The Kubernetes Cluster Autoscaler is an open-source component that automatically adjusts the size of a Kubernetes cluster based on workload demands. As of late 2025, we're running 1.32.x in production - don't use bleeding edge unless you enjoy debugging at 3am. This version includes DRA support improvements, parallelized cluster snapshots, and the default expander changed to least-waste (which actually works better than random, shocking).
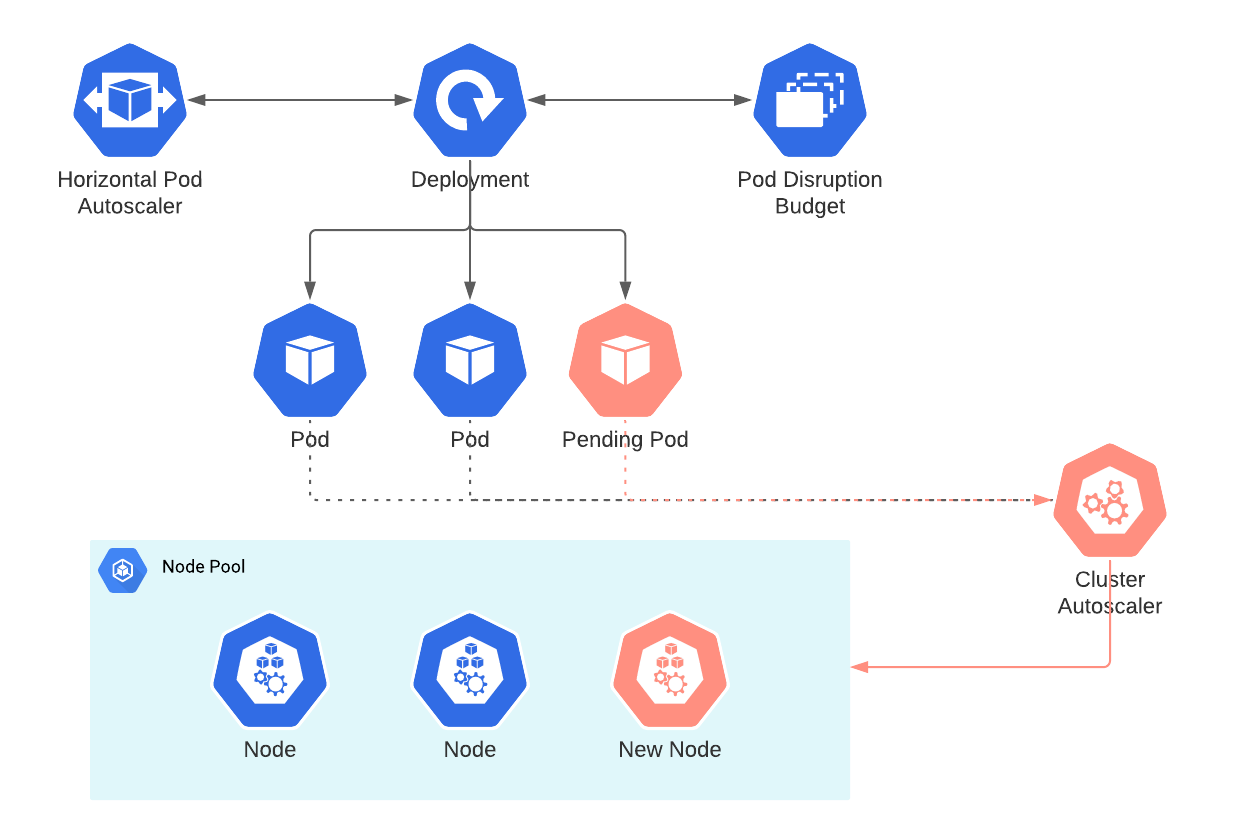
Maintained by SIG Autoscaling, this thing watches for pods that can't get scheduled and spins up nodes. When nodes sit empty burning money, it kills them. Simple concept, complex execution that will make you question your life choices.
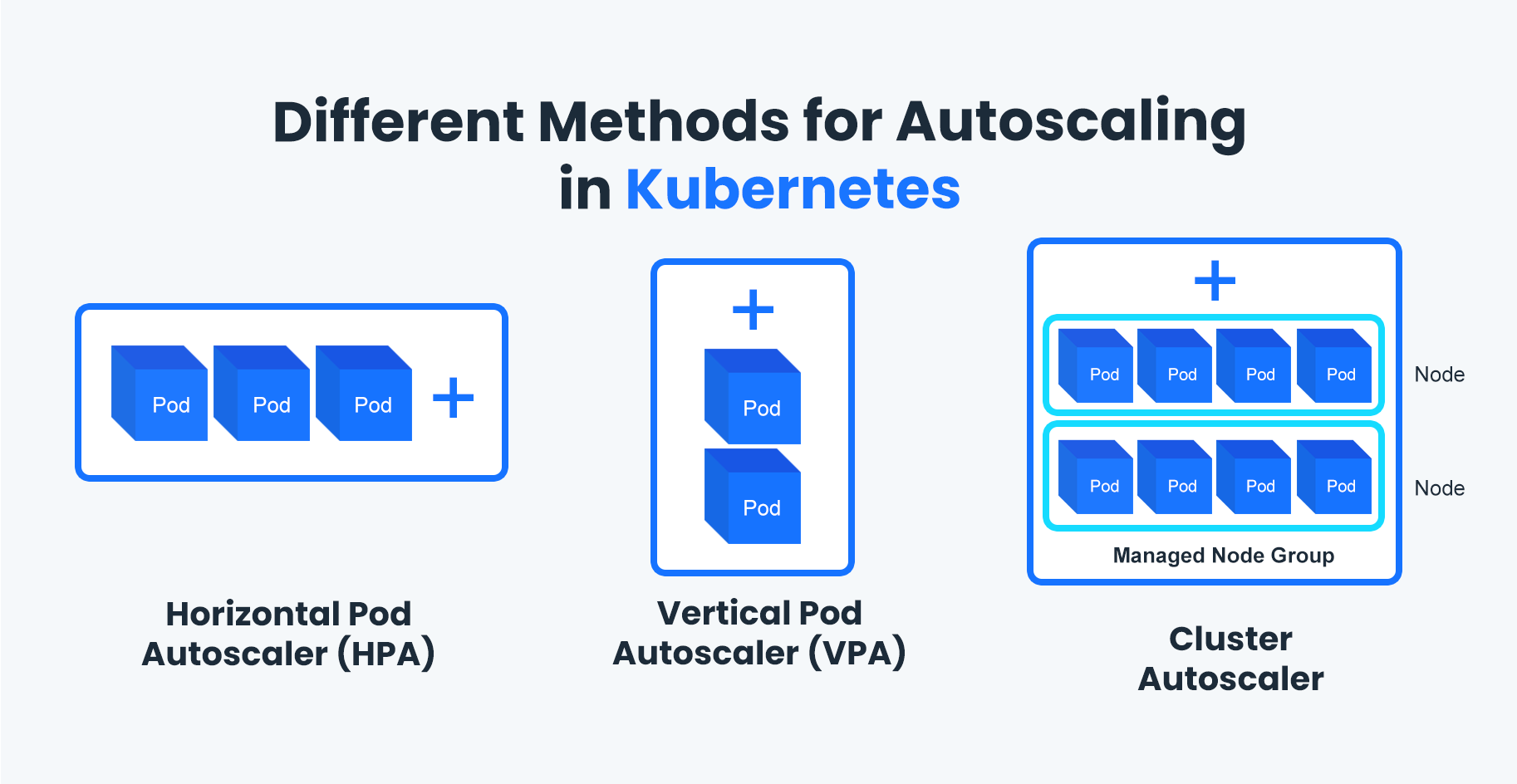
Your clusters are either burning money on empty nodes or failing to schedule pods when you actually need capacity. There's no middle ground. Manual scaling means paying someone to watch dashboards 24/7 and make capacity decisions. Static provisioning means either over-provisioning (expensive) or under-provisioning (downtime). The autoscaler attempts to thread this needle automatically.
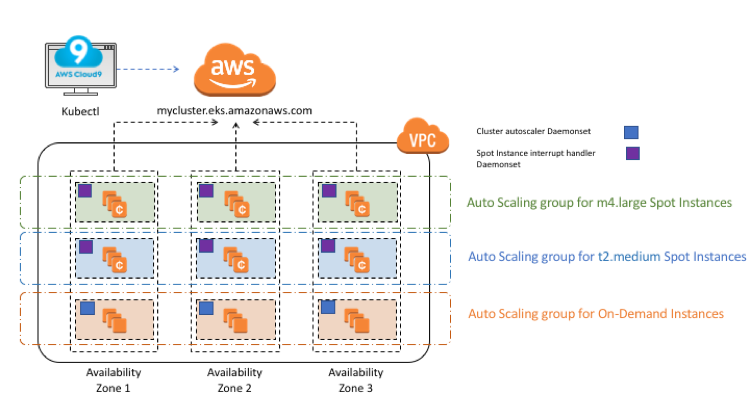
It talks to AWS, GCP, or Azure APIs to spin up and terminate instances. The "simulation" sounds impressive until you figure out it's just checking if your pod requirements match available node types before actually doing anything. Works great until your spot instances disappear mid-scale.
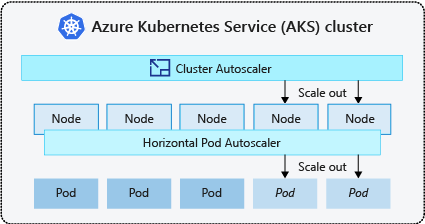
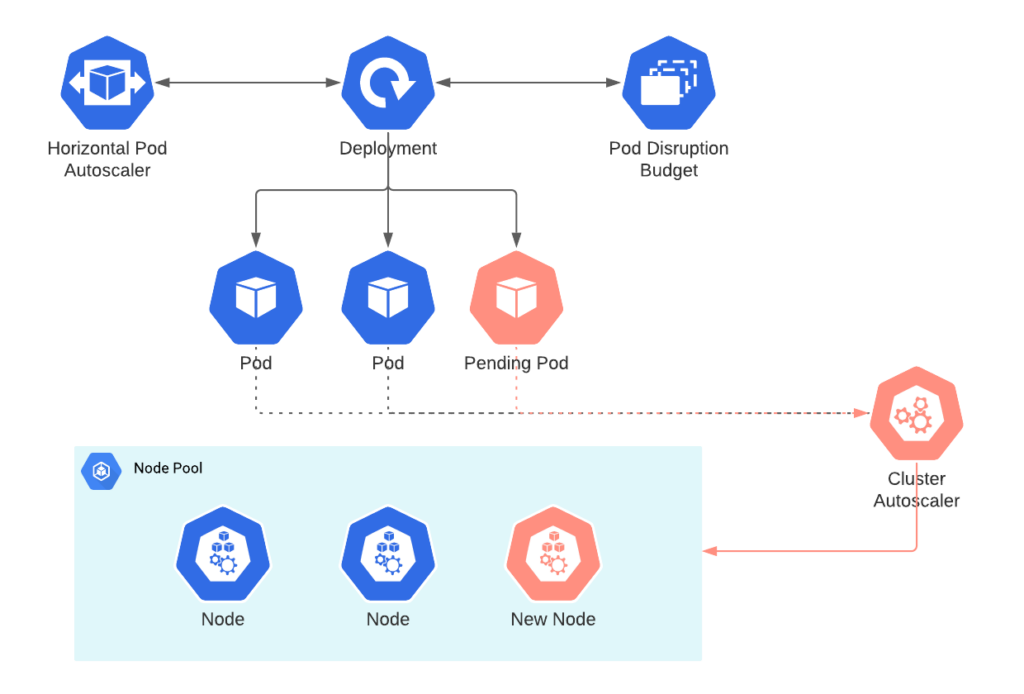
How This Thing Actually Works
You have to pre-configure every fucking node type you might want through node groups. It can't just create the perfect instance for your workload - you're stuck manually configuring every possible server combo you might need. Each node group maps to cloud constructs like AWS ASGs, GCP instance groups, or Azure VM Scale Sets.
Every 10 seconds this thing checks for stuck pods and decides whether to burn more money on new nodes. It scales on what pods ask for, not what they actually use, so a pod requesting 4 CPU cores but using 200m still triggers massive scale-ups. Get your resource requests wrong and you're fucked.
What Actually Breaks (And Will Ruin Your Weekend)
Scaling Takes Forever: AWS says 2-5 minutes but I've waited 12 minutes for a single t3.medium during a fucking Tuesday afternoon. GCP is faster but fails weirder. Scale-down takes 30+ minutes because it's terrified of killing anything important.
API Rate Limits: Hit AWS scaling limits during traffic spikes? Your autoscaler just stops working while your app melts down. The error just says "failed to update" - thanks AWS, real useful.
Spot Instance Chaos: Your "cost-optimized" spot instances disappear during Black Friday, leaving pods stuck pending while the autoscaler tries to replace nodes that no longer exist. We learned this the hard way.
The Node Group Configuration Hell: Miss one instance type configuration and watch pods sit pending because the autoscaler can't provision the right resources. GPU workloads are especially brutal - you need separate node groups for every GPU type.
This is why I use Karpenter now - got tired of waiting 7+ minutes for nodes. Here's how it compares to alternatives so you can pick your poison.