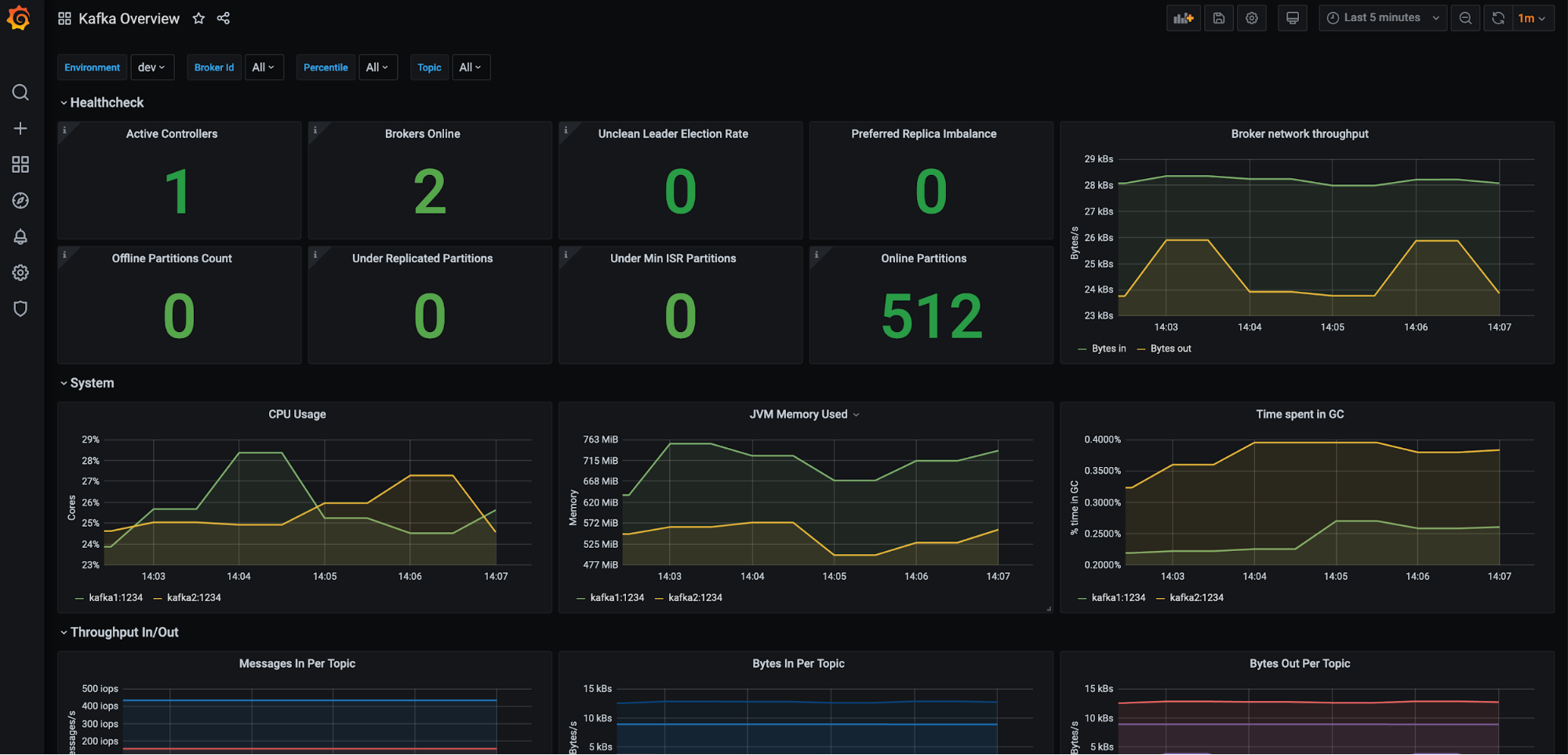
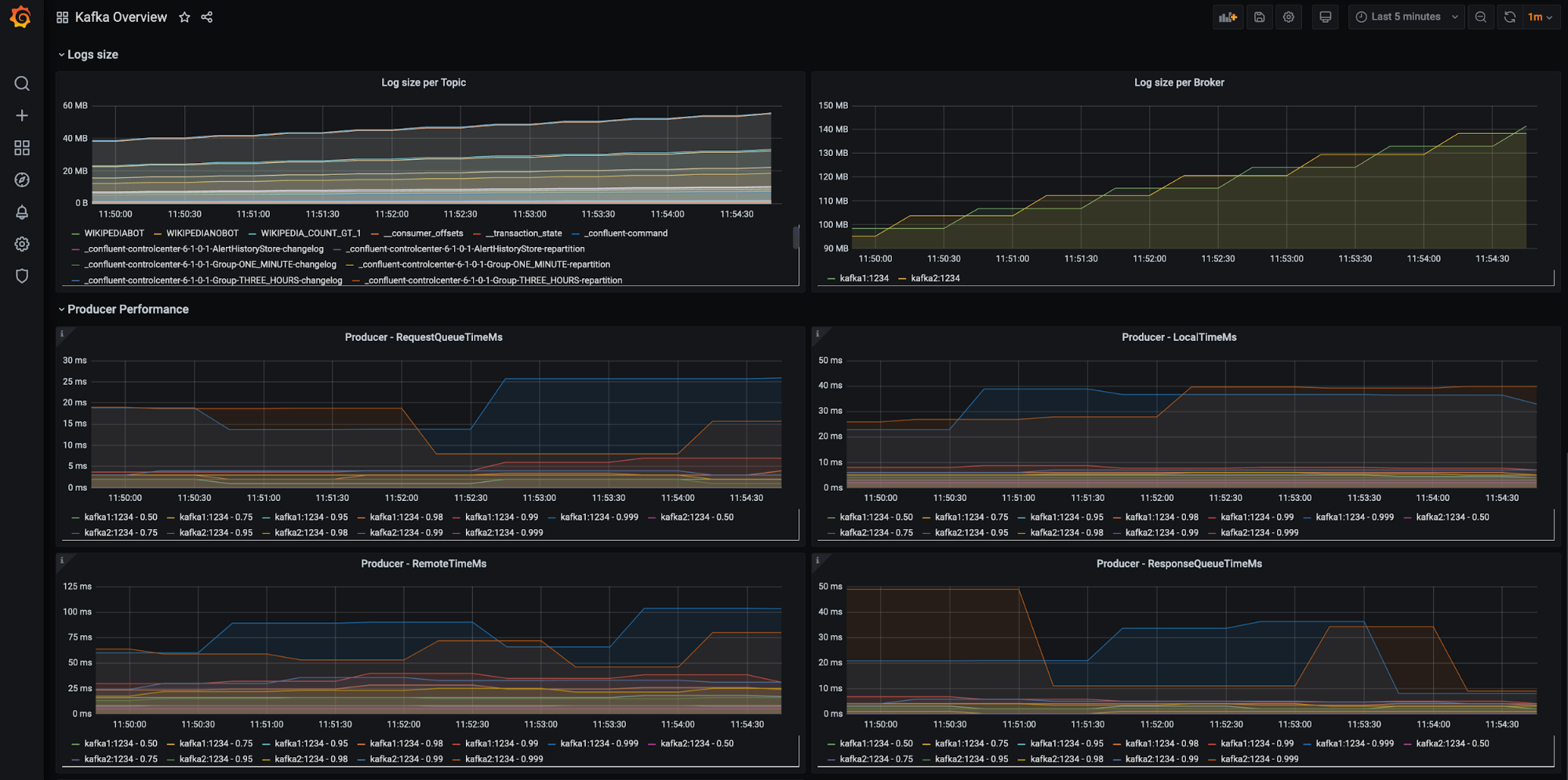
CDC implementations fail because nobody tells you the real problems. Here's what went wrong at the 3 companies where I built these systems.
The PostgreSQL 13.6 Nightmare
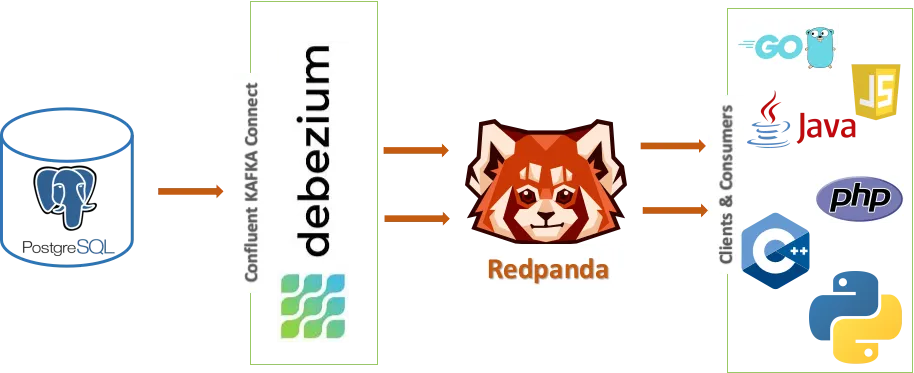
First company used PostgreSQL 13.6 with logical replication. Everything worked fine until we hit around 2 million events per hour. Then shit got weird.
The WAL files started growing like cancer because Debezium couldn't keep up with the replication slot. We went from 2GB WAL to 50GB in 3 hours. Production disk filled up at 2:47 AM on a Saturday.
Fixed it by tuning max_slot_wal_keep_size to 4GB and adding monitoring that pages at 80% WAL growth. But the real fix was switching from pgoutput to wal2json plugin - handles high volume way better.
Lesson: PostgreSQL logical replication will eat your disk if you don't watch WAL growth like a hawk.
Pro tip: Use this query to monitor WAL lag before it kills you:
SELECT slot_name,
pg_size_pretty(pg_wal_lsn_diff(pg_current_wal_lsn(), restart_lsn)) as lag_size,
active,
confirmed_flush_lsn
FROM pg_replication_slots;
Set up alerts when lag_size hits 1GB. At 5GB, you're in trouble. At 10GB, you're fucked.
The Kafka Networking Hell
Kafka Connect Distributed Mode Architecture: Multiple worker processes coordinate to run connectors and tasks across different availability zones. When network latency spikes between zones, connector rebalancing creates cascading failures that can take hours to recover from.
Second company had everything on AWS. Confluent Cloud looked perfect on paper. In reality, cross-AZ latency killed us.
Debezium connectors ran in us-east-1a, source DB in us-east-1b, Kafka in us-east-1c. Network latency averaged 2-3ms but spiked to 50ms during peak hours. CDC lag went from 200ms to 30 seconds randomly.
The Kafka Connect distributed mode made it worse - connectors kept rebalancing when network hiccupped. Lost 6 hours of changes during one particularly bad rebalance.
Solution: Run everything in the same AZ and fuck the high availability marketing bullshit. Deployed Kafka Connect workers on dedicated instances with local SSD storage. Cut lag to under 500ms consistently.
Lesson: Network topology matters more than the vendor demos show. Collocate your shit.
The Schema Evolution Disaster
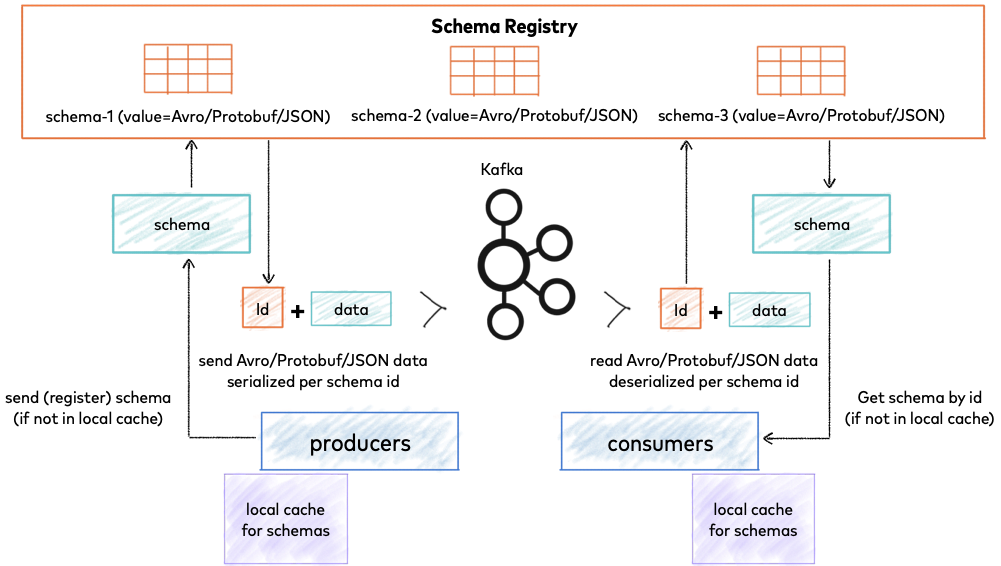
Third company hit the schema evolution problem that nobody prepares you for. Product team added a NOT NULL column to users table without backward compatibility.
Debezium connector died instantly with org.apache.avro.AvroTypeException. But it didn't just stop - it corrupted the offset and had to restart from the beginning. 48 hours of events needed reprocessing.
Downstream applications started getting mixed schema versions. Analytics team spent 2 weeks cleaning up duplicate data. The Schema Registry compatibility checks we thought would save us? Useless when developers bypass them.
Lesson: Schema evolution will fuck you. Test every schema change in staging with actual CDC pipelines running.
Tools That Don't Suck
After 3 implementations, here's what actually works:
Debezium 3.x + PostgreSQL: Rock solid if you tune PostgreSQL properly. Use wal2json output plugin, not the default pgoutput. Monitor WAL size religiously.
AWS DMS: Good for simple MySQL -> PostgreSQL migrations. Terrible for real-time streaming. The parallel load feature breaks randomly.
Confluent Connect: Overpriced but works. Their JDBC source connector handles Oracle better than anything else. Worth the money if you have Oracle.
Airbyte: Great for batch ELT, shit for real-time CDC. The incremental sync is basically polling with lipstick.
Stop reading vendor marketing. Pick tools based on what you can actually debug when it breaks at 3 AM.