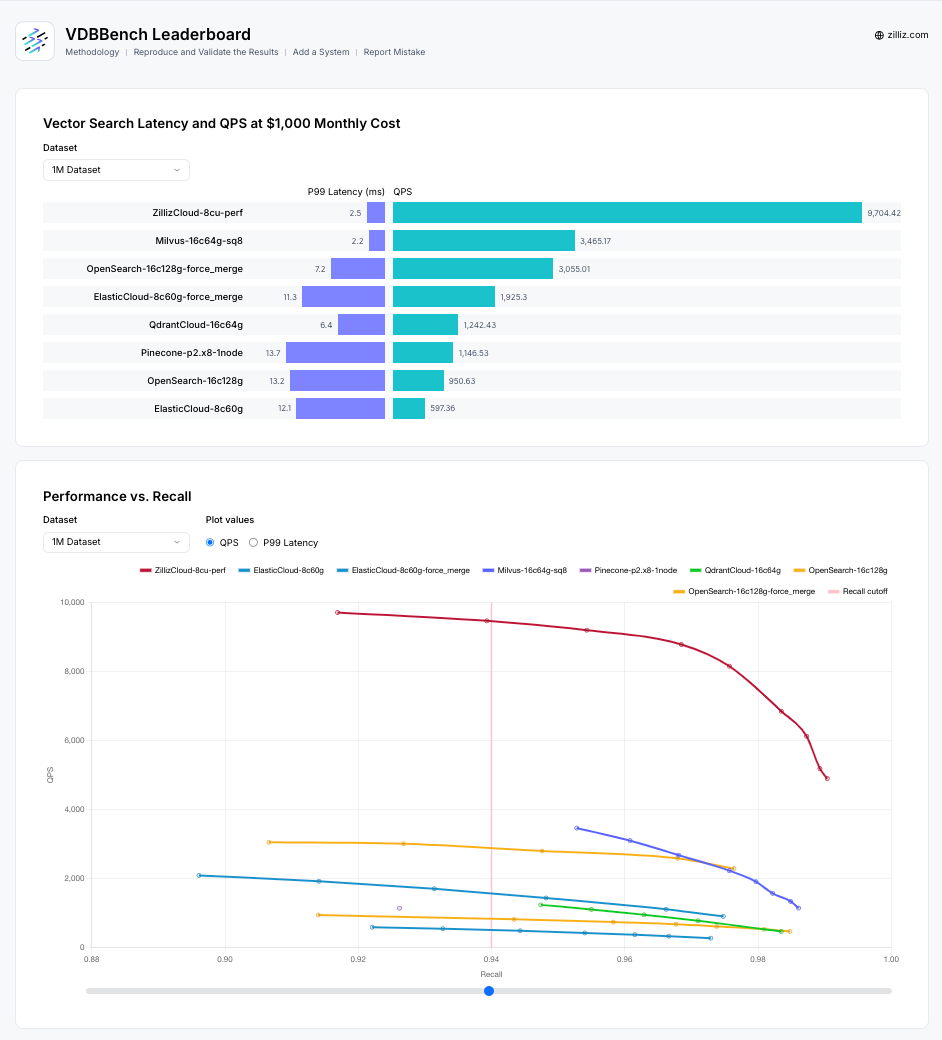
The VectorDBBench 1.0 dashboard provides comprehensive performance visualizations, but the key question is whether the underlying methodology is truly objective.
Where the Bias Could Be Hiding
Even if they're trying to be fair, there are tons of ways bias creeps into benchmarks. Here's what I looked for:
Configuration Expertise Gap: Who tuned these database settings? Zilliz engineers obviously know Milvus configuration inside and out. Did they spend the same effort optimizing Pinecone clients or Qdrant settings? This kind of expertise imbalance can swing performance by 2-3x easily. Each database requires domain-specific knowledge that could impact results.
Cherry-Picked Test Scenarios: The dataset choices (Wikipedia vectors, BioASQ medical data) might accidentally favor certain database architectures. Some databases love uniform vector distributions, others handle sparse or clustered data better.
Hardware Assumptions: They standardize on specific cloud instance types, but Elasticsearch loves memory, Pinecone is optimized for their specific infrastructure, and Qdrant prefers SSDs. Standard hardware might inadvertently favor whoever designed for those specs.
Metric Weighting Games: They average across all test scenarios equally, but some workloads matter way more than others. If you're doing real-time recommendations, latency P99 is everything. If you're doing batch analysis, throughput matters more. Equal weighting might not reflect real priorities.
At least VectorDBBench is open source, so you can actually verify this stuff instead of taking their word for it.

Here's an example of how different benchmark approaches can show different performance patterns. Redis published their own vector database benchmark showing significant performance advantages, but results vary significantly based on test methodology and configuration choices.

Different vector databases use different indexing approaches (IVF, HNSW, etc.), which explains why performance varies so dramatically across benchmark results. VectorDBBench tries to test these fairly, but configuration expertise still matters.

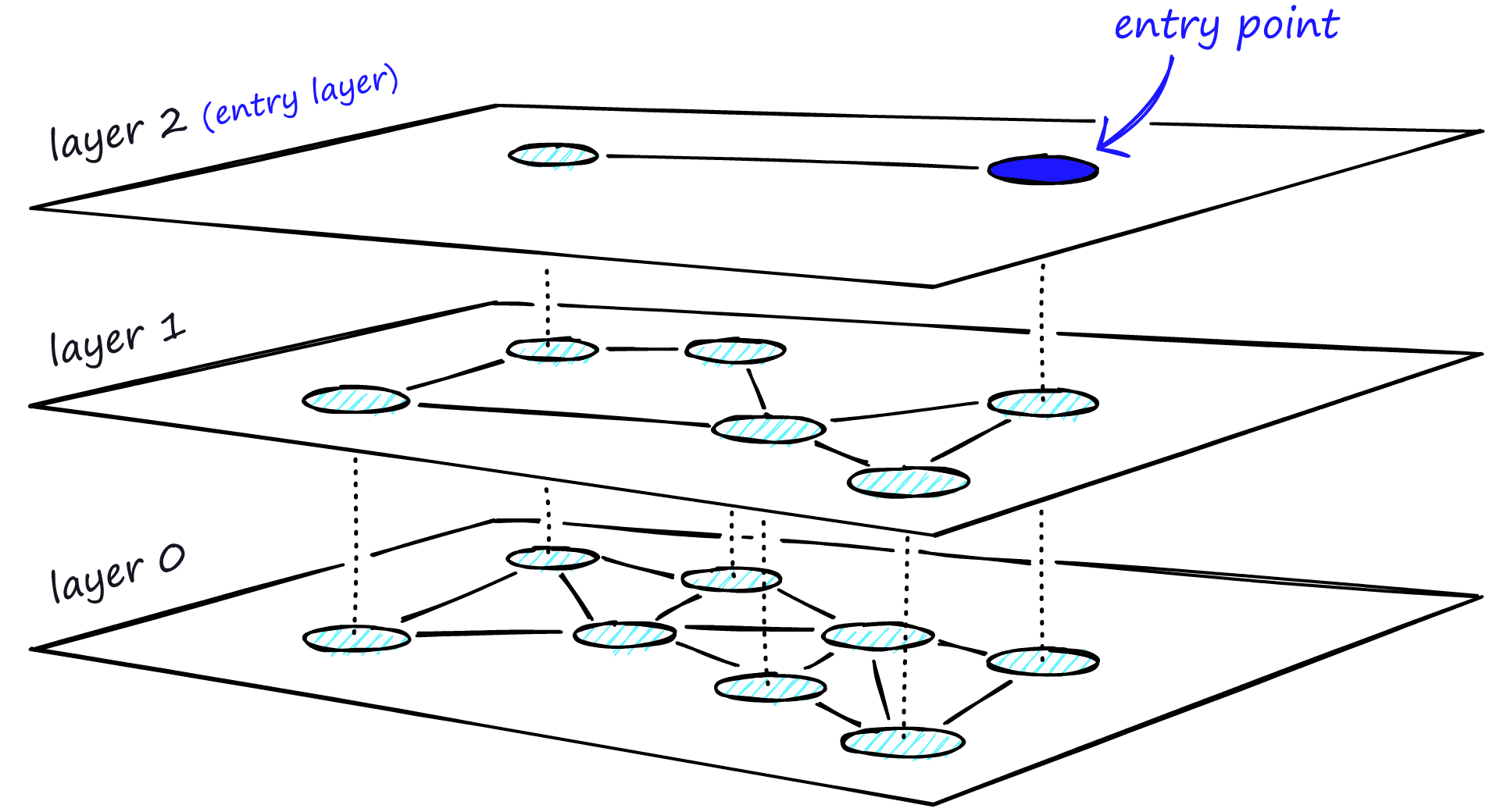 Understanding vector database index structures like HNSW helps explain why benchmark results can vary so dramatically. Different databases optimize these structures differently, leading to performance variations that benchmarks try to capture.
Understanding vector database index structures like HNSW helps explain why benchmark results can vary so dramatically. Different databases optimize these structures differently, leading to performance variations that benchmarks try to capture.