

Longhorn is basically distributed storage that doesn't make you want to quit your job. Built by Rancher Labs and now maintained by SUSE, it's a CNCF Incubating project that actually works without requiring a PhD in distributed systems.
Instead of setting up a separate storage cluster (which is a pain in the ass), Longhorn just uses the disks you already have on your Kubernetes nodes. Each volume gets its own dedicated storage engine, and it replicates your data across multiple nodes so when hardware inevitably dies, your data doesn't.
I've been running this in production for 8 months. It's survived two node failures, one kernel panic, and me accidentally deleting a namespace. The replica rebuilds took forever, but nothing broke.
What Actually Works
It Doesn't Break Everything When One Thing Breaks: Each volume runs its own dedicated storage engine instead of sharing one giant clusterfuck like Ceph. When something goes wrong, it's usually just that one volume, not your entire storage system. I learned this the hard way when our old Ceph cluster took down prod for 2 hours because one OSD went sideways.
Snapshots That Don't Suck: Point-in-time snapshots actually work and don't eat all your disk space. They're incremental, so you're not storing 50 copies of the same data. Saved my ass when someone deployed code that corrupted a database - rolled back to 30 minutes before and called it a day.
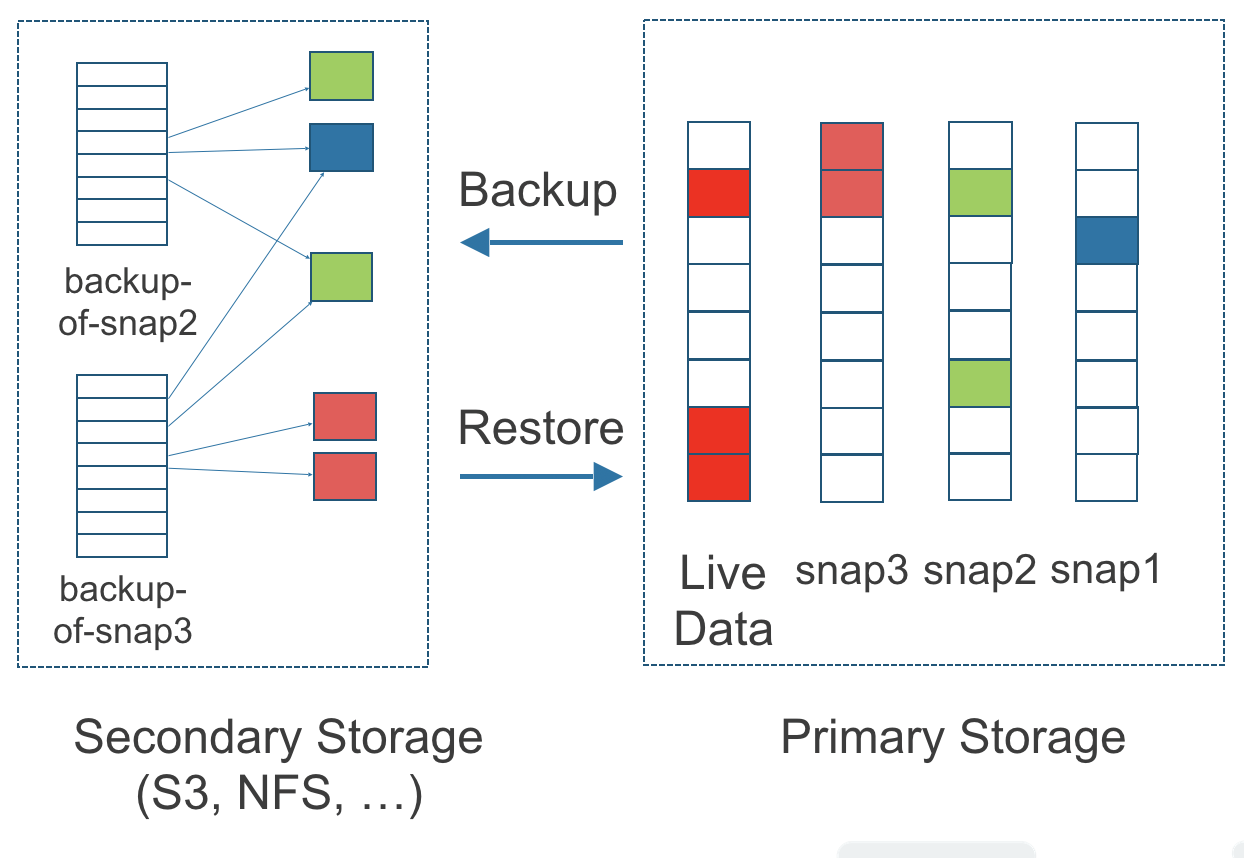
Backups to Real Storage: Backs up to S3 or NFS, not some proprietary bullshit. We send ours to an S3 bucket and can restore to a completely different cluster. Tested this during our DC migration - worked flawlessly, though it took 4 hours to restore 200GB because S3 egress is what it is.
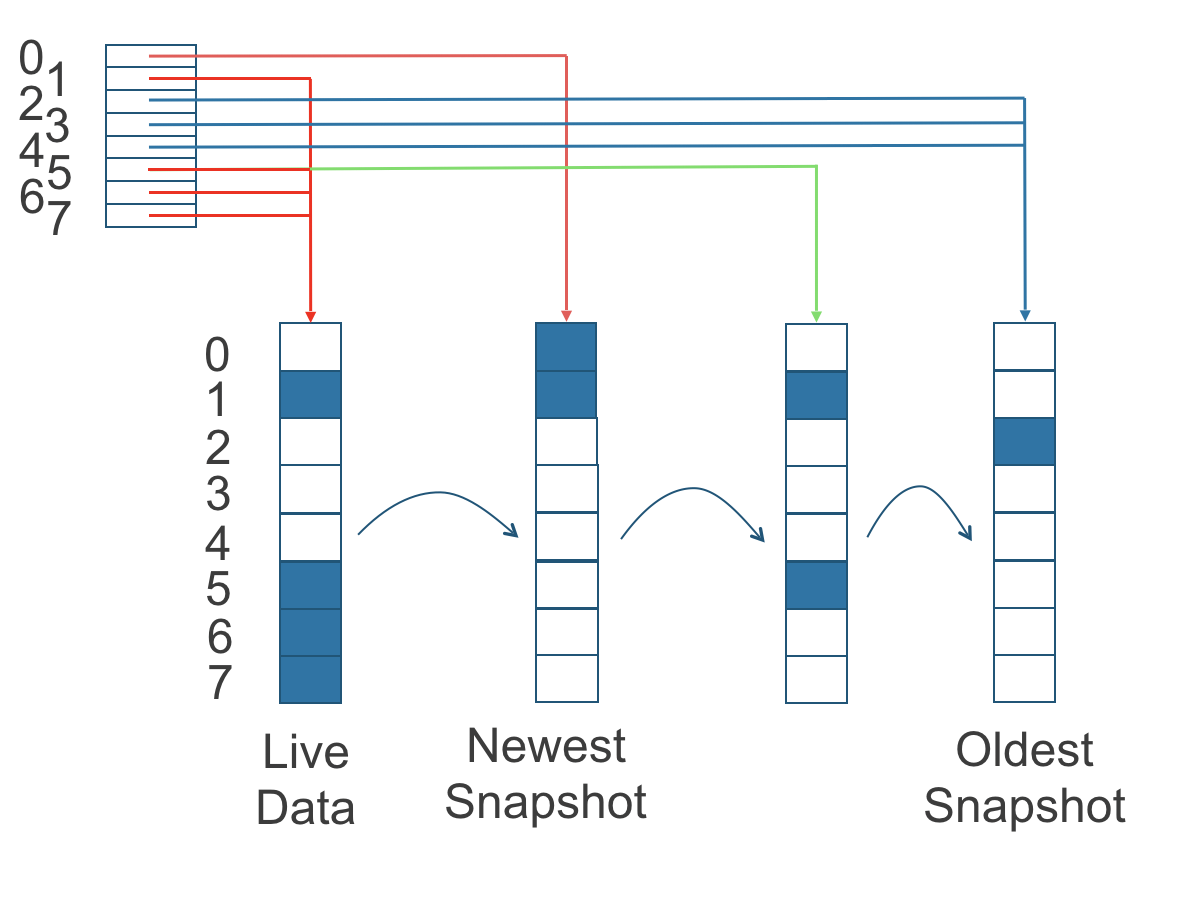
Thin Provisioning: Only uses the disk space you're actually consuming. A 20GB volume with 1GB of data uses 1GB on disk. This is standard now, but worth mentioning because some legacy storage systems are still stupid about this.
UI That Doesn't Suck: The Longhorn dashboard is actually usable. You can see your volumes, check replica status, and trigger backups without memorizing kubectl commands. Gets slow with 50+ volumes, but still better than debugging Ceph through cryptic CLI tools.
How This Thing Actually Works
Longhorn splits things into two parts: the storage engines that handle your data, and the managers that orchestrate everything. The Longhorn Manager runs on every node as a DaemonSet, which means it's always there watching things. When you create a volume, it spins up a dedicated storage engine just for that volume.
It hooks into Kubernetes through CSI, so your apps just use regular PersistentVolumeClaims. No special APIs or modifications needed - if your app works with standard Kubernetes storage, it works with Longhorn.
Current Status: Longhorn v1.9.1 came out on July 23, 2025 and is stable as of September 2025. The offline replica rebuilding is actually useful - means you can fix broken replicas without tanking your application's performance. They release new versions every 4 months, which is fast enough to get fixes but not so fast you're constantly upgrading.
Real Performance Numbers: In production with SSDs, we see 4,000-6,000 IOPS for random 4K reads and about 60% of that for writes. Latency stays under 10ms for most operations. With HDDs, cut those numbers in half and add some prayer.
Tribal Knowledge from 8 Months in Production:
- Always check
kubectl get volumeattachmentswhen pods won't start - sometimes they get stuck - If replica rebuilds take forever, check your network - we had a flaky switch port causing 30% packet loss
- The "Unknown" volume state usually means networking issues or a dead node - restart the manager pod first
- Backup restoration can timeout on slow S3 connections - increase the timeout in advanced settings or you'll be debugging for hours
- Never delete all replicas of a volume at once - learned this the hard way, took 6 hours to recover from backups
Bottom Line: Longhorn isn't revolutionary, but it works without making you want to change careers. If you need storage that's reliable, simple to manage, and won't keep you up at night debugging weird edge cases, it's your best bet. The day-to-day operational experience is smooth enough that you'll forget it's there - which is exactly what you want from infrastructure.