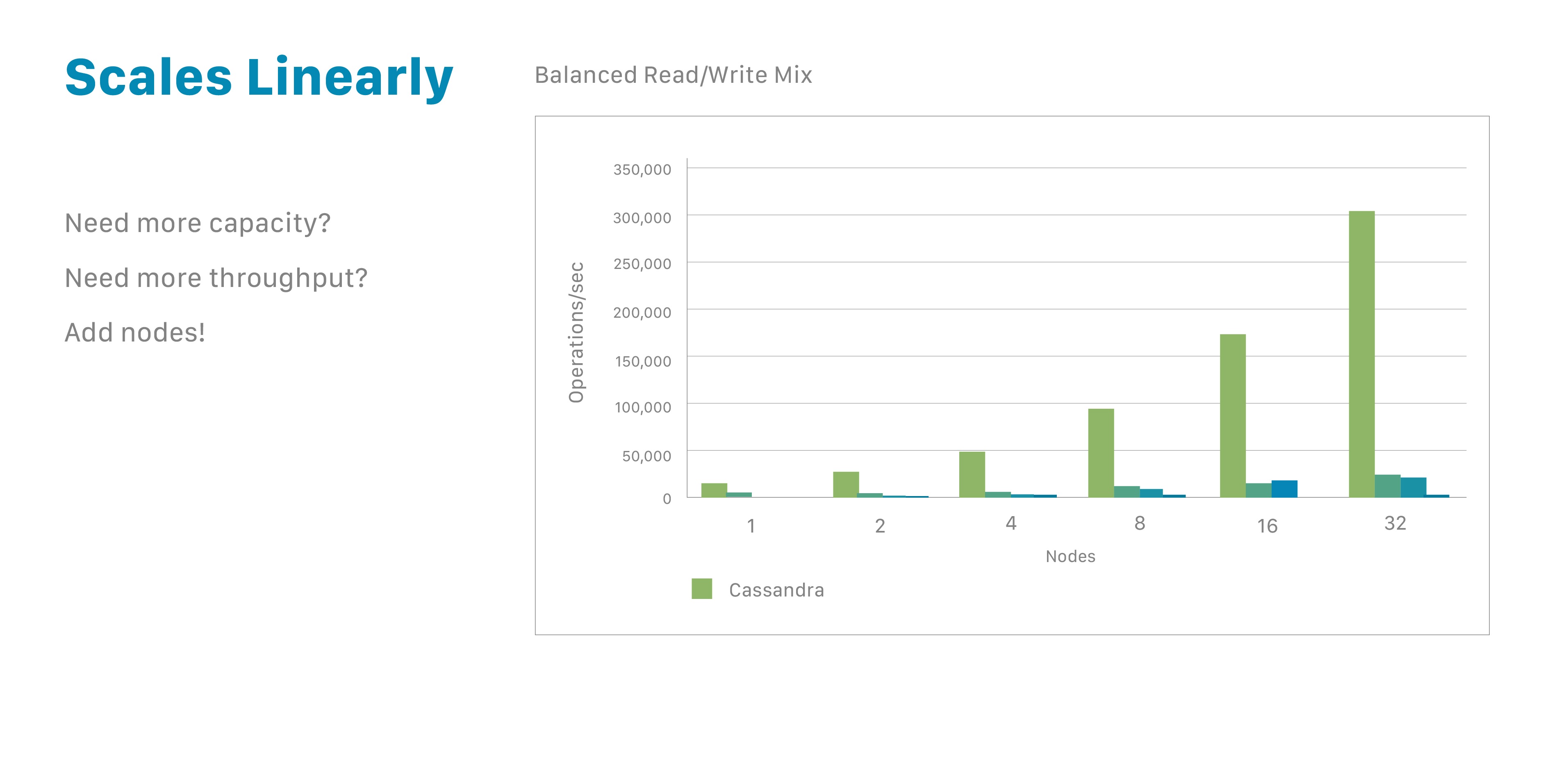
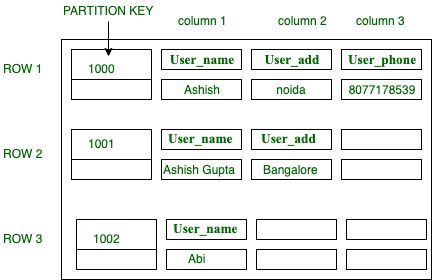
Deploying Cassandra isn't like installing PostgreSQL where you run apt install and you're done. This beast requires understanding distributed system principles or you'll break production within hours of launch.
Minimum specs that won't make you hate life:
Cassandra nodes juggle client requests, gossip protocol, compaction processes, and repair operations simultaneously. Underpowered hardware means all of these will fail spectacularly.
JVM Configuration That Actually Works:
## Java 17 settings for Cassandra 5.0.5
-Xms16G -Xmx16G # 50% of RAM, never more than 32GB
-XX:+UseG1GC # G1GC is the only GC that won't kill you
-XX:MaxGCPauseMillis=300 # Good luck hitting this during peak load
-XX:+HeapDumpOnOutOfMemoryError # For when (not if) you OOM
--add-exports java.base/jdk.internal.misc=ALL-UNNAMED # Java 17 requirement
Cassandra 5.0.5's Java 17 migration breaks existing configs. Plan for heap tuning pain.
Installation: Where Dreams Go to Die

Installing Cassandra 5.0.5 on Linux (released August 5, 2025):
## Add repository (pray it doesn't 404)
echo \"deb https://debian.cassandra.apache.org 50x main\" | \
sudo tee -a /etc/apt/sources.list.d/cassandra.sources.list
curl https://downloads.apache.org/cassandra/KEYS | sudo apt-key add -
## Install specific version
sudo apt update
sudo apt install cassandra=5.0.5
## Start service and hope it doesn't immediately crash
sudo systemctl start cassandra
sudo systemctl enable cassandra
## Check if it actually started
sudo systemctl status cassandra
Docker deployment (less painful):
## Single node for development
docker run -d --name cassandra -p 9042:9042 cassandra:5.0.5
## Check logs when it inevitably fails
docker logs cassandra
Kubernetes with K8ssandra (for masochists):
## Add K8ssandra Helm repo
helm repo add k8ssandra https://helm.k8ssandra.io
## Deploy and pray
helm install k8ssandra k8ssandra/k8ssandra
cassandra.yaml Config That Won't Immediately Explode:
## Don't use 'Test Cluster' in production like an amateur
cluster_name: 'Production Cluster'
## Storage paths (separate commit log disk or die)
data_file_directories:
- /var/lib/cassandra/data
commitlog_directory: /var/lib/cassandra/commitlog # Put on fast SSD!
## Memory tuning for 64GB servers
memtable_heap_space_in_mb: 8192
memtable_offheap_space_in_mb: 8192
## Network - use actual server IP, not localhost
listen_address: 192.168.1.100 # Internal cluster communication
rpc_address: 0.0.0.0 # Client connections
native_transport_port: 9042 # CQL port
## Token distribution
num_tokens: 256 # Default, don't change unless you know why
Data Modeling: Where SQL Dreams Come to Die
Cassandra Data Modeling Principles:
Cassandra data modeling breaks everything you know about databases. Forget database normalization - that shit doesn't work here. The rule is \"model your data for your queries\" which means designing tables around how you'll query them, not how the data "should" be organized.
Key concepts that will make you question your career:
Primary Key Design (Get This Wrong and Suffer):
-- Time-series data modeling that won't kill performance
CREATE TABLE user_events (
user_id UUID,
event_date DATE, -- Time bucketing to prevent massive partitions
event_time TIMESTAMP,
event_type TEXT,
event_data JSON, -- New in Cassandra 5.0
PRIMARY KEY ((user_id, event_date), event_time)
);
This design follows Cassandra best practices:
CQL: SQL's Disappointing Cousin
CQL looks like SQL but acts like a psychopath. JOINs don't exist, transactions are limited, and WHERE clauses require the partition key or Cassandra tells you to fuck off.
Queries That Actually Work:
-- Query by partition key (fast)
SELECT * FROM user_events
WHERE user_id = 550e8400-e29b-41d4-a716-446655440000
AND event_date = '2025-08-25';
-- Range query within partition (still fast)
SELECT * FROM user_events
WHERE user_id = 550e8400-e29b-41d4-a716-446655440000
AND event_date = '2025-08-25'
AND event_time > '2025-08-25 10:00:00';
-- SAI index query (finally works in 5.0.5)
CREATE INDEX ON user_events (event_type) USING 'sai';
SELECT * FROM user_events
WHERE event_type = 'purchase'
AND user_id = 550e8400-e29b-41d4-a716-446655440000;
Queries That Will Fuck You:
-- This will timeout and ruin your weekend
SELECT * FROM user_events WHERE event_type = 'purchase';
-- Error: Cannot execute this query as it might involve data filtering
-- This will scan everything and die
SELECT * FROM user_events;
-- Prepare for 30-second timeouts
-- Updates without partition key = data corruption
UPDATE user_events SET event_data = 'corrupted' WHERE event_type = 'login';
-- Good luck finding which records got fucked
-- DELETE on large partitions = performance death
DELETE FROM user_events WHERE user_id = 'some-uuid' AND event_date < '2025-01-01';
-- Kiss your cluster goodbye for the next 2 hours
Read the CQL documentation or prepare for pain.
Cluster Setup: Where Distributed Systems Expertise Goes to Die
Setting up a multi-node Cassandra cluster requires understanding network topology, failure domains, and gossip protocols. Get any of this wrong and you'll have split-brain scenarios at 3am.


Three-Node Cluster (Minimum for Not Losing Data):
## Node 1 - Seed node configuration
seeds: \"cassandra1.example.com,cassandra2.example.com\" # Multiple seeds for redundancy
listen_address: cassandra1.example.com # Internal communication
rpc_address: cassandra1.example.com # Client connections
endpoint_snitch: GossipingPropertyFileSnitch # For multi-DC
## Node 2 - Also a seed node
seeds: \"cassandra1.example.com,cassandra2.example.com\"
listen_address: cassandra2.example.com
rpc_address: cassandra2.example.com
endpoint_snitch: GossipingPropertyFileSnitch
## Node 3 - Regular node
seeds: \"cassandra1.example.com,cassandra2.example.com\"
listen_address: cassandra3.example.com
rpc_address: cassandra3.example.com
endpoint_snitch: GossipingPropertyFileSnitch
Don't make all nodes seeds - 2-3 seed nodes maximum or gossip becomes a shitshow.
Checking if Your Cluster is Fucked:
## Most important command you'll ever run
nodetool status
## What healthy looks like (spoiler: yours won't)
## Status=Up/Down, State=Normal/Leaving/Joining/Moving
## Address Load Tokens Owns Host ID Rack
## UN 10.0.1.10 2.5TB 256 33.3% abc-123 rack1
## UN 10.0.1.11 2.4TB 256 33.3% def-456 rack1
## UN 10.0.1.12 2.6TB 256 33.4% ghi-789 rack1
## What disaster looks like
## DN 10.0.1.10 2.5TB 256 33.3% abc-123 rack1 # DOWN/NORMAL = node died
## UL 10.0.1.11 2.4TB 256 33.3% def-456 rack1 # UP/LEAVING = node leaving cluster
## UJ 10.0.1.12 0 256 33.4% ghi-789 rack1 # UP/JOINING = bootstrapping
If you see anything other than "UN" (Up/Normal), start panicking.
Cassandra Monitoring Dashboard Setup:
Cassandra monitoring is like drinking from a firehose. JMX metrics provide thousands of data points but zero useful error messages when things break. The nodetool utility is your lifeline to understanding what's actually happening.
Commands That Might Save Your Weekend:
## Check thread pool stats (first sign of trouble)
nodetool tpstats
## Look for \"pending\" - anything > 0 means you're in trouble
## Compaction status (death spiral detector)
nodetool compactionstats
## If pending compactions > 32, cancel your vacation
## Repair operations (the never-ending story)
nodetool repair keyspace_name
## This will take hours and might break more things
## Gossip info (who's talking to whom)
nodetool gossipinfo
## Tells you which nodes think they're in the cluster
## Disk usage by keyspace (storage explosion tracker)
nodetool cfstats keyspace_name | grep \"Space used\"
## Because Cassandra eats disk space like candy
Essential monitoring integrations:
Moving Cassandra to production isn't just about scaling - it's about accepting that you'll need dedicated platform engineers who understand distributed systems. Budget for 24/7 monitoring, comprehensive alerting, and the knowledge that 3am database emergencies are now part of your life.
Success with Cassandra requires proper capacity planning, monitoring that actually helps, and acceptance that distributed systems expertise isn't optional - it's survival.