I've been running Snowflake in production for about 18 months now, and here's what actually matters if you're evaluating it.
The Architecture Thing Everyone Talks About
Look, every vendor claims their architecture is "unique" or "revolutionary." With Snowflake, the separation of storage and compute actually solves real problems I've dealt with:
Before Snowflake, scaling our Oracle warehouse meant buying more hardware and scheduling downtime. When we hit peak usage, everything slowed to shit. When usage dropped, we paid for idle servers.
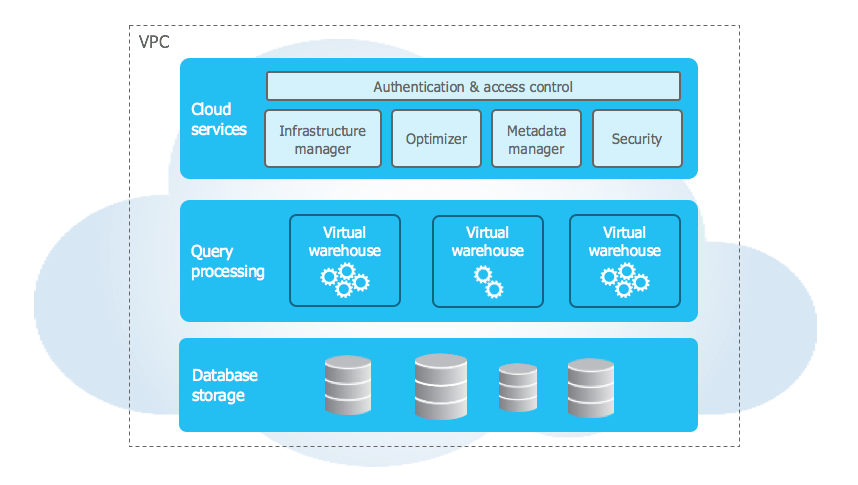
Snowflake has three layers:
- Storage: Your data sits in compressed columns in S3/Azure/GCS
- Compute: Virtual warehouses that spin up/down in seconds
- Services: Handles auth, metadata, query optimization

The key insight: these scale independently. Need more compute for month-end reporting? Spin up a bigger warehouse for 2 hours, then shut it down. Storage stays cheap. But here's the part they don't emphasize in training: if you fuck up warehouse auto-suspend settings, you'll pay for idle compute until you notice. We once had a developer leave a Large warehouse running after a late-night debugging session. Three days later: $1,200 bill for absolutely nothing.
What's New in 2025 (And What Actually Matters)

Gen2 Warehouses: The performance boost is real - we're seeing about 2x speedup on our analytics queries. Costs 25-35% more per credit, but queries finish faster so total cost is usually lower. But here's what the sales team won't tell you: we had to rewrite three ETL pipelines because Gen2 handles memory differently than Gen1. Our reporting warehouse that ran perfectly for 8 months suddenly started spilling to disk after the upgrade.
Adaptive Compute: Still in beta when we tested it. Marketing claims it's "intelligent auto-scaling" but it's actually pretty dumb. Works fine for boring ETL jobs but will fuck up anything with unpredictable patterns. The auto-scaling logic is about as sophisticated as a drunk intern making infrastructure decisions. Real example: during our holiday traffic spike, it spun up 6 Medium warehouses for a single user running SELECT COUNT(*) queries. That was a $400/hour mistake until we noticed. Check the sizing guidelines before enabling.
AI Stuff: Cortex lets you run LLMs directly on your data without moving it. Pricing is reasonable if you're not doing huge volumes. The vector search functionality is actually pretty good.
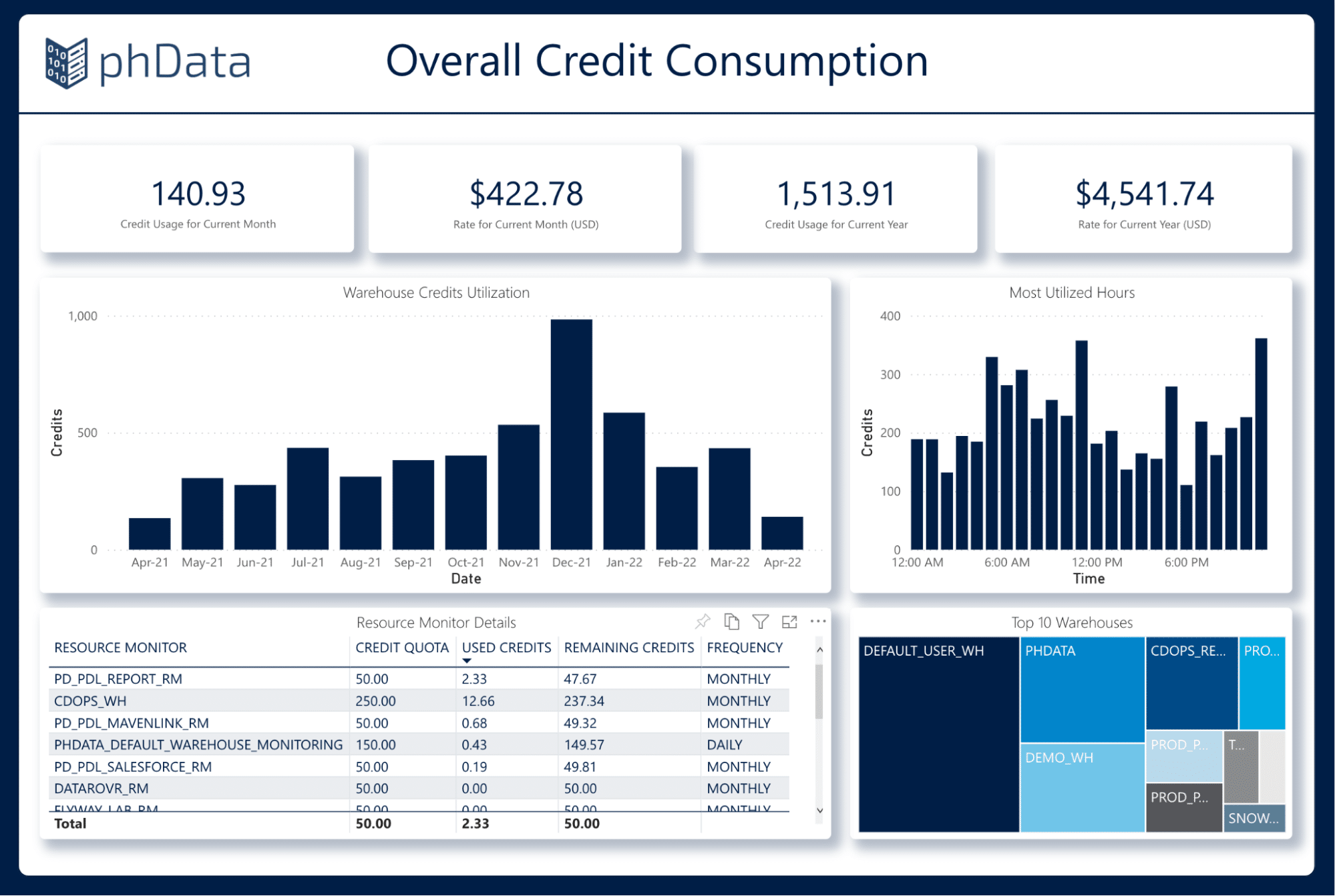
The Money Reality Check
Snowflake's $3.6B revenue isn't just hype - it's expensive but saves engineering time. Our total cost went up 40% vs. our old Oracle setup, but we eliminated two DBA positions and gained 10x more flexibility.
But let me tell you about the real cost surprises that'll wake you up at 3am:
The $8,000 Saturday: One of our analysts connected Power BI to production with a Large warehouse and auto-refresh set to every 15 minutes. She went home for the weekend. Monday morning bill: $8,127 for refreshing the same fucking dashboard 672 times with data that changed twice.
The clustering key disaster: We enabled auto-clustering on our main fact table without understanding the costs. $2,100/month to automatically organize a 50TB table that only got queried twice a week. Took us three months to notice because it wasn't labeled clearly in billing.
Current 2025 pricing by edition (per credit):
- Standard Edition: $2.00-$3.10 per credit
- Enterprise Edition: $3.00-$4.65 per credit
- Business Critical: $4.00-$6.20 per credit
- VPS: $6.00-$9.30 per credit
Real-world monthly costs I've seen in 2025:
- Small team (< 10 users): $500-2000/month (mostly Standard)
- Mid-size (50-100 users): $5K-25K/month (Enterprise+)
- Enterprise (500+ users): $50K-500K+/month (Business Critical+)
But those numbers are bullshit without context. Add 50% for "learning tax" - the mistakes you'll make while figuring out proper warehouse sizing, auto-suspend settings, and user training. Based on current market data, the median company pays around $92,000 annually, with buyers typically achieving 8% savings through proper negotiation.
Storage is cheap ($23/TB/month), compute will murder your budget if you're not careful. Set up resource monitors and billing alerts immediately. Like, day one, before you load any real data.
Multi-Cloud (If You Actually Need It)
The multi-cloud thing is real - we can share data between our AWS and Azure instances without copying it. But honestly, 90% of teams who think they need multi-cloud are just architecture astronauts making things complicated for no reason. Pick one cloud and stick with it. The only valid reasons for multi-cloud are compliance requirements or vendor negotiations (playing AWS against GCP for better pricing).
The data sharing across accounts is actually useful - we share cleaned datasets with our analytics vendor without giving them database access. The marketplace has some decent third-party datasets too.
No More 3AM Database Pages
Here's the real win: our Snowflake cluster hasn't woken me up at 3AM once. Compare that to our old Postgres setup that crashed monthly and our Oracle warehouse that required constant babysitting.
Auto-suspend works perfectly - warehouses shut down after 5 minutes of inactivity and restart in under a second. No more paying for idle compute because someone forgot to turn off a development environment.
The documentation is actually readable, which is rare for enterprise databases. Setup took us 2 weeks vs. 3 months for our previous Oracle migration. Their quickstart tutorials and community forums are surprisingly helpful too.