Twitter built Zipkin because their site was slower than dial-up and nobody could figure out why. When a single tweet involves too many damn services, debugging becomes less "check the logs" and more "stare at dashboards until something makes sense." The original Twitter blog post explains their pain points in detail.
The Microservices Debugging Nightmare
Remember the good old days of monoliths? You'd stick a debugger on your code, step through it, and find your bottleneck. Simple. Boring. Effective.
Then someone invented microservices. Now that same user request bounces through 15 different services, each written in a different language, running on different machines, with different lag times. When shit breaks, good luck figuring out where. The Google Dapper paper describes this exact problem and inspired Zipkin's design.
Without tracing, debugging a slow request is like trying to find a memory leak with printf statements. You'll waste hours checking everything except the actual problem. I spent two days tracking down a 2-second delay that turned out to be some idiot (okay, it was me) who misconfigured a connection pool. The Netflix chaos engineering blog has war stories that'll make you appreciate tracing when the pager goes off at midnight.
What Zipkin Actually Does
Zipkin shows you the path your request took and where it got stuck. When you have a 5-second response time, Zipkin tells you that most of it was spent waiting for the recommendations service because someone deployed code that hits the database one row at a time instead of batching. Classic.
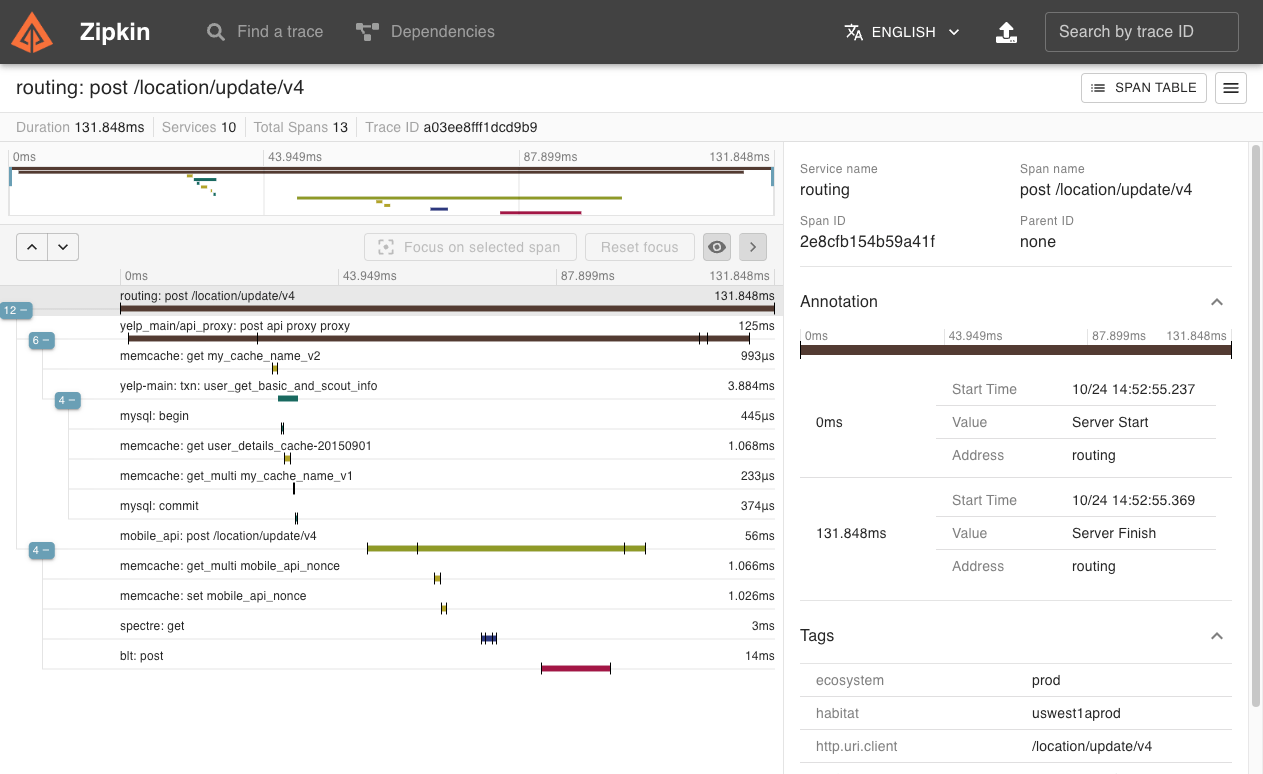
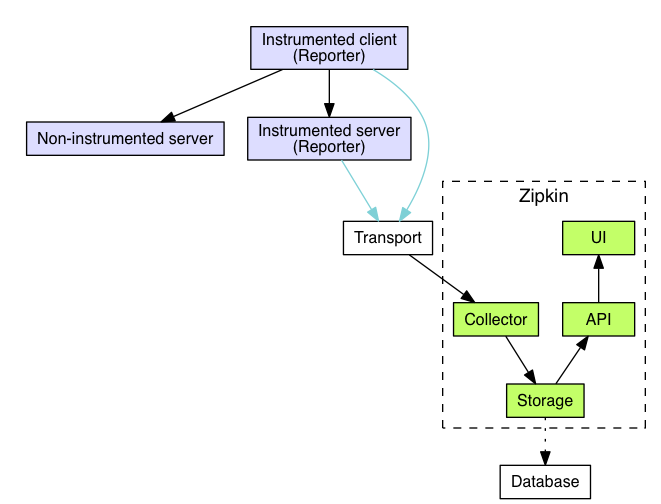
It follows your request as it bounces between services using lightweight trace IDs. Each service reports timing data asynchronously, so your app doesn't slow down while sending telemetry (unlike some APM tools that make your performance worse while measuring it). The Zipkin data model documentation explains how spans and traces work, and this Spring Boot tracing guide shows practical implementation.
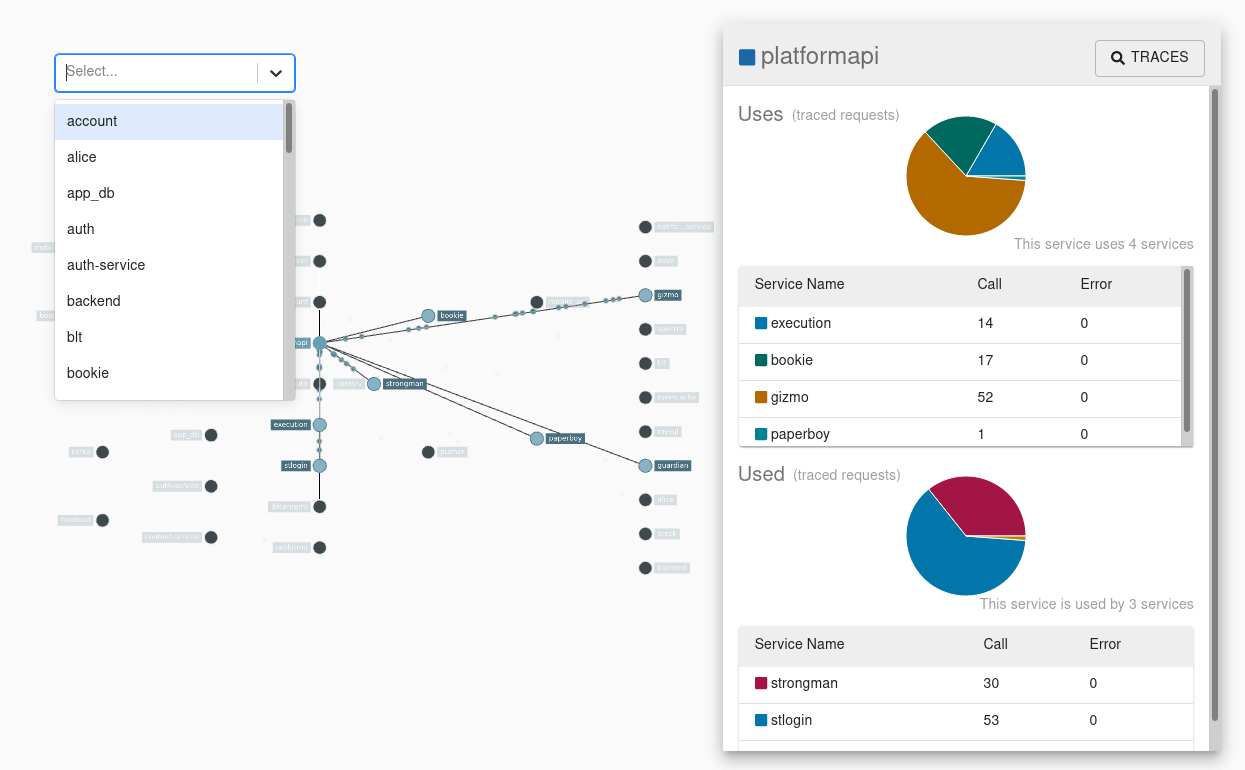
The dependency graph actually doesn't suck - shows you which services will break when payments goes down. When checkout, user accounts, and the mobile API all start throwing errors, you'll know exactly why before your Slack channels explode.
Why It Doesn't Suck
Zipkin is basically one JAR file that doesn't crash your app. Unlike some tracing systems that need a PhD to configure, you can literally run java -jar zipkin.jar and start seeing traces. The official quickstart guide gets you running in under 5 minutes.
The overhead is actually minimal - we're talking less than 1% impact on request processing. Compare this to heavyweight APM tools that slow your app down more than the bugs you're trying to find. Performance benchmarks show real numbers.
It supports real storage backends too. Elasticsearch if you want fancy queries (and can afford the hosting costs), Cassandra if you need to scale to Twitter levels, or MySQL if you want something simple that works. The storage comparison page has honest assessments of each option.
Current State (September 2025)
Version 3.5.1 came out in April 2024 - been running it for over a year now, zero issues. The OpenZipkin team keeps shipping updates without breaking existing deployments - a rare trait in the observability space. Check the release notes for what's new.
The project has 17.3k GitHub stars because it actually solves real problems without creating new ones. Companies like Pinterest, SoundCloud, and Yelp have public case studies. It's evolved way beyond Twitter's original use case but still maintains the "simple things should be simple" philosophy.