
HNSW indexing is a fucking memory nightmare. The docs say "scalable" but what they mean is "scalable if you have infinite RAM." Going from 1M to 10M vectors doesn't just need 10x more memory—it needs like 25-30x because of all the graph structures, caches, and metadata bullshit that nobody mentions until you're already screwed.
The HNSW Index Memory Trap
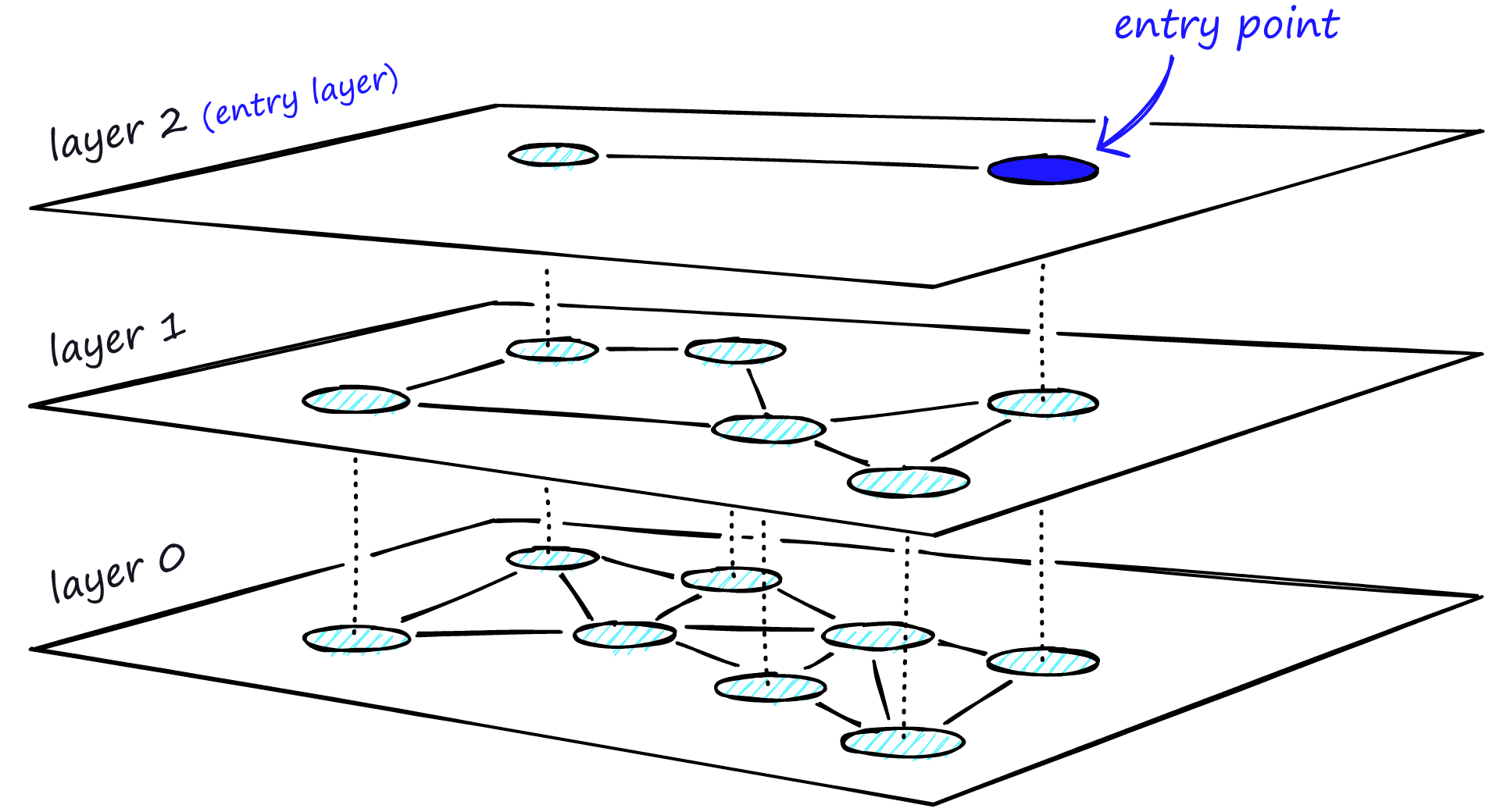
Here's the brutal reality about HNSW that nobody tells you upfront: it's a memory-hungry beast that scales like absolute shit. Your 64GB of vectors? That actually needs 88GB+ just for the search operations. And that's before all the other bullshit.
HNSW indexing is brutal on memory. I found this out the hard way when Qdrant's docs finally admitted memory overhead hits 200-300% for high-dimensional data. Even PostgreSQL with pgvector eats 25-40% of your RAM just for buffer pools. The memory trap is real.
How badly will it fuck you? Here's the real numbers:
- 10M vectors (768-dim): 6GB of data needs way more RAM than you'd think - like 20-40GB when the data is only 6GB. Redis will murder your memory budget.
- 100M vectors: 60GB becomes like 200-400GB RAM requirement. Hello $14.7K/month AWS bills and "failed to allocate memory" errors in your logs.
- 1B vectors: 600GB data needs like 2-4TB RAM. Good luck finding hardware that doesn't bankrupt you - most clouds cap out at 24TB instances that cost over $30K monthly.
Index Rebuilds: The 3AM Nightmare That Breaks Everything
Index rebuilds are when this shit gets real. The system decides it needs to reorganize everything, and suddenly your memory usage spikes to 5x normal. No warning, no gradual increase—just boom, your instances are out of memory.
Google's Spanner docs try to sugarcoat it as "zero-downtime" but you need double the memory. CockroachDB flat out says rebuilds are "time-consuming and expensive." The production reality requires dedicated maintenance windows because shit will break.
Had a client whose AWS bill was like $180K or something insane - I don't remember the exact number but it was brutal - took them two weeks to recover because nobody understood why the rebuild kept failing. Think it happened over Christmas break because that's always when this stuff breaks. Rebuild would start, hit some memory limit nobody saw coming, crash out after 8 hours, and they'd have to start over. Did this maybe three or four times before they figured out they needed to basically double their instance sizes just to get through the fucking rebuild.
Multi-Tenant Hell: When Everything Gets Worse
Multi-tenant deployments are where vector databases really screw you. Each tenant needs its own everything, no sharing allowed:
- Separate indexes: No memory sharing because "security"
- Individual caches: Every tenant gets their own cache that eats more RAM
- Connection pools: Each connection is more memory overhead
- Backup bullshit: Point-in-time snapshots during business hours
One financial services team thought they had 500GB of data. Turns out they were using like 1.2TB of actual memory or something insane across three zones. Multi-tenant overhead was like 60% of their total usage. Found this out at 4am when everything started throwing "memory allocation failed" errors and their compliance dashboard went dark. Nobody warned them about that shit.
The AWS Bill That Made My CFO Cry

Memory scaling hits you from every angle:
Premium Instance Tax: Vector workloads need memory-optimized instances that cost 40-60% more than normal. AWS r6i.24xlarge with 768GB RAM? That's $4,355 per month per node - but you'll need 3-4 of these for any real production setup, so now you're looking at over $15K monthly just for compute. Each fucking node.
Multi-Region Multiplication: Need availability? Your costs triple across regions. Cross-region replication adds another $2K-5K monthly in data transfer fees. Because of course it does.
Dev/Test Environment Hell: You can't use small instances for testing vector workloads. They need the same memory as production. So your testing environments double or triple your infrastructure costs.
Do the math: 500GB RAM in production becomes like $58K+ monthly when you add multi-region, dev environments, and AWS's premium pricing. That's before you hire the team to manage this memory-intensive nightmare and deal with 3am outages.

