Operators are custom controllers that actually understand what your application needs to stay alive. Regular Kubernetes controllers know how to restart pods and scale deployments, but they're clueless about database backups, certificate renewals, or the 47 steps it takes to properly upgrade your monitoring stack without breaking everything.
Why Standard Kubernetes Falls Short: Kubernetes gives you primitives - pods, services, volumes - but your actual applications need way more than "restart when it crashes." Take PostgreSQL: it needs replication, backups, failover, schema migrations, connection pooling. A vanilla Deployment? It knows fuck all about any of that.
The Operator Pattern: Controllers + Custom Resources + Domain Knowledge
The Operator pattern extends Kubernetes' declarative API by combining three key components:
1. Custom Resource Definitions (CRDs)
CRDs let you define new resource types that represent your app's config. Instead of wrangling dozens of YAML files for a database deployment, you get one clean PostgreSQL resource:
apiVersion: postgresql.example.com/v1
kind: PostgreSQL
metadata:
name: production-db
spec:
replicas: 3
version: "15.4"
backup:
schedule: "0 2 * * *"
retentionDays: 30
resources:
memory: "4Gi"
cpu: "2"
This one resource declaration handles a complete database setup with HA, automated backups, and resource allocation - shit that normally takes a dozen different Kubernetes resources.
2. Custom Controllers
The controller continuously monitors your custom resources and takes action to maintain the desired state. When you create the PostgreSQL resource above, the controller:
- Creates a StatefulSet for the database pods
- Configures persistent volumes for data storage
- Sets up services for database access
- Creates CronJobs for backup schedules
- Monitors database health and triggers failover if needed
- Handles database schema migrations during upgrades
3. Domain-Specific Operational Logic
This is what separates Operators from generic controllers. The PostgreSQL Operator actually knows database shit like:
- Master-slave setup: How to not fuck up your primary when a secondary dies (Primary-secondary relationships and streaming replication)
- Backup strategies: WAL archiving that actually works (when configured right), point-in-time recovery, and backup validation
- Upgrade procedures: Schema migrations (pray they're idempotent), compatibility checks, rollback strategies
- Monitoring: Database-specific metrics, slow query detection, connection pool monitoring
Real-World Impact: Before vs. After Operators
Without Operators (The Old Way)
Managing a production PostgreSQL cluster required:
- 15+ YAML files for StatefulSets, Services, PVCs, and ConfigMaps
- Custom shell scripts for backups, monitoring, and failover
- Manual intervention for scaling, upgrades, and disaster recovery
- Deep PostgreSQL expertise from the operations team
Result: Database deployments took days, failures required 3 AM emergency calls, and scaling required database expertise.
With Operators (The Operator Way)
The same PostgreSQL cluster becomes:
- 1 CRD defining the desired database configuration
- Automated backup, monitoring, and failover procedures
- One-command scaling and version upgrades
- Self-healing capabilities that fix common issues without human intervention
Result: Database deployments take minutes, most failures self-heal automatically, and scaling is handled declaratively.
Operators Actually Work Now (Most of the Time)
The operator ecosystem stopped being a complete shitshow sometime around 2023. Now there are operators that actually run in production without requiring a dedicated SRE team to babysit them.
What's changed: OperatorHub.io has 300+ operators that might not immediately break your cluster. Some of them even have documentation.
Why people use them: Managing stateful applications by hand gets old fast. Writing shell scripts that break at 3am gets even older. Operators automate the boring stuff so you can break things in new and creative ways.
Production Reality Check
What Actually Works (Sometimes)
Netflix definitely uses operators, though good luck finding details on their setup. Companies don't exactly publish blog posts about their operator disasters.
What I've Seen Break in Production
- Database operators that work fine for 6 months, then corrupt your primary during a "routine" failover
- Monitoring operators that delete all your metrics during upgrades (Prometheus Operator, I'm looking at you)
- Certificate operators that renew certs successfully but forget to reload the fucking applications
The Real Operator Experience
- Spend 3 days debugging why your operator isn't reconciling. Turns out you had a typo in the RBAC permissions.
- Operator works fine in development. In production, it can't reach the database because of network policies nobody told you about.
- Memory leak in your reconciliation loop brings down the entire cluster at 3am. Controller-runtime caches everything and your "simple" operator now uses 4GB of RAM.
The Technical Architecture
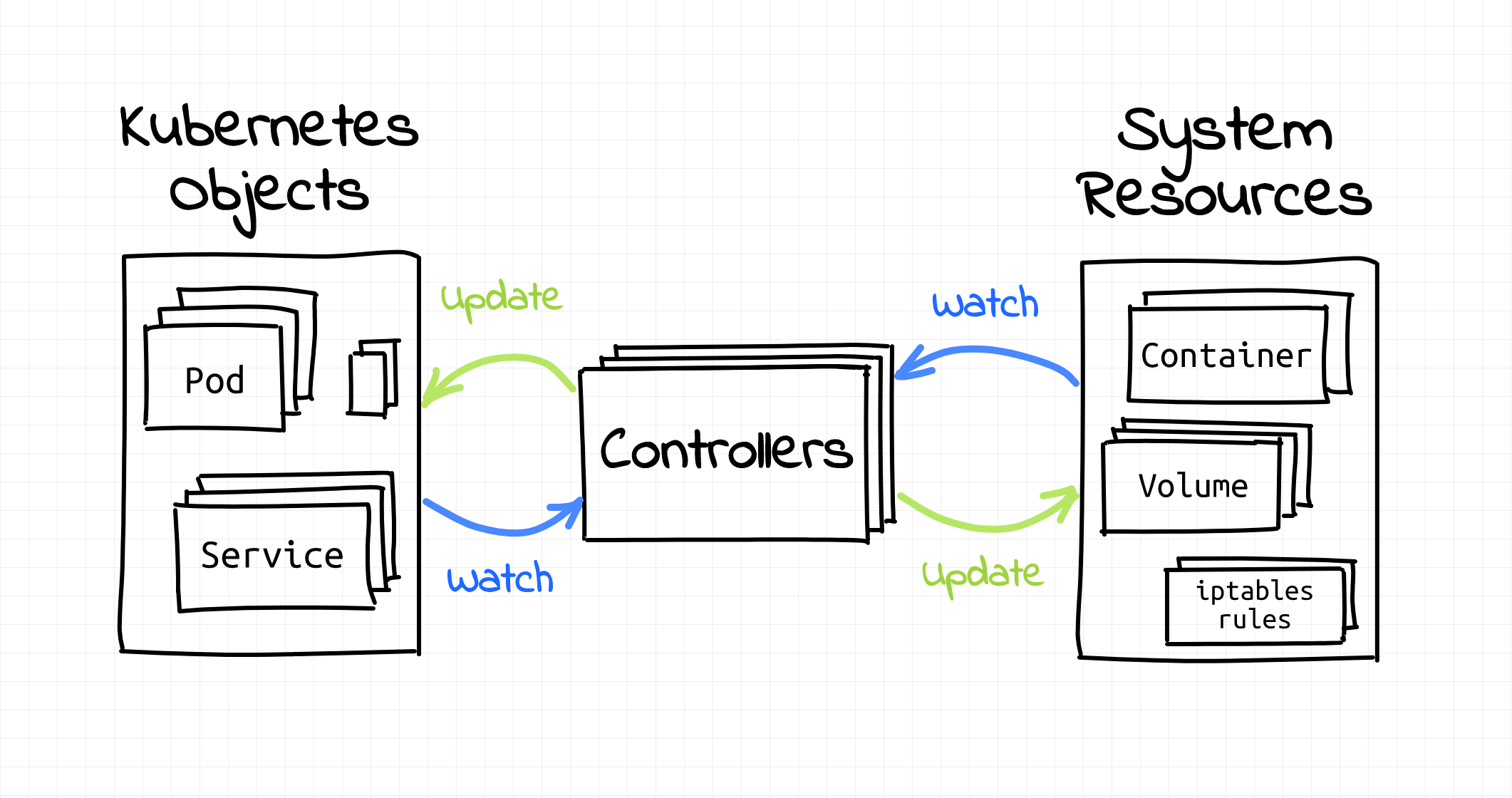
Kubernetes control loop pattern - how operators watch and reconcile desired state
Operators follow the standard Kubernetes controller pattern but with application-specific intelligence:
┌─────────────────────────┐
│ Custom Resource │ ←── User defines desired state
│ (PostgreSQL CRD) │
└─────────────────────────┘
│
▼
┌─────────────────────────┐
│ Controller Manager │ ←── Watches for changes
│ (PostgreSQL Operator) │
└─────────────────────────┘
│
▼
┌─────────────────────────┐
│ Kubernetes API │ ←── Creates/updates resources
│ (pods, services) │
└─────────────────────────┘
The Control Loop runs every 10-30 seconds and basically:
- Checks what you said you wanted
- Looks at what you actually have
- Tries to fix the difference (usually fails on the first try)
- Updates status so you know it's trying
This continuous reconciliation means your applications self-heal and automatically adapt to changes.
Framework Evolution: Making Operator Development Accessible
Modern Operator Development Tools
The latest Operator SDK actually works now, most of the time.
What you get:
- Go, Ansible, and Helm support: Pick your poison (Go is fastest, Ansible is slowest)
- Testing that works: New E2E testing with Kind clusters that don't randomly fail
- Less broken scaffolding: Generated code that compiles on the first try
Getting Started Is Actually Easier Now
The tooling stopped sucking sometime around 2023:
- Scaffolding tools: Generate complete Operator projects in minutes
- Code generation: Automatic client code and API boilerplate
- Testing frameworks: Unit and integration test scaffolding
- Deployment automation: OLM integration (when it works)
Reality check: A basic "hello world" Operator takes a few hours. A production-ready operator that doesn't fuck up your cluster? 3-6 months if you're lucky.
You're still writing code that breaks, but at least operators tell you why instead of just dying silently like shell scripts.

