Look, I need to benchmark vector databases regularly, and VectorDBBench is what I keep coming back to. Not because it's perfect - it's got issues. But because everything else is worse.
The Problem with Vector DB Benchmarking
Here's the thing about vector database benchmarks: they're all bullshit to some degree. Vendor benchmarks are rigged (shocking, I know), academic papers use toy datasets, and rolling your own means you'll spend 3 weeks writing test harnesses instead of actually evaluating databases.
VectorDBBench at least tries to be somewhat fair. Yeah, it's made by Zilliz (the Milvus people), but I was surprised that the methodology is actually open source and you can see exactly what it's doing. Plus, in my testing, Milvus doesn't always come out on top, which gives me some confidence in the results. The benchmarking approach is documented and reproducible.
The tool hits about 20 different vector databases - everything from Pinecone to that PostgreSQL pgvector setup your backend team insists on using. It uses real datasets like SIFT and Cohere's Wikipedia embeddings instead of synthetic garbage. Check the supported database list for compatibility with your stack.
What It Actually Tests (And Why That Matters)
The three main test scenarios are pretty realistic:
Insert Performance: How fast can you shove new vectors in? Critical if you're doing real-time updates and don't want your ingestion pipeline to become a bottleneck. The tool measures insertion throughput under different load conditions.
Search Performance: Basic QPS and latency under load. The concurrent testing is especially useful - most databases perform differently when you're hammering them with parallel queries. Check the performance testing methodology for details.
Filtered Search: This one's huge. Combining vector similarity with metadata filters is where most vector databases fall apart completely. VectorDBBench actually tests this properly unlike most benchmarks that ignore filtering performance.
The Numbers Game
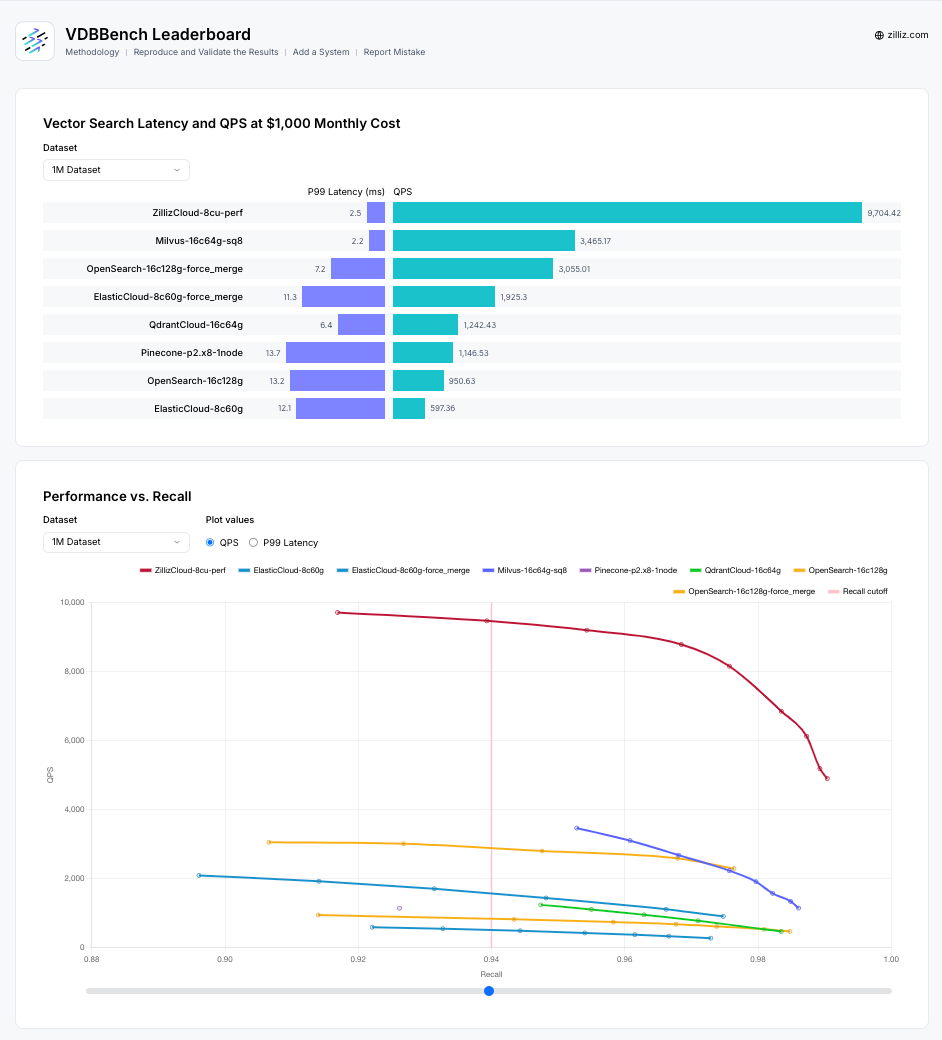
The tool tracks P99 latency, which is actually important unlike the QPS dick-measuring contests most benchmarks focus on. You care about the slow queries because those are what kill your user experience. Read about why P99 matters for production systems.
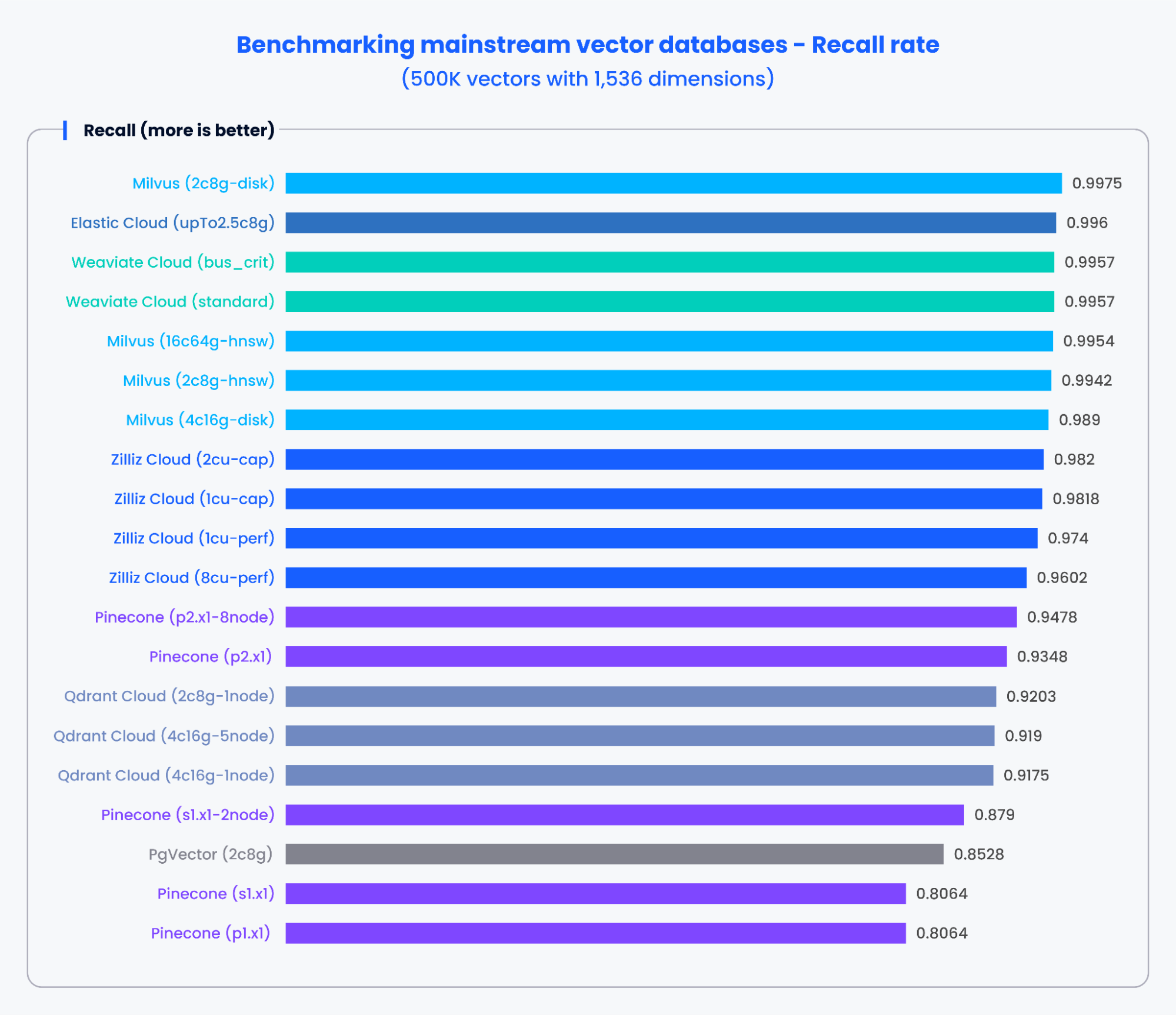
The recall tracking is also solid - there's always a speed vs accuracy tradeoff, and VectorDBBench makes it visible instead of just showing you the fastest possible queries with terrible accuracy. The ANN benchmark methodology explains why this matters.
That said, take the specific numbers with a grain of salt. The "leaderboard" shows things like "ZillizCloud: 9,704 QPS" but in my experience, your mileage will vary dramatically based on your specific setup, data, and whatever your ops team did to the networking. Check the benchmark result interpretation guide for context.

The performance charts look impressive, but remember these are controlled conditions with optimized configurations. Your production environment will likely behave differently.