Been using Haystack for the past few months, and it's the first RAG framework that didn't make me want to quit programming. Built by deepset, it's got 22k GitHub stars and somehow convinced companies like Airbus and NVIDIA to actually use it.
If you've tried building RAG apps before, you know most frameworks are broken. LangChain breaks in production. AutoGPT is a science experiment. But Haystack? It actually works when you deploy it, which is weird for AI frameworks.
Why Haystack Doesn't Suck
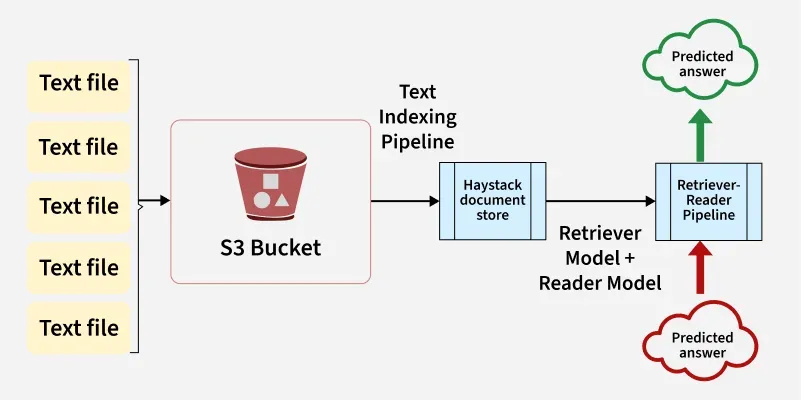
The thing that sold me on Haystack is its pipeline approach. Instead of magic black boxes, you can see exactly how data flows between components. When something breaks (and it will break), you can actually debug it without sacrificing a goat to the AI gods.
No Framework Lock-in Hell: Want to switch from OpenAI to Claude? Fine. Anthropic to local models? Also fine. Learned this when our OpenAI bill got scary - couple hundred bucks turned into way more real quick. Swapping providers in Haystack took maybe 20 minutes, not 20 hours.
Memory Leaks Happen: Had a memory leak issue a few months back, took forever to get patched. Found out when our prod deployment started eating memory like crazy. Always test your pipelines under load before deploying.
Actually Works in Production: All the components are designed to not fall over when real users touch them. Pipelines are serializable, which means you can version control your entire ML workflow. Try doing that with most other frameworks.
Transparent Data Flow: You can see what each component does instead of trusting some abstraction that probably doesn't work. This saved my ass during a production incident where embeddings weren't matching between dev and prod.
Real-World Usage (The Good and Bad)
Alright, enough of my bitching. Here's who actually trusts this thing in production:
- Airbus - Internal docs search (makes sense, they can't afford downtime)
- The Economist - Content discovery (their search actually works)
- NVIDIA - Developer support systems (they know what they're doing)
- Comcast - Customer service automation (impressive they got this working)
Warning: Don't assume these companies are using the latest version. Enterprise usually lags 6+ months behind because upgrading breaks everything.
Most teams I've seen use it for:
- RAG that doesn't hallucinate every other response (hybrid search helps a lot)
- Multi-modal apps that can handle documents, images, and audio without exploding
- Chatbots that remember context longer than 5 minutes
- Enterprise search that actually finds relevant stuff (though I think that market's oversaturated)
Runs on Python 3.8+ and they're decent about backward compatibility. Recent versions added some debugging features that actually help - you can pause execution mid-run and see what's happening instead of guessing. Updates usually don't randomly break your pipeline, unlike some other frameworks.

Latest versions support multimodal pipelines that handle text and images together. Used it to process scanned PDFs that were giving us garbage results with pure text extraction.