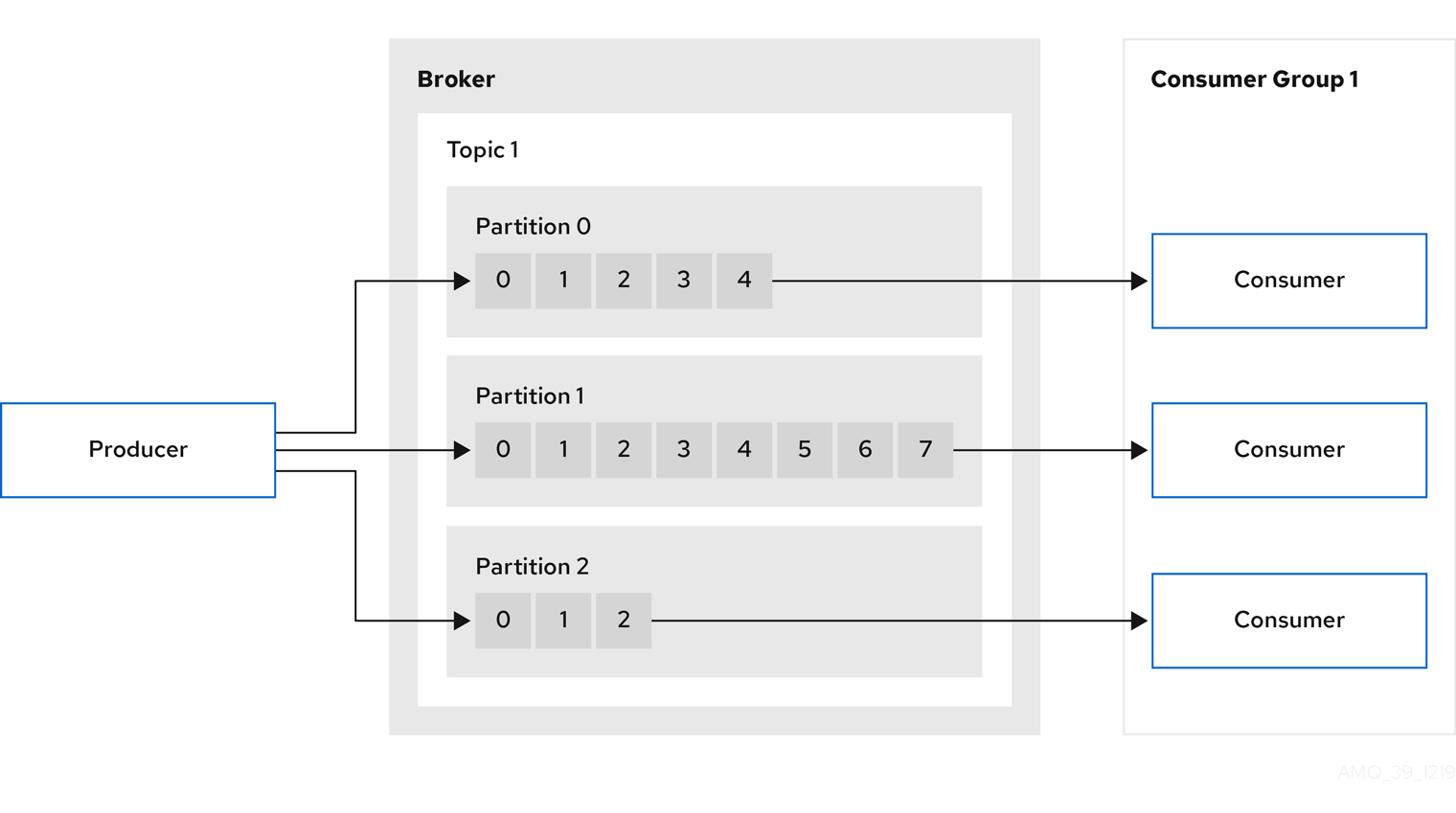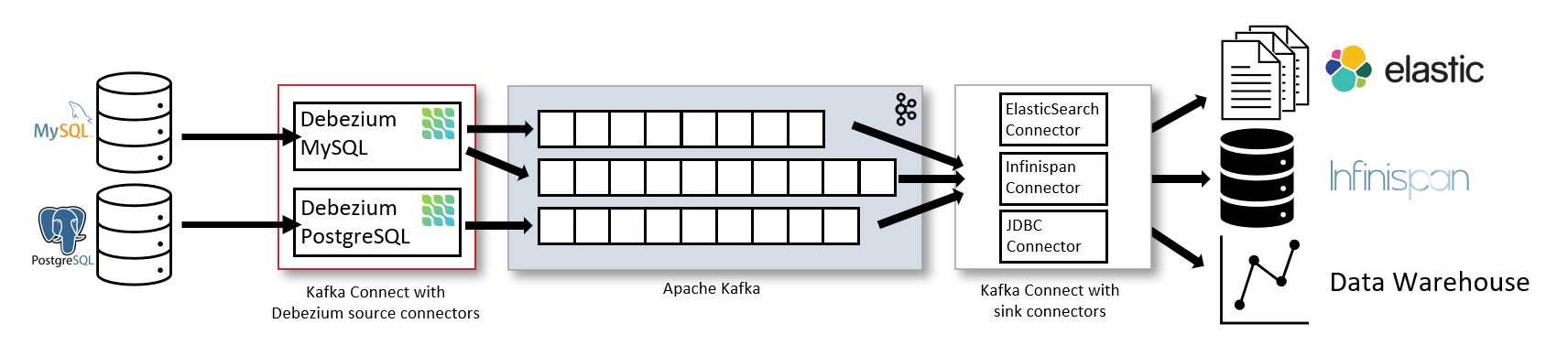
I've set up CDC at three different companies. Every single time, vendor demos were complete bullshit and nothing worked like they promised. Got paged at 2am during Black Friday when our Kafka cluster shit the bed - here's what I learned.
Getting CDC Running in Kubernetes Without Losing Your Mind
Traditional CDC assumes dedicated servers and that you enjoy pain. Everything runs in Kubernetes now because Docker networking makes me want to quit tech, but it beats managing bare metal.
The Architecture That Actually Works
This Strimzi operator approach handles the complex Kubernetes integration that breaks most DIY Kafka deployments:
## Production-ready CDC deployment with Strimzi Operator
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
name: cdc-cluster
namespace: cdc-production
spec:
kafka:
version: 3.7.0 # whatever was stable when I set this up
replicas: 3
listeners:
- name: plain
port: 9092
type: internal
tls: false
config:
offsets.topic.replication.factor: 3
default.replication.factor: 3
min.insync.replicas: 2
storage:
type: persistent-claim
size: 500Gi # way more than we needed but storage is cheap
class: fast-ssd
zookeeper:
replicas: 3
storage:
type: persistent-claim
size: 100Gi
class: fast-ssd
entityOperator:
topicOperator: {}
userOperator: {}
Copied this from some blog and it worked for like two days. Then Kafka started dying on every restart because the persistent volumes weren't configured right. Lost half a day's worth of events. Fucking persistent storage in Kubernetes.
The Database Connection Reality
## Debezium connector with connection tuning that actually works
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaConnector
metadata:
name: postgres-cdc-connector
labels:
strimzi.io/cluster: connect-cluster
spec:
class: io.debezium.connector.postgresql.PostgresConnector
tasksMax: 4
config:
database.hostname: postgres-primary.production.svc.cluster.local
database.port: 5432
database.user: cdc_user
database.password: ${secret:postgres-credentials:password}
database.dbname: production
database.server.name: production-server
# Timeout because connections hang forever otherwise
database.connectionTimeoutInMs: 30000
# WAL settings so your disk doesn't fill up
slot.name: debezium_production
plugin.name: pgoutput
# Only replicate tables you actually need
table.include.list: "public.users,public.orders,public.payments"
# Hash PII or compliance will murder you
transforms: mask_pii
transforms.mask_pii.type: io.debezium.transforms.HashField$Value
transforms.mask_pii.fields: email,phone_number
Schema changes broke our connector and nobody noticed for hours. The table filter is there because we replicated some internal postgres tables by accident and filled up Kafka with useless crap.
Event-Driven Architecture Integration Patterns
The Outbox Pattern That Doesn't Fall Over
Most outbox examples are toys that break under real load. This version survived our Black Friday traffic and handles the transaction failures that will definitely happen:
-- Outbox table with proper indexing and retention
CREATE TABLE outbox (
id BIGSERIAL PRIMARY KEY,
aggregate_type VARCHAR(255) NOT NULL,
aggregate_id VARCHAR(255) NOT NULL,
event_type VARCHAR(255) NOT NULL,
payload JSONB NOT NULL,
created_at TIMESTAMP NOT NULL DEFAULT NOW(),
processed_at TIMESTAMP,
version INTEGER NOT NULL DEFAULT 1
);
-- Critical indexes for performance
CREATE INDEX idx_outbox_unprocessed ON outbox(created_at) WHERE processed_at IS NULL;
CREATE INDEX idx_outbox_aggregate ON outbox(aggregate_type, aggregate_id, version);
CREATE INDEX idx_outbox_cleanup ON outbox(created_at) WHERE processed_at IS NOT NULL;
-- Automatic cleanup to prevent table bloat
CREATE OR REPLACE FUNCTION cleanup_outbox()
RETURNS void AS $$
BEGIN
DELETE FROM outbox
WHERE processed_at < NOW() - INTERVAL '7 days';
END;
$$ LANGUAGE plpgsql;
-- Application code pattern
BEGIN;
-- Business logic update
UPDATE users SET email = 'new@email.com' WHERE id = 12345;
-- Outbox event
INSERT INTO outbox (aggregate_type, aggregate_id, event_type, payload)
VALUES ('User', '12345', 'EmailChanged',
'{"userId": 12345, "oldEmail": "old@email.com", "newEmail": "new@email.com"}');
COMMIT;
Forgot the cleanup function and the outbox table ate up like 40GB of disk space. Checkout started timing out randomly and it took us way too long to realize what was happening. Don't skip the cleanup.
Microservices Event Choreography
## Service A publishes order events via CDC
apiVersion: apps/v1
kind: Deployment
metadata:
name: order-service
spec:
template:
spec:
containers:
- name: order-service
env:
- name: KAFKA_BOOTSTRAP_SERVERS
value: "cdc-cluster-kafka-bootstrap:9092"
- name: OUTBOX_TOPIC
value: "orders.outbox"
---
## Service B consumes events and maintains its view
apiVersion: apps/v1
kind: Deployment
metadata:
name: inventory-service
spec:
template:
spec:
containers:
- name: inventory-service
env:
- name: KAFKA_CONSUMER_GROUP
value: "inventory-consumer"
- name: ORDER_EVENTS_TOPIC
value: "production-server.public.outbox"
Key insight from Brex's CDC setup: use CDC for views, not triggers. Found this out when our order service started calling inventory synchronously and killed half the platform during a traffic spike. Don't be me.
Hybrid Cloud and Multi-Environment Patterns

The Hub-and-Spoke Pattern for Compliance
Enterprise CDC across environments with compliance bullshit is painful. Estuary's hybrid approach shows how to do this without going insane:
## Control plane in cloud for management
apiVersion: v1
kind: ConfigMap
metadata:
name: cdc-control-plane-config
data:
environments: |
production:
region: us-east-1
compliance: sox,pci
data_residency: us
europe:
region: eu-central-1
compliance: gdpr
data_residency: eu
development:
region: us-west-2
compliance: none
data_residency: us
---
## Data plane components run locally
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: cdc-data-plane
spec:
template:
spec:
containers:
- name: cdc-agent
env:
- name: CONTROL_PLANE_URL
value: "https://cdc-control.company.com"
- name: ENVIRONMENT
valueFrom:
fieldRef:
fieldPath: metadata.labels['environment']
- name: COMPLIANCE_MODE
valueFrom:
configMapKeyRef:
name: cdc-control-plane-config
key: compliance
Manage CDC globally, process locally for compliance. Critical unless you enjoy GDPR fines and angry compliance teams.
Cross-Region Replication Without Tears
## Primary region CDC setup
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaMirrorMaker2
metadata:
name: cross-region-mirror
spec:
version: 3.7.0
replicas: 2
connectCluster: "target-connect-cluster"
clusters:
- alias: "source"
bootstrapServers: source-kafka:9092
- alias: "target"
bootstrapServers: target-kafka:9092
mirrors:
- sourceCluster: "source"
targetCluster: "target"
sourceConnector:
config:
replication.factor: 3
offset-syncs.topic.replication.factor: 3
sync.topic.acls.enabled: "false" # enable this in prod
heartbeatConnector: {}
checkpointConnector: {}
topicsPattern: "production-server\..*"
groupsPattern: ".*"
Cross-region replication works fine until the network goes to shit. Then you find out your failover doesn't actually work. Test your disaster recovery - seriously.
Security and Compliance Integration Patterns
Locking Down CDC So Security Doesn't Murder You
## Network policies for CDC components
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: cdc-security-policy
spec:
podSelector:
matchLabels:
app: cdc
policyTypes:
- Ingress
- Egress
ingress:
- from:
- podSelector:
matchLabels:
app: cdc-consumer
ports:
- protocol: TCP
port: 9092
egress:
- to:
- podSelector:
matchLabels:
app: postgres
ports:
- protocol: TCP
port: 5432
- to: []
ports:
- protocol: TCP
port: 443 # HTTPS for external calls
---
## Pod security standards
apiVersion: v1
kind: Pod
metadata:
name: cdc-connector
spec:
securityContext:
runAsNonRoot: true
runAsUser: 10001
fsGroup: 10001
seccompProfile:
type: RuntimeDefault
containers:
- name: debezium
securityContext:
allowPrivilegeEscalation: false
readOnlyRootFilesystem: true
capabilities:
drop:
- ALL
Network policies and security contexts prevent CDC from accessing shit it shouldn't. Usually passes security audits.
GDPR Compliance Before They Sue You
-- Data classification at source
CREATE TABLE users (
id SERIAL PRIMARY KEY,
email VARCHAR(255) NOT NULL,
name VARCHAR(255) NOT NULL,
-- PII classification for CDC processing
pii_classification JSONB DEFAULT '{
"email": {"type": "PII", "retention": "7_years", "encrypt": true},
"name": {"type": "PII", "retention": "7_years", "encrypt": true}
}'::jsonb
);
-- Automated data masking function
CREATE OR REPLACE FUNCTION mask_for_environment()
RETURNS TRIGGER AS $$
BEGIN
-- Mask PII in non-production environments
IF current_setting('app.environment', true) != 'production' THEN
NEW.email = regexp_replace(NEW.email, '(.{2}).*(@.*)', '\1***\2');
NEW.name = left(NEW.name, 2) || repeat('*', length(NEW.name) - 2);
END IF;
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
CREATE TRIGGER mask_pii_trigger
BEFORE INSERT OR UPDATE ON users
FOR EACH ROW
EXECUTE FUNCTION mask_for_environment();
Mask PII before CDC grabs it or GDPR will fuck you up. Can't have customer emails showing up in dev environments.
Common Production Gotchas That Will Ruin Your Day
When MySQL binlog gets corrupted: io.debezium.DebeziumException: Failed to parse binlog event - reset connector offset and accept data loss. No other option.
When connector dies on bad data: org.apache.kafka.connect.errors.ConnectException: Tolerance exceeded - set errors.tolerance=all because perfect data doesn't exist.
Fun fact: PostgreSQL tables with capital letters will silently break CDC. Spent 6 hours debugging this shit.
Debezium eating 100% CPU? Restart it. No idea why this works but it does. We cron this now.
Production will find creative new ways to break CDC. That's just how it goes.