![]()
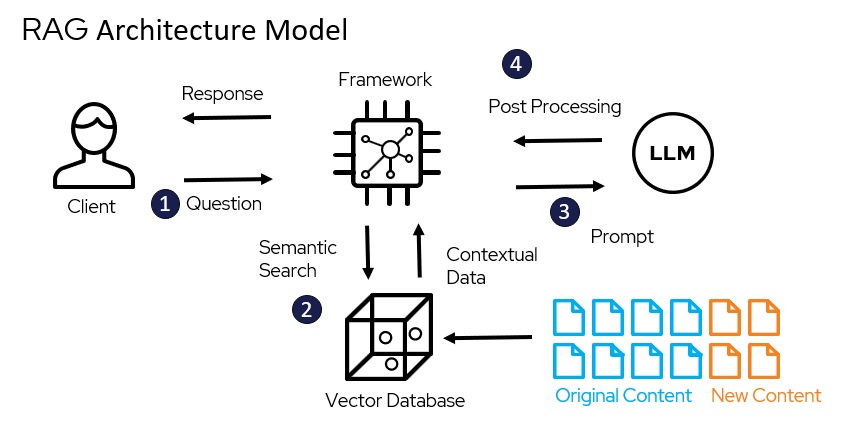
RAG is supposed to fix LLM hallucinations by searching your documents first. Simple concept: user asks question, grab relevant text, feed to LLM, get better answer. In practice, every step of this breaks.
I learned this after three painful production deployments. The first one worked great in staging with our 50-document test set. Put it in production with 50,000 customer documents and watched it burn through our Pinecone budget in 6 days.
What Actually Breaks in Production

LangChain is a framework for people who hate their future selves. The memory leak in their agent system took down our production API twice. Every update breaks something new - check their GitHub issues and you'll see hundreds of compatibility problems. The documentation assumes you already know what the hell you're doing, but if you knew that, you wouldn't need their framework.
We spent 3 weeks trying to get their agent system working reliably. Finally gave up and wrote 200 lines of Python that did the same thing without randomly failing.
LlamaIndex markets itself as the "simple" option through their documentation. It is simple - until you feed it real documents. Our legal PDFs maxed out memory on 32GB instances. Their indexing process would just die. No error message. No logs. Just dead processes and confused engineers at 3am.
The breaking point was when it silently corrupted our document index. Check their issue tracker - memory problems and indexing failures are recurring themes. Took us 4 hours to figure out why search results were returning garbage.
Dify has a pretty interface that impresses non-technical stakeholders through their visual workflow designer. Great for demos. Terrible for anything real. The moment you need custom logic or want to debug why responses are weird, you're screwed. It's a black box that works until it doesn't.
We tried deploying Dify with 100 concurrent users. Containers crashed every 20 minutes. Memory usage spiked randomly. Their GitHub issues are full of scaling problems and memory leaks from other people having the same problems.
The Stuff They Don't Tell You
Your chunking strategy will suck. Every framework has "smart" chunking that works great on blog posts. Feed it technical documentation or legal contracts and watch it split critical information across chunks. Check out chunking strategies research - even the experts struggle with this. Good luck debugging why the answer is incomplete.
Vector search is not magic. It finds semantically similar text, not logically related text. Ask about "contract terms" and get back text about "agreement conditions" that's missing the actual terms you need. The limitations of semantic search are well-documented but rarely discussed in framework marketing.
Embeddings drift over time. Update your embedding model? Your entire index is now unreliable. There's no clean upgrade path. You rebuild everything and pray. OpenAI's embedding models change regularly, breaking backward compatibility.
Costs explode fast. Started at $200/month for our Pinecone vector database. Grew to $800/month as we added documents. That doesn't include the compute costs for embedding generation or the LLM API calls.
Most successful RAG deployments I've seen are 300 lines of Python with OpenAI's API and a Postgres database with pgvector. The frameworks just add places for things to break.


 Here's what our last RAG deployment actually cost:Month 1: $300 (looked reasonable)Month 3: $800 (documents grew faster than expected)Month 6: $1200 (users started asking complex questions requiring more context)Month 12: $1800/month (plus 2 developers debugging framework issues full-time)The framework was "free." Everything else wasn't.
Here's what our last RAG deployment actually cost:Month 1: $300 (looked reasonable)Month 3: $800 (documents grew faster than expected)Month 6: $1200 (users started asking complex questions requiring more context)Month 12: $1800/month (plus 2 developers debugging framework issues full-time)The framework was "free." Everything else wasn't.