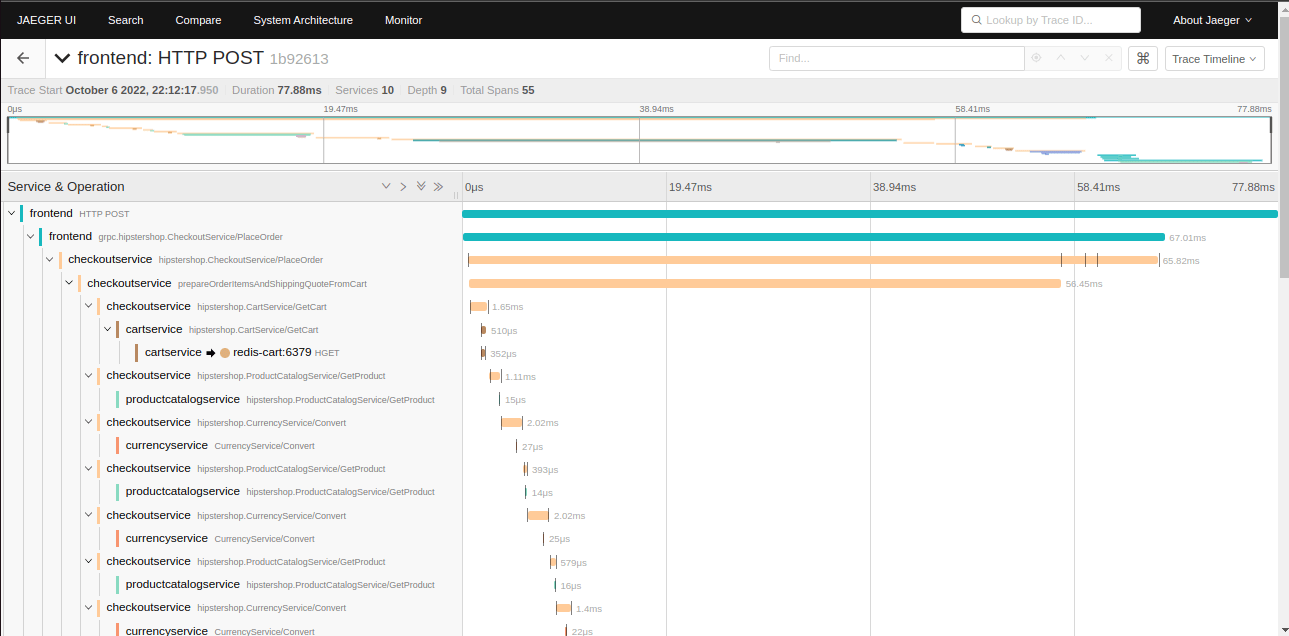
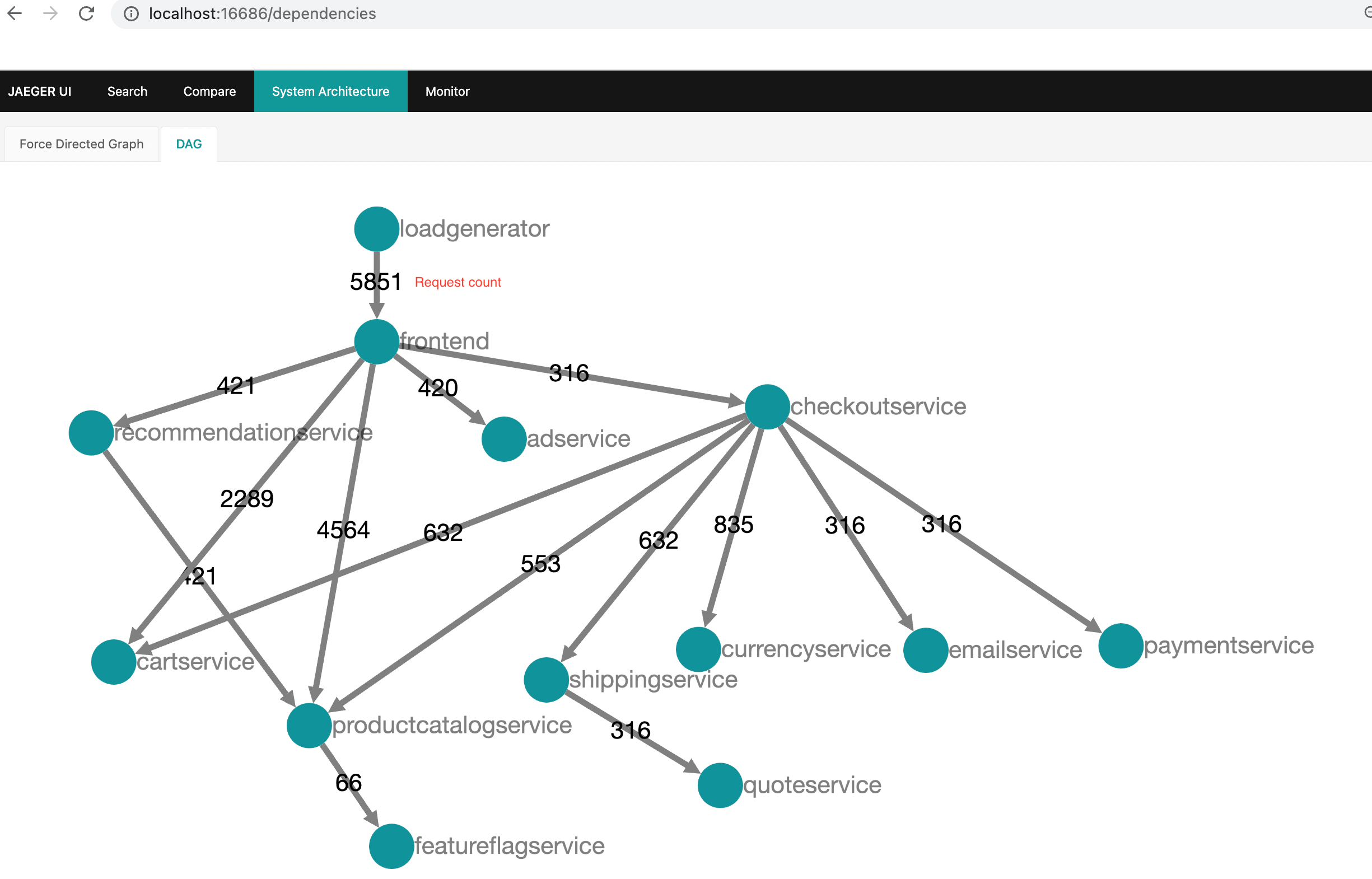
I'll never forget the night our entire tracing stack disappeared during some big sales day - I think it was Black Friday? Payment transactions were timing out, customer support was screaming, and every trace just... ended at the API gateway. No downstream spans, no database calls, nothing. Turns out someone deployed a "minor" Kubernetes update that broke our OpenTelemetry context headers. Cost us a shit-ton of money before we figured it out.
This is the reality of distributed tracing in production - it's not the clean, academic examples from the docs. It's messy, breaks in weird ways, and usually fails when you need it most. Every engineering team I know has had tracing break during incidents. It's not if, it's when.
The Real Ways Traces Break (Not the Textbook Version)
Context Headers Just Fucking Disappear
Most trace failures happen because services don't forward the magic headers that keep traces connected. Here's what actually happens:
Load balancers strip headers: Your F5 or AWS ALB is probably configured to drop "unknown" headers like traceparent. I spent 6 hours debugging this once because our network team thought trace headers were "security risks." The Kubernetes tracing best practices guide covers these networking gotchas in detail. The AWS ALB documentation explains header forwarding configuration, and NGINX's tracing setup guide shows how to properly configure proxies for trace propagation.
Proxy misconfigurations: If you're using Envoy or nginx, check your header forwarding rules. Istio 1.8.0 had a bug where it silently dropped trace context on certain HTTP methods. GitHub issue #31847 if you want the gory details. The CNCF distributed tracing guide has more context propagation failures. Envoy's tracing documentation and the OpenTelemetry Istio setup guide cover service mesh tracing issues in depth.
Third-party APIs don't give a shit: Stripe, PayPal, and most external services won't forward your trace headers. Your beautiful end-to-end trace becomes Swiss cheese the moment you hit an external API. This is a well-documented limitation in distributed tracing architectures, and Honeycomb's observability guide explains the workarounds. The W3C Trace Context specification defines how headers should propagate, and DataDog's tracing best practices covers dealing with external service boundaries.
## This is what you actually run when debugging missing headers:
kubectl exec -it api-gateway -- curl -H \"traceparent: 00-4bf92f3577b34da6a3ce929d0e0e4736-00f067aa0ba902b7-01\" \
-v payment-service:8080/charge
## Look for the traceparent header in the response - if it's missing, you found your problem
Sampling Kills the Traces You Actually Need
Head-based sampling is a trap. It decides whether to trace a request before anything interesting happens. So when your payment processing shits the bed, guess what? The sampler already decided that request wasn't worth tracing because it "looked normal" at the entry point. Industry best practices recommend tail-based sampling for critical systems, and Coralogix's OpenTelemetry guide explains the sampling strategies in depth. The OpenTelemetry sampling documentation covers different approaches, and Grafana's distributed tracing best practices provide production-tested configurations.
I learned this during a production incident where we were dropping most of our traces. The one critical payment failure that was costing us money? Not sampled. Spent 3 hours debugging with logs instead of traces because our sampling decided to preserve successful health checks instead of actual errors. The Last9 tracing guide covers these sampling pitfalls with real-world examples. New Relic's sampling strategies guide and Splunk's OpenTelemetry collector guide show how to implement intelligent sampling.
Tail-based sampling is better but harder: You need collectors with enough memory to buffer traces while deciding what to keep. Our collector was OOMKilling every few hours until we figured out the right memory limits. Cisco's Kubernetes observability guide has production-tested collector configs that actually work. The OpenTelemetry tail sampling processor documentation and Jaeger's sampling best practices explain the memory requirements and configuration options.
OpenTelemetry Collectors Are Surprisingly Fragile
The collector is supposed to be this bulletproof piece of infrastructure. In reality, it's a memory-hungry beast that falls over when you breathe on it wrong.
Memory leaks in recent versions: Don't use 0.89.0 or 0.90.x - they have memory leaks. Upgrade to 0.91.0+ or watch your collector die. The OpenTelemetry operator issues track these version-specific problems, and Lumigo's collector guide has the version compatibility matrix. Dynatrace's OpenTelemetry integration guide and the official collector deployment patterns document common issues.
Config changes require restarts: Unlike what the docs imply, most config changes need a full restart. Hot-reloading works for like 3 settings. Everything else? Kill the pod and pray. The StrongDM Kubernetes observability guide explains why collector restarts are the norm, not the exception. Kubernetes observability patterns and Prometheus monitoring for OpenTelemetry help track collector health during restarts.
## This collector config actually works in production (learned through pain):
processors:
memory_limiter:
limit_mib: 1024 # Always set this or you'll OOM
spike_limit_mib: 256
batch:
timeout: 200ms # Not 1s like the examples - too slow for real traffic
send_batch_size: 256
send_batch_max_size: 512
## Don't trust the default memory settings - they're way too low
resources:
limits:
memory: 2Gi # Minimum for any real workload
requests:
memory: 1Gi
Kubernetes Makes Everything Worse

Pod IP changes break persistent gRPC connections to collectors. Network policies silently block trace export. Resource limits cause spans to get buffered and lost during memory pressure.
The worst one: Pod restarts during high load. Your application starts up, begins accepting traffic, but the OpenTelemetry agent hasn't connected to the collector yet. First 30 seconds of traces? Gone forever. The production observability stack guide covers these startup timing issues.
Clock skew between nodes: Kubernetes doesn't guarantee clock sync. I've seen traces where child spans finish before their parents start because the nodes had some clock drift. Makes debugging impossible. This is a common Kubernetes networking issue that affects distributed tracing, documented in the Checkly Kubernetes monitoring guide.
## Check if your nodes have clock skew (they probably do):
kubectl get nodes -o wide
for node in $(kubectl get nodes -o name | cut -d/ -f2); do
echo \"Node: $node\"
kubectl debug node/$node -it --image=busybox -- date
done
## If you see more than 1 second difference, you found your timing problem
Language-Specific Gotchas That Nobody Warns You About
Java: The OpenTelemetry agent adds startup time and eats more memory. Spring Boot 2.7+ changed context propagation and broke compatibility with older OpenTelemetry versions. If you're using Spring Boot 2.7+ with OpenTelemetry, check version compatibility or you'll get weird context propagation bugs. Check the Java troubleshooting guide for JVM-specific gotchas.
Node.js: Event loop blocking during trace export. If your collector is slow or unreachable, the entire application freezes. Always use async exporters and configure timeouts. The official Node.js troubleshooting checklist and Microsoft's troubleshooting guide cover these performance issues in detail.
Python: The GIL makes everything slower when tracing is enabled. We saw noticeable performance degradation until we switched to async instrumentation. Also, Django 4.0+ breaks most tracing - you need manual instrumentation now. The HyperDX monitoring guide has Python-specific optimizations.
Go: Context propagation through goroutines is a nightmare. Half the time spans get orphaned because someone forgot to pass context. The automatic instrumentation misses database calls in 30% of cases. The DZone observability article explains context handling across languages.
This shit isn't in the documentation because the OpenTelemetry team wants you to think it "just works." It doesn't. Plan for failures, over-provision collectors, and always have a way to debug without traces.