Look, I've dealt with enough data tools to know most of them are garbage. dbt is different - it actually solves real problems instead of creating new ones.
What dbt Actually Does (No Marketing Bullshit)
dbt is a command-line tool that takes your SQL files and runs them in the right order. That's it. Sounds simple until you realize how fucked up most data workflows are without dependency management. I've seen too many analysts copying SQL between Jupyter notebooks praying everything runs in the right sequence.
Here's what made me switch from building ETL pipelines in Python:
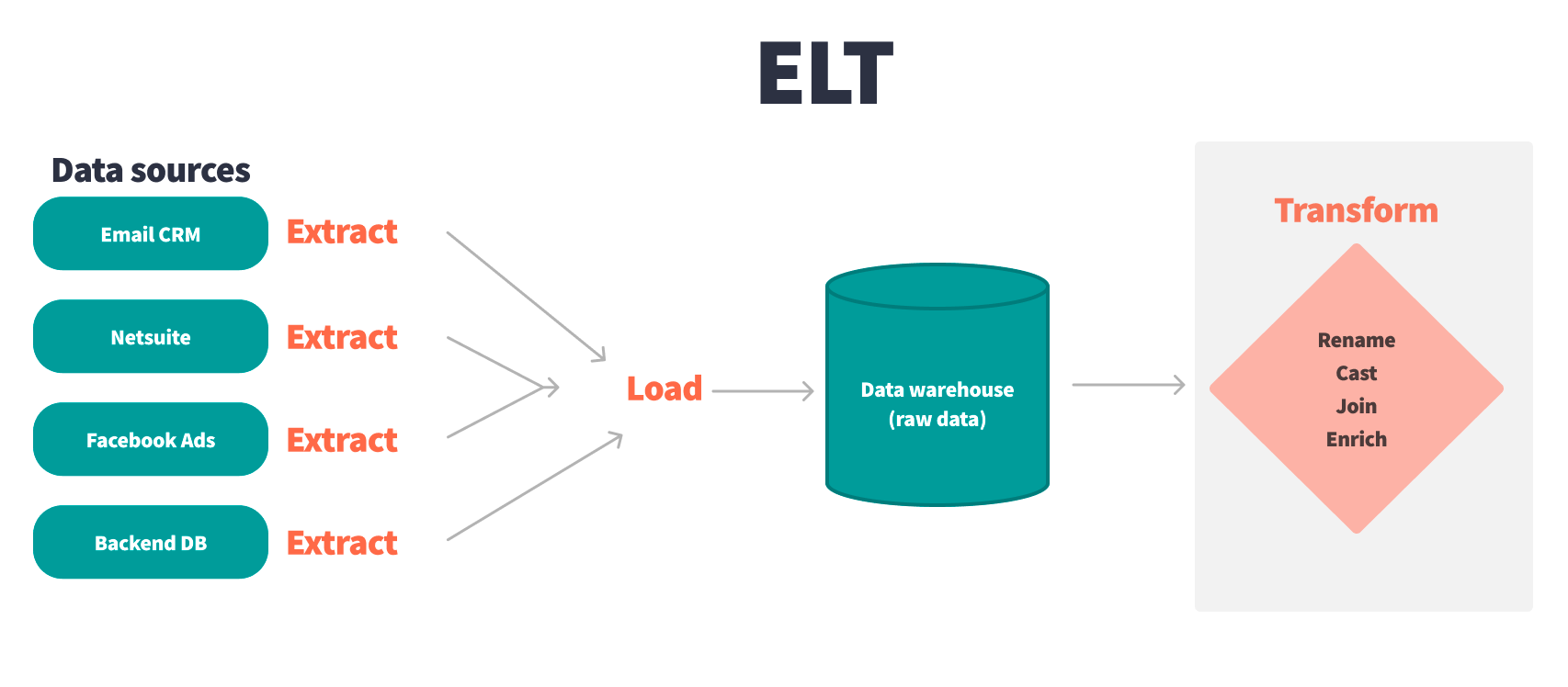
No More Data Movement Hell: Instead of extracting data from your warehouse, transforming it elsewhere, then loading it back, dbt just runs SQL directly in your warehouse. Your data stays put. Snowflake, BigQuery, Redshift - they're all fast enough to handle transformations without the circus of moving terabytes around.
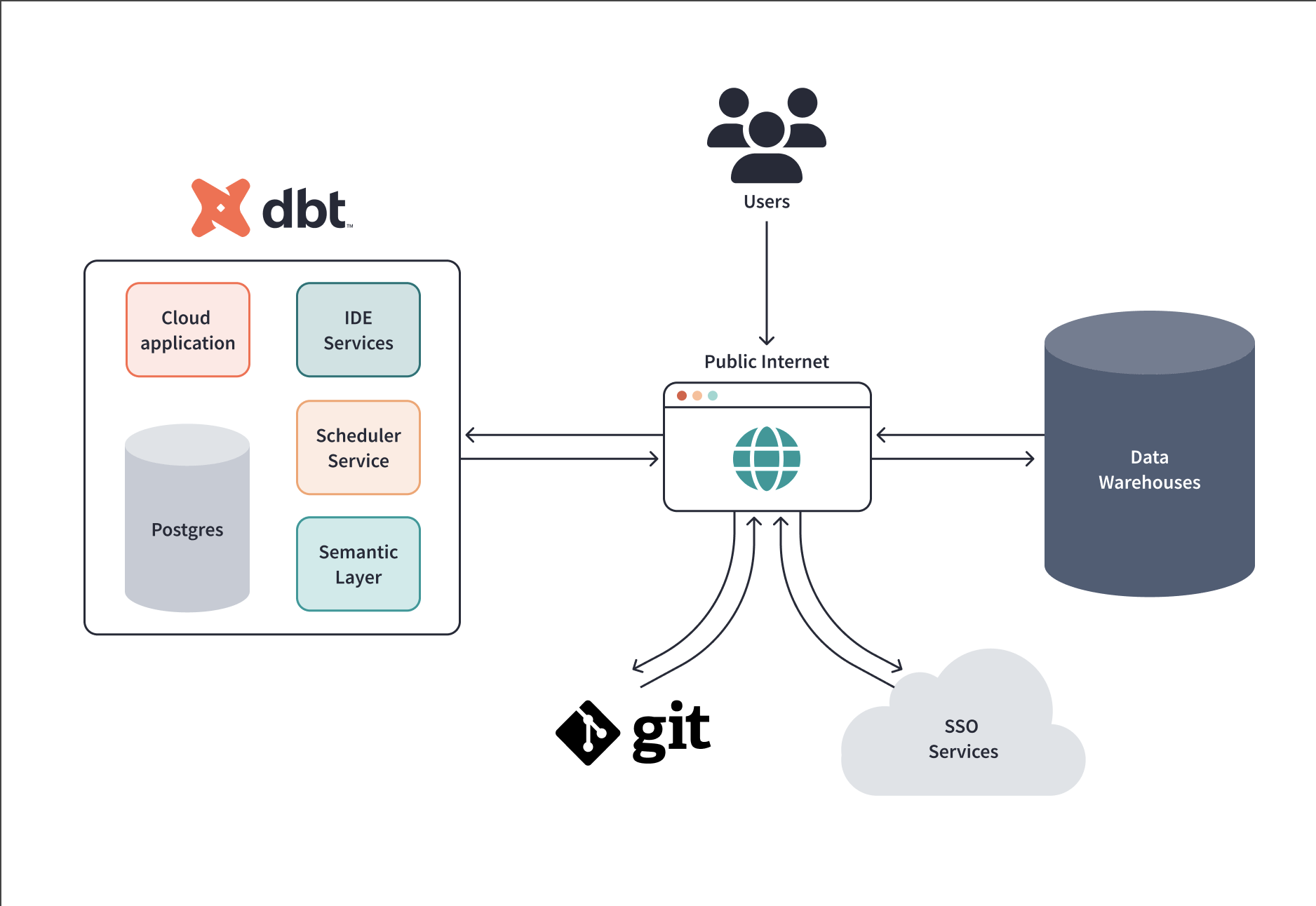
Git That Actually Works: Unlike Tableau or other BI tools where version control is an afterthought, dbt was built for Git. Every SQL file, every configuration, every test lives in your repo. When someone breaks prod (and they will), you can actually see what changed.
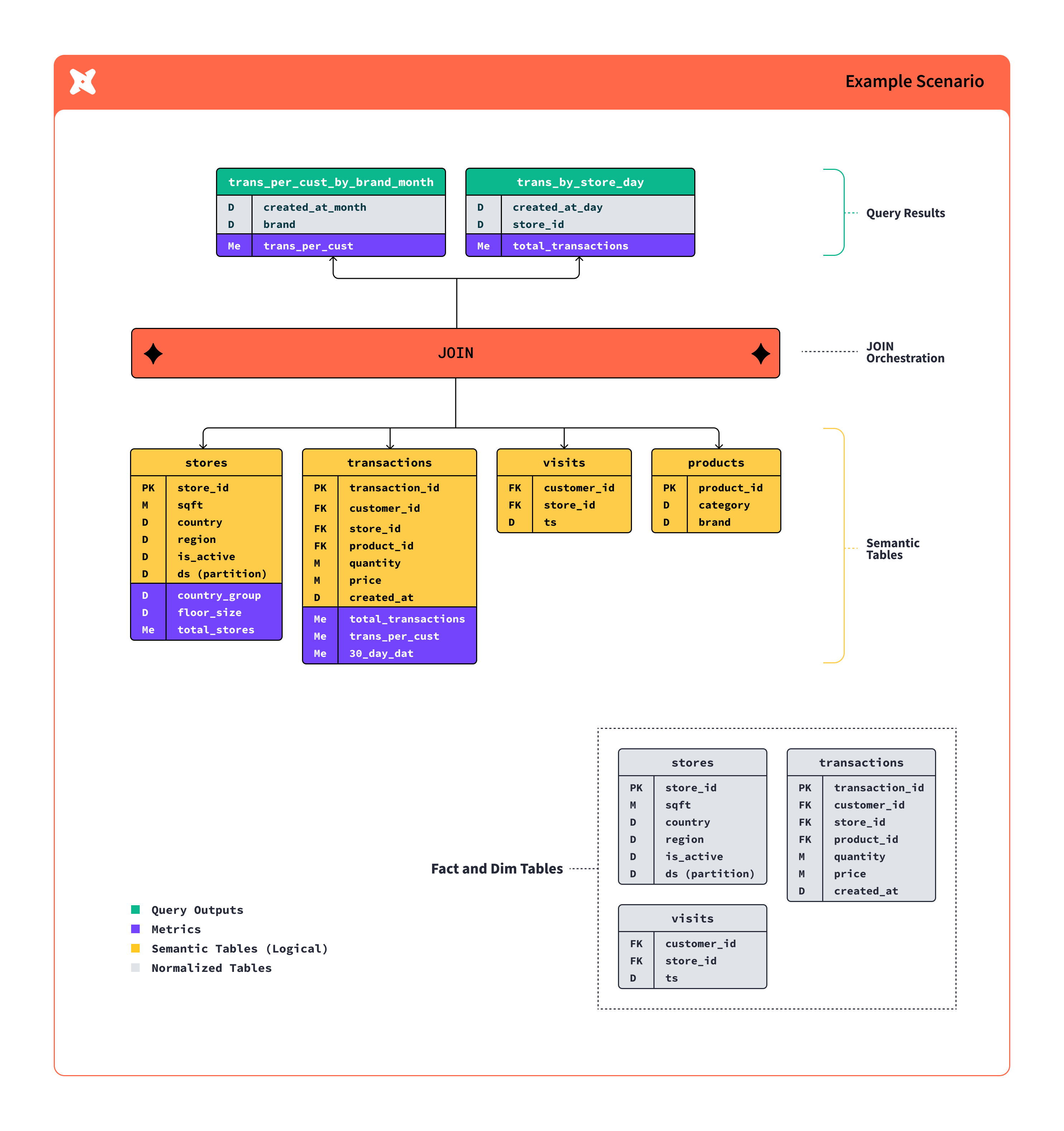
Dependencies That Don't Break Everything: The {{ ref() }} function is genius. Instead of hardcoding table names, you reference other models. dbt builds a dependency graph and runs everything in the right order. When you need to change a upstream model, dbt knows what downstream models need rebuilding.
How It Actually Works in Practice
I'll walk you through what a real workflow looks like, not the perfect-world scenarios in tutorials:
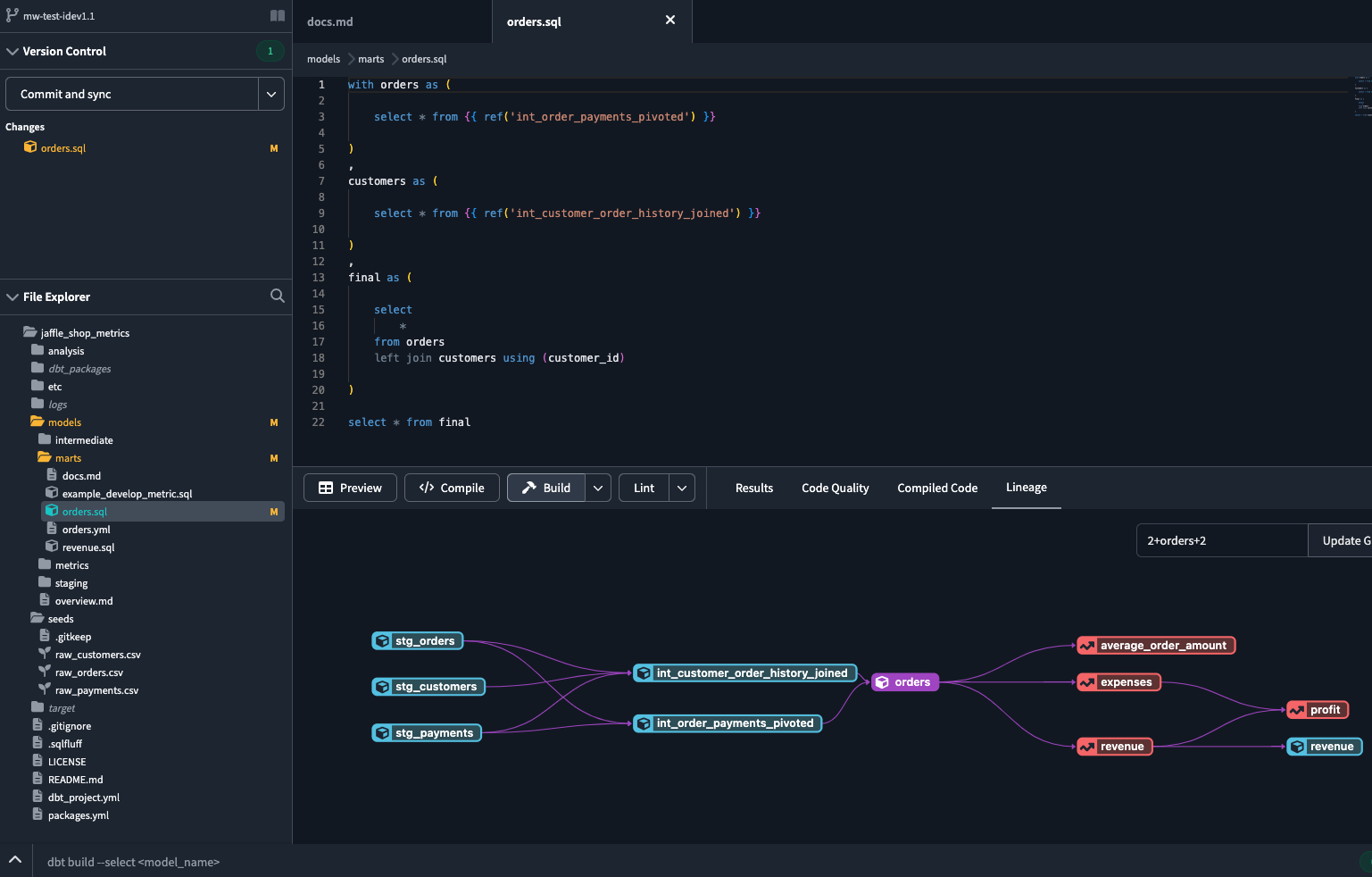
Write SQL models - Each .sql file is one transformation. Simple SELECT statements that reference other models with
{{ ref('upstream_model') }}.Add tests because data lies - Built-in tests for uniqueness, null checks, referential integrity. Takes 2 minutes to add, saves hours of debugging downstream.
Run
dbt runand pray - dbt compiles everything, figures out the execution order, and runs your SQL. When it works, it's beautiful. When it breaks, at least the error messages aren't complete garbage.Deploy with actual CI/CD - Unlike other data tools, you can use real CI/CD practices. GitHub Actions, GitLab CI, whatever. Test changes in branches before they hit prod.
The dbt Community Slack has 100,000+ people because the tool actually solves real problems. That's not typical for data tools - usually communities exist just for people to vent about how broken everything is.
Real Performance Numbers
dbt Labs hit $100M ARR because enterprises like Nasdaq, HubSpot, and Condé Nast actually get value from it. The new Fusion engine parses projects 30x faster - on our 300-model project, parse time went from 90 seconds to 3 seconds. That's the difference between "time for coffee" and "actually usable".
Now that you understand why dbt doesn't completely suck, let's get real about how it compares to the alternatives - because you're probably evaluating other tools too.