
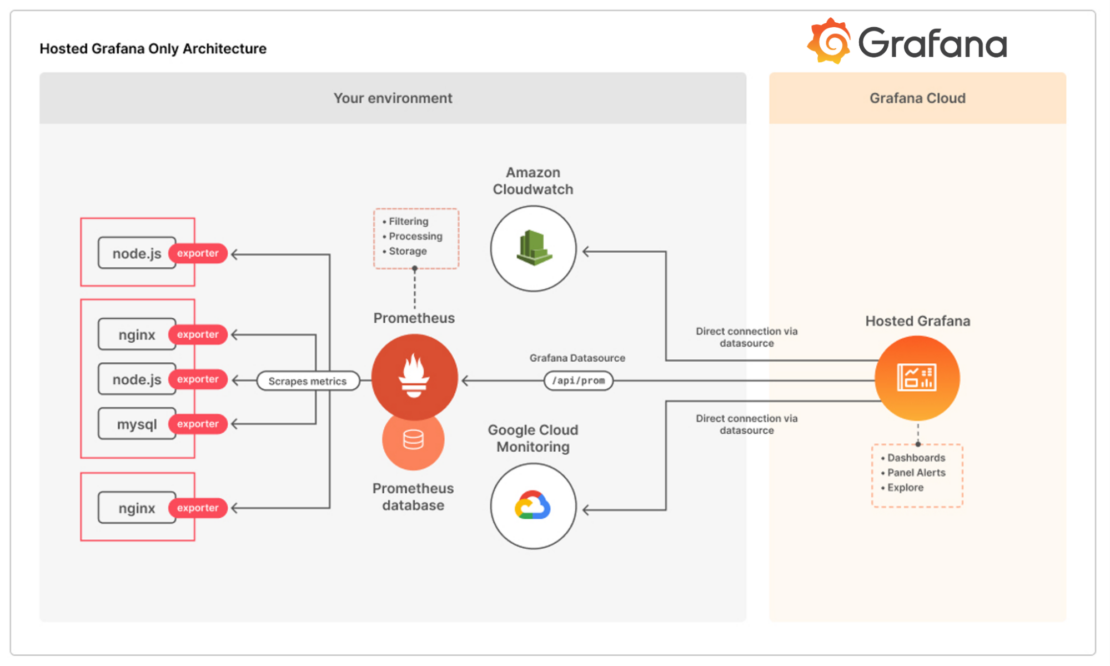
Memory Issues (The Classic Killer)
Error: bad allocation or std::bad_alloc
What really happened: ChromaDB ran out of memory and crashed harder than Internet Explorer.
The Fix That Actually Works:
## Give ChromaDB more memory to work with
docker run -d --memory=4g chromadb/chroma:latest
## If you're feeling generous (and have the RAM)
docker run -d --memory=8g --oom-kill-disable chromadb/chroma:latest
Why this keeps happening: ChromaDB loads your entire collection into memory for performance. Rule of thumb: collection size × 2.5 = RAM you need. I learned this after killing three staging environments. For troubleshooting memory allocation issues, see this Stack Overflow discussion and common performance problems guide.
The real fix: ChromaDB 1.0.21+ fixed most memory leaks. Before that, it would eat RAM like a poorly coded Electron app. Check this Reddit thread for CPU vs GPU performance differences.
SQLite Database Lock Errors
Error: database is locked or SQLite3.OperationalError
This happens when:
- Multiple ChromaDB instances fighting over the same database
- Docker crashed mid-write and left lock files behind
- You're on Windows (sorry)
The Solution:
## Find and nuke all lock files
find /path/to/chroma -name \"*.lock\" -delete
## Nuclear option when nothing else works
rm -rf /chroma_data && docker restart chromadb
Windows users: Just restart your machine. Windows file locking is fundamentally broken and I've given up trying to fix it properly. WSL2 works better.
Permission Denied Errors
Error: Permission denied when writing to /chroma_data
Docker's user mapping makes me want to burn my computer, but this actually works:
## Fix the ownership mess Docker created
sudo chown -R 1000:1000 /path/to/chroma_data
chmod 755 /path/to/chroma_data
## When all else fails, the sledgehammer approach
chmod 777 /path/to/chroma_data
Pro tip: This completely breaks if your username has a space in it. I wasted 2 hours on this once. Don't be me.
Collection Dimension Mismatch
Error: ValueError: could not broadcast input array
Your embeddings have different dimensions than your collection expects. ChromaDB is picky about this - it won't auto-convert like Pinecone does.
How to Actually Fix It:
## Check what dimensions your collection expects
collection_info = collection.get()
print(f\"Collection wants: {len(collection_info['embeddings'][0])} dimensions\")
## Check what you're trying to add
embedding = model.encode(\"your text here\")
print(f\"You're giving it: {len(embedding)} dimensions\")
## If they don't match, nuke and restart
client.delete_collection(collection_name)
collection = client.create_collection(collection_name)
Why this sucks: Most vector DBs handle dimension mismatches gracefully. ChromaDB just gives up and crashes. I've lost count of how many times this got me.
Container Won't Start
Error: Container exits immediately or health check fails
The usual culprits (in order of how often I see them):
- Port 8000 already taken: Some other service is squatting on it
- Mount path doesn't exist: Docker can't find
/your/chroma/path - Out of disk space: ChromaDB needs room to breathe
## See what actually went wrong
docker logs chromadb --tail 50
## Is something using port 8000?
netstat -tuln | grep 8000
## Does your mount path actually exist?
ls -la /your/chroma/path
Performance Issues
Symptoms: Queries taking forever, high CPU usage
ChromaDB performance is frustratingly inconsistent. Sometimes it's blazing fast, sometimes it takes forever for no apparent reason. For detailed performance analysis, check this querying performance discussion.
Things that actually help:
- Upgrade to 1.0.21+ (seriously, the performance improvements are real)
- Ditch the default embedding model in production - it's slow as hell
- Restart ChromaDB weekly - memory usage slowly creeps up over time
- Check your embedding dimensions aren't stupidly large
## Monitor memory usage
import psutil
print(f\"Memory usage: {psutil.virtual_memory().percent}%\")
## If it's above 80%, restart ChromaDB
The AVX512 Problem
Error: Illegal instruction (core dumped)
Version 1.0.21 added AVX512 optimizations that crash on older Intel chips. This breaks on anything older than 2017.
Fix: Use the non-AVX build or downgrade to 1.0.20:
docker run -d chromadb/chroma:1.0.20
Real talk: This should have been caught in testing, but here we are.
Network Timeouts
Error: Connection timeouts during large operations
ChromaDB doesn't handle network interruptions well. If you're adding millions of vectors and your WiFi hiccups, you're starting over.
Solutions:
- Use wired connection for large imports
- Add retry logic to your code
- Batch your operations smaller (500-1000 vectors max)
- Run ChromaDB locally during development
When All Else Fails
Sometimes ChromaDB just decides to be a pain in the ass. I've spent entire afternoons debugging issues that made zero logical sense.
Nuclear options (in escalating order of desperation):
- Delete everything and start over
- Switch to Qdrant (their Python client doesn't suck)
- Pay for ChromaCloud and make it someone else's problem
Before you rage quit:
- Check GitHub issues - your bug might already be reported
- Try the absolute latest version - they ship fixes pretty quickly
- Ask on their Discord - the community is actually helpful
- Read the troubleshooting docs (I know, reading docs is painful)
- Search Stack Overflow for your exact error message
- Check the deployment guides if you're having environment-specific issues
Look, ChromaDB works great when it works. But when it breaks, it breaks in spectacular ways. At least 1.0.21 fixed the memory leak that used to kill my containers twice a week.