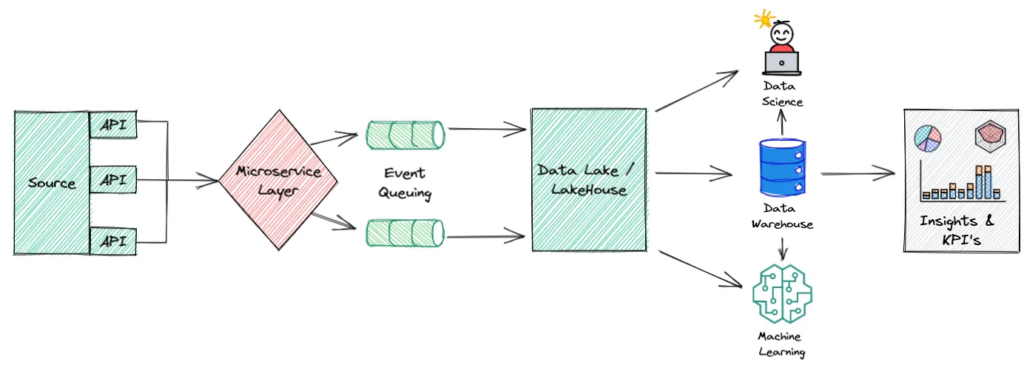
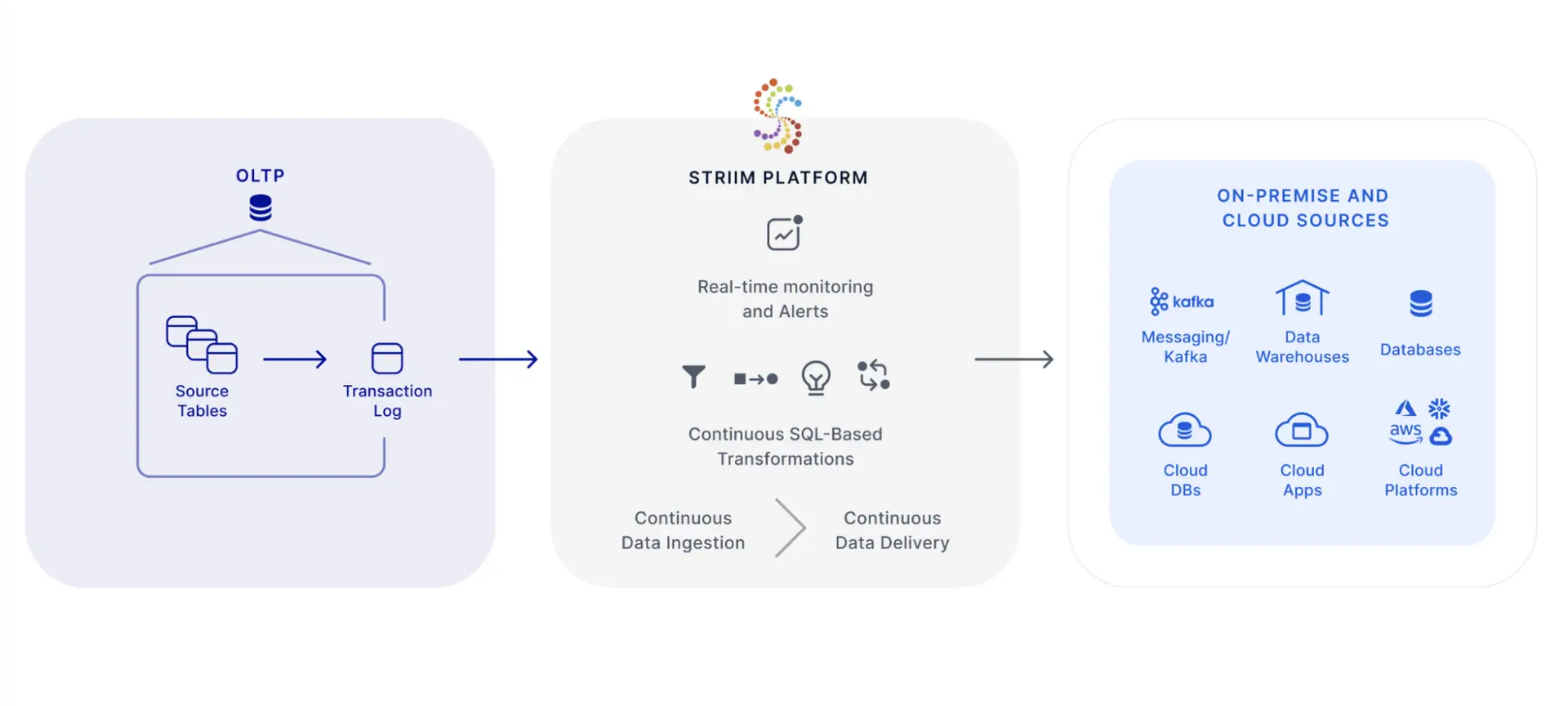
Look, if you've ever tried to build real-time data pipelines that don't crash every weekend, you know the pain. Striim is what happens when the Oracle GoldenGate team gets tired of dealing with shitty CDC implementations and decides to build something that actually works.
The core problem Striim solves: how do you move data from operational databases to analytics systems without either A) destroying your source DB with polling queries, or B) building a Rube Goldberg machine of triggers that breaks every time someone sneezes near the schema?
What Makes Striim Different (And Less Annoying)
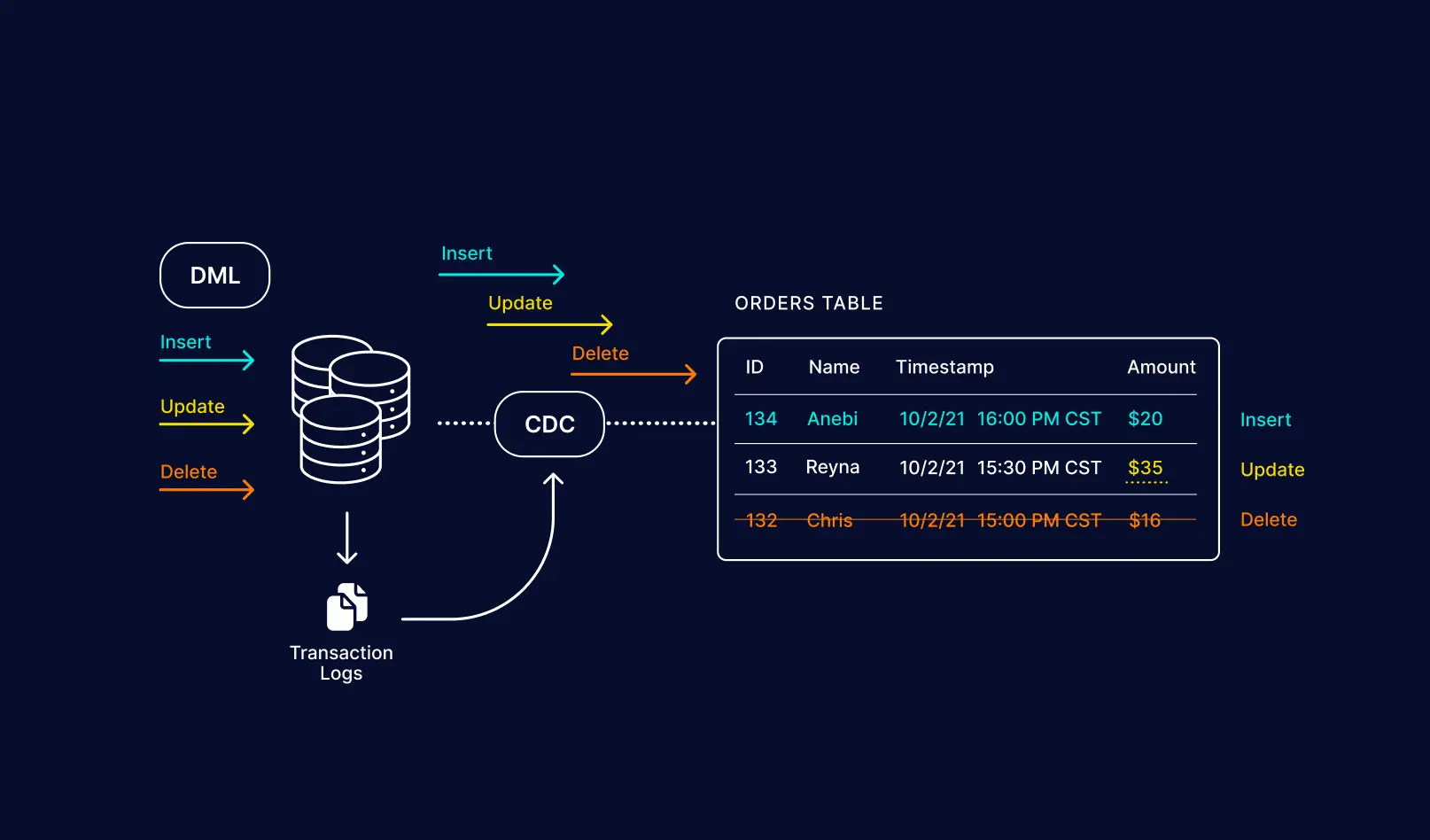
Log-Based CDC That Actually Works: Unlike tools that hammer your database with SELECT * FROM table WHERE last_modified > ? every 30 seconds, Striim reads directly from transaction logs. Your Oracle DBA won't murder you, and you get sub-second latency. Win-win.
Schema Evolution Without The Panic: When that product manager inevitably adds a new column to the user table at 4 PM on Friday, Striim can handle schema changes automatically or alert you to review them. No more broken pipelines ruining your weekend.
Multi-Target Replication: One CDC stream can feed Snowflake (see their real-time CDC architecture), BigQuery, your Kafka cluster, and that legacy system that procurement won't let you decommission. Same data, multiple destinations, no additional load on source.

The Team That Built This Mess (In A Good Way)
The Striim founding team came from Oracle GoldenGate, which means they've actually dealt with enterprise-scale CDC nightmares before. They know the difference between "works in the demo" and "survives Black Friday traffic."
Their Oracle connector is probably the most battle-tested piece of the platform - these folks have been reading Oracle redo logs since before containers were cool.
Actual Customer Stories (Not Marketing Fluff)
American Airlines uses Striim to keep 5,800 daily flights running. When your CDC pipeline failing means planes don't take off, you pick tools that don't fail.
UPS processes package data in real-time to catch address issues before delivery. The alternative is drivers showing up at "123 Main Street, Mars" and having to call customer service.
Morrisons CTO Peter Laflin put it best: "Without Striim, we couldn't create the real-time data that we then use to run the business." When retail inventory is wrong, you lose money. Simple as that.
Pricing Reality Check
Striim Cloud Enterprise: Available on AWS, Google Cloud, and Azure marketplaces. Pricing is around $100 per million events plus compute time. For serious production workloads, think thousands per month, not hundreds.
The Self-Managed Option: If you're the type who insists on running your own Kubernetes cluster, you can self-host Striim. Gives you more control but also more 3 AM alerts when something breaks. Check the deployment architecture docs for production planning.
Budget Reality: For workloads processing millions of events daily, budget at least $5K monthly. Enterprise contracts might bring this down, but don't expect cheap. Quality CDC costs money.
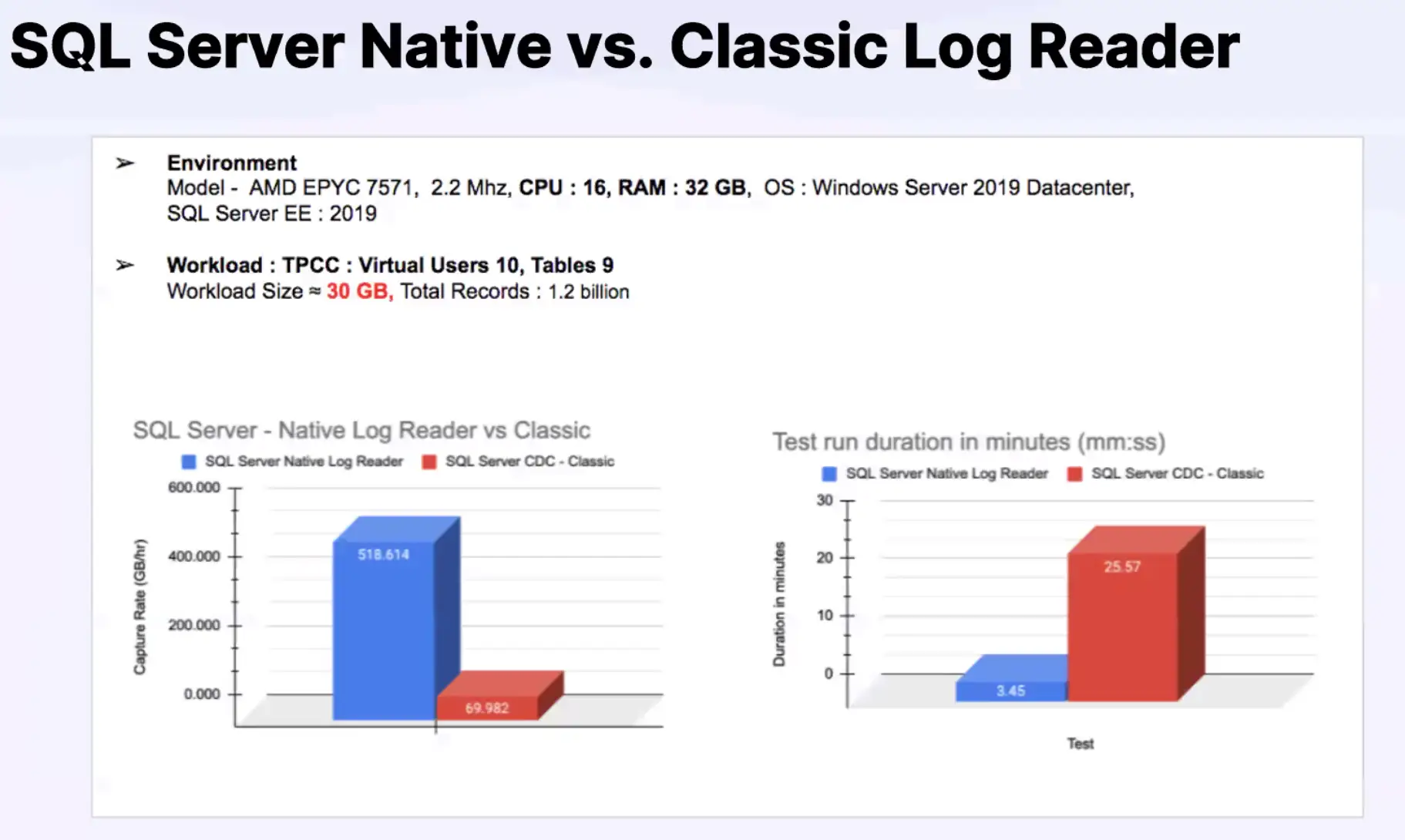
Pricing aside, here's how it actually performs when your database is getting hammered and your downstream systems are choking.