Stop Fixing Shit That Breaks Every Week
Most teams live in permanent firefighting mode. Something breaks, you scramble to fix it, then rinse and repeat. It's exhausting, expensive, and completely avoidable.
Our Black Friday disaster cost us:
- $180k in lost sales during a 6-hour outage
- $30k in AWS charges for the recovery scramble (because panic-scaling costs money)
- 72 hours of engineering time across three people debugging something that could have been prevented
- One engineer who quit two weeks later citing "burnout from constant emergencies"
- Three months of explaining to the board why our "cloud-native architecture" shit the bed
That $5,600/minute figure you see everywhere? That's bullshit from 2014. Real 2025 data shows enterprise downtime now costs $14,056 per minute on average, rising to $23,750/minute for large companies. The Uptime Institute's latest research shows unplanned outages now cost over $100,000 per incident.
Our hourly burn rate during outages hits $40k when you factor in lost revenue, AWS costs, and engineering team overtime. That Black Friday incident? We could have hired a full-time SRE for six months with what we lost in one night. Recent case studies show downtime costs have tripled since 2020 due to increased digital dependency.

Prevention vs. Playing Hero at 3 AM
Here's what changed after we got serious about prevention:
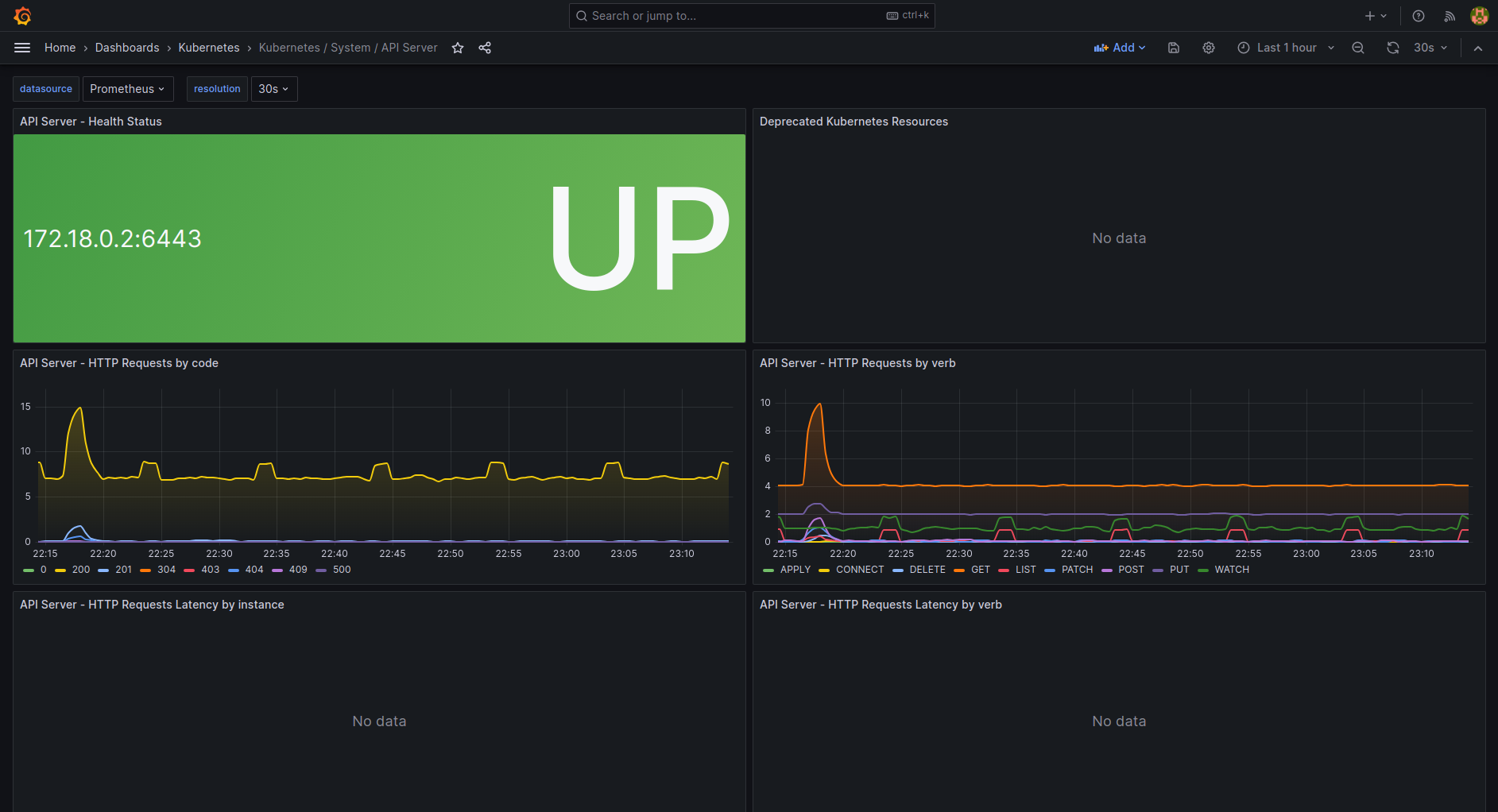
Stop Trusting Prometheus to Save Your Ass
Prometheus is great until it runs out of memory at the worst possible moment. We learned this the hard way when our monitoring stack crashed during an outage. Turns out, collecting metrics on everything doesn't help when the collector is dead. Tigera's monitoring guide covers the fundamentals most teams get wrong.
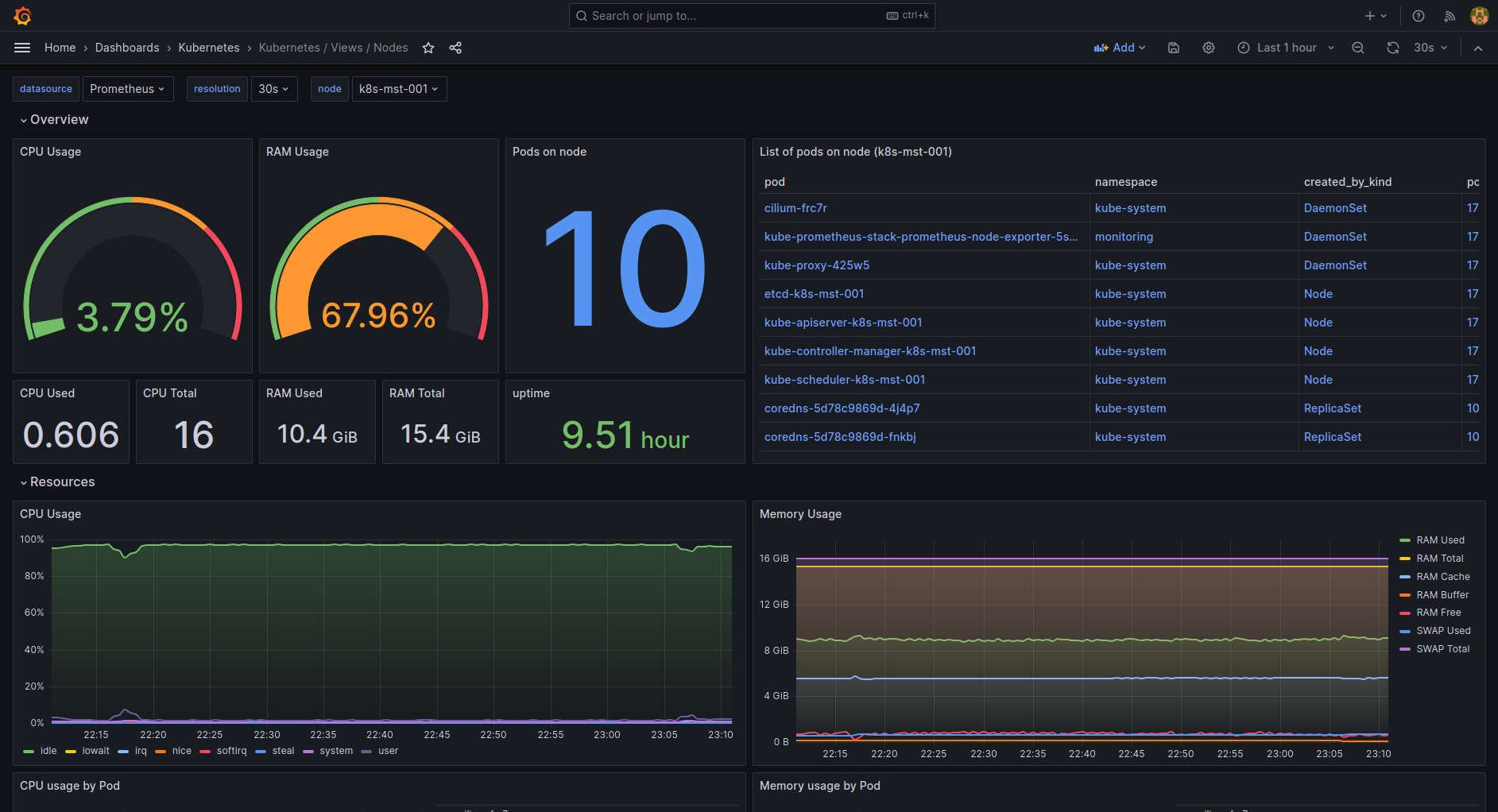
Resource trending that actually works: Track disk usage growth over weeks, not current usage. etcd will fill your disk for months before you notice, then kill your cluster in minutes. DataDog's recent analysis shows why the 8GB etcd limit catches everyone off guard.
etcd Storage Monitoring Example: A proper etcd monitoring dashboard shows disk usage trends, compaction status, and performance metrics that reveal storage growth patterns before they become critical.
## This alert saved us twice in the past year
alert: EtcdDiskGrowth
expr: predict_linear(etcd_mvcc_db_total_size_in_bytes[7d], 7*24*3600) > 8e+9
annotations:
summary: "etcd will hit 8GB limit in 7 days at current growth rate"
etcd latency monitoring: Don't wait for 100ms+ latency to alert. We alert at 20ms sustained increase because that's the canary in the coal mine. By the time you hit 100ms, you're already fucked. The etcd team's official metrics guide explains why latency spikes are the first sign of trouble.
API server overload patterns: Watch for request queue buildup and increased admission controller rejections. These happen hours before complete API server lockup, giving you time to investigate instead of debugging in crisis mode. Kubernetes official monitoring docs explain the warning signs, but you need to act on them fast.
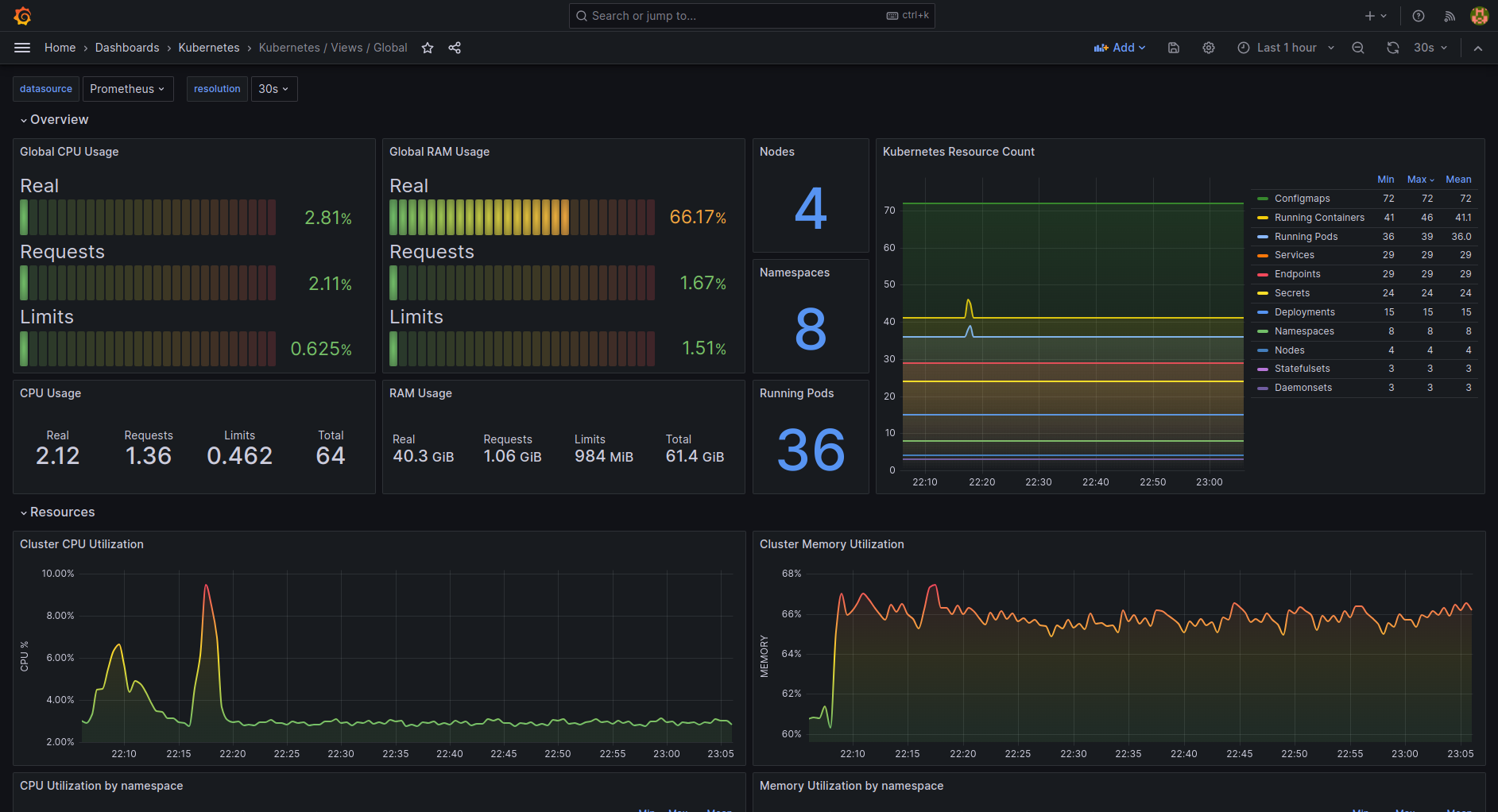
Infrastructure That Doesn't Eat Itself
Node capacity management: We maintain 40% unused capacity now, not the "recommended" 20%. Yes, it costs more. You know what costs more? Emergency node scaling during an incident when AWS takes 10 minutes to provision and your autoscaler is having a meltdown. ScaleOps research proves that over-provisioning prevents more outages than it causes waste.
Multi-AZ is not optional: Single AZ failures happen monthly in us-east-1. If you're not spread across at least 3 AZs with actual pod anti-affinity rules, you're gambling with your uptime. We learned this when a whole AZ went down and took our entire payment processing system with it. AWS's reliability pillar guide explains why AZ failures are inevitable, but most teams still don't plan for them.
Storage monitoring that isn't useless: Alert at 60% PVC usage, not 80%. Kubernetes storage is about as predictable as cryptocurrency prices, and you need time to expand volumes before hitting limits. SUSE's alerting best practices covers storage monitoring that actually prevents incidents.
GitOps Done Right (Not GitOps Theater)
ArgoCD reliability issues: ArgoCD is fantastic until it gets into sync loops and applies the same broken config 47 times. We've had to restart ArgoCD more times than I'd like to admit. Set up monitoring for ArgoCD itself - the tool that's supposed to prevent outages can cause them. Komodor's 2025 best practices guide covers GitOps pitfalls you need to avoid.
Policy enforcement reality: OPA Gatekeeper is great in theory. In practice, it'll reject critical emergency deployments at 2 AM because someone forgot to add a required label. Have an emergency bypass process or you'll be editing policies while the site is down.
Certificate rotation horror stories: cert-manager works until it doesn't. We monitor certificate expiration with multiple tools because we've had cert-manager silently fail to renew certificates three times. Let's Encrypt rate limits will bite you during a mass renewal event.
Design Patterns That Actually Prevent Cascades
Circuit breakers that don't suck: Istio circuit breakers are configurable but complex. Start with simple timeouts and retries before getting fancy. We've seen more outages caused by misconfigured circuit breakers than prevented by them.
Resource isolation reality: Dedicated nodes for system components cost extra but save your sanity. When your application pods eat all available memory, you don't want your DNS resolver going down too. We learned this during a memory leak that took down our entire monitoring stack.
Graceful degradation: Build your services to fail gracefully or they'll fail spectacularly. Our payment service now caches the last known good configuration and serves limited functionality during database outages instead of returning 500s.
Resource Management That Doesn't Lie to You
QoS classes in practice: Guaranteed QoS pods get their resources, but they also can't share unused resources efficiently. We use a mix of Guaranteed for critical services and Burstable for everything else. The textbook "use Guaranteed everywhere" advice will bloat your AWS bill.
PDB gotchas: Pod Disruption Budgets prevent deployments during node maintenance if set too restrictively. We've had deployments stuck for hours because PDBs blocked node evictions. Set them appropriately or they'll bite you during critical updates.
HPA scaling delays: Horizontal Pod Autoscaling is slow and sometimes doesn't scale fast enough for traffic spikes. We pre-scale before known traffic events because waiting for HPA during a flash sale is like bringing a knife to a gunfight.
Real Monitoring That Detects Problems Before Users Notice
The Four Signals Everyone Talks About:
- Latency: We track P95 and P99, but also watch P50 trends. A slowly degrading P50 often indicates resource starvation before the P99 goes haywire.
- Traffic: Rate changes matter more than absolute rates. A 30% traffic drop at 10 AM on a Tuesday is more concerning than high traffic during a sale.
- Errors: Error rate increases are critical, but so are new error types. A single new error class often indicates a deployment or configuration issue.
- Saturation: Memory trends are more predictive than CPU for Kubernetes workloads. CPU spikes are normal; memory leaks kill clusters.
Context-aware alerting that doesn't spam you: High CPU during business hours is expected. The same level at 3 AM means something is broken. We use time-based alert thresholds because context matters more than absolute numbers.
The brutal truth: Most monitoring setups are notification systems for outages that already happened. Real prevention monitoring tracks trends and patterns that predict failures days in advance. It takes more work to set up, but it's the difference between sleeping through the night and explaining to customers why their data is gone.
Prevention costs money upfront. Outages cost more money, plus your sanity, plus your team's sanity, plus potentially your job. Choose wisely.