I've implemented CDC at three companies. Here's what actually happens and why you'll end up doing it too.
The Problem Everyone Hits
Your data team starts with nightly ETL jobs. Works great until:
- Business wants "real-time" dashboards (they mean 5-minute refresh, you know it means hours of debugging)
- Someone changes a database column and your entire pipeline dies at 3AM
- Users complain data is "stale" when it's only 6 hours behind
- You need to sync data between 5 different systems and each sync takes longer
How CDC Actually Works
Your database already logs every change to its transaction log - PostgreSQL calls it WAL, MySQL calls it binlog. CDC just taps into that stream and says "hey, this row changed, here's what happened." No queries hammering your production tables, no full table scans at 3am.

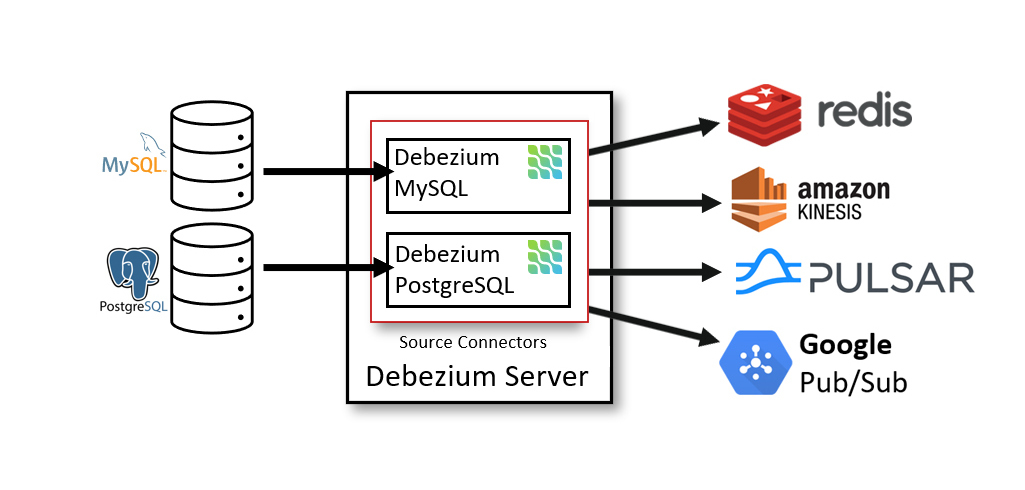
Three ways to actually implement this stuff:
Log-based CDC - The good shit. Read transaction logs directly. Works great if your database isn't ancient.
Trigger-based CDC - Database triggers fire on every change. Sure, it works everywhere, but watching your production queries slow to a crawl isn't fun.
Query-based CDC - Just poll for changes using timestamps. Simple as hell, but you'll miss deletes and it's not really real-time.
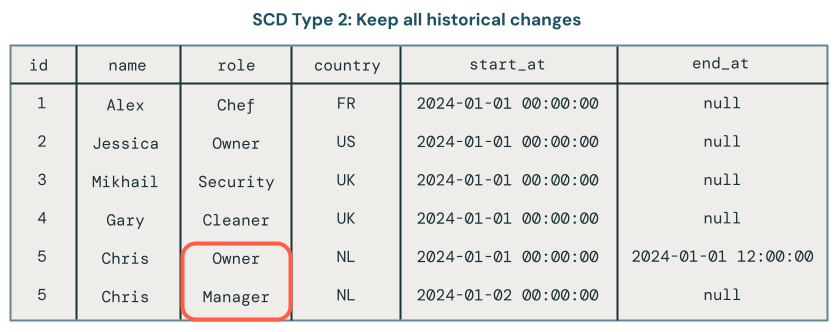
When CDC Actually Helps
CDC shines when:
- You have high-change tables that need to sync quickly
- Downstream systems can't wait for batch runs
- You need to replicate deletes (triggers and polling struggle with this)
- Source system can't handle heavy query load from ETL
When it doesn't help:
- Low-change tables (less than 1000 changes/day)
- Complex transformations (do those downstream)
- Compliance requires batch processing
- Legacy databases with shitty log access
The Real Implementation Pain Points
WAL Retention Hell: PostgreSQL WAL files will fill your disk if CDC falls behind. Set max_slot_wal_keep_size or you'll run out of space. I watched Ubuntu systems shit the bed when /var/lib/postgresql/data hits 95% - server just stops responding and you're SSH'ing in at 2am to clean up WAL files. This Stack Overflow post shows the exact problem that made me lose a weekend.
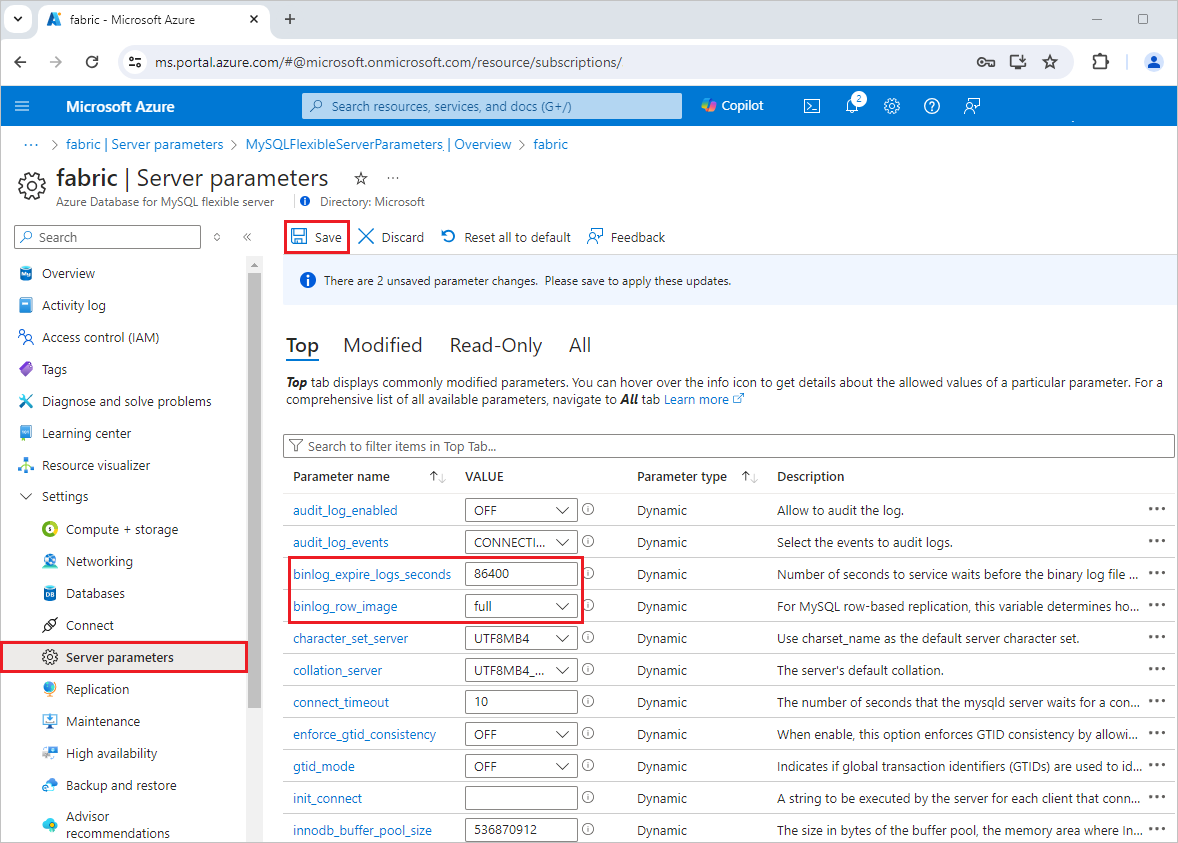
MySQL Binlog Position Tracking: Lose track of the binlog position and you're either missing data or reprocessing everything. Debezium MySQL connector docs explains position tracking but good luck finding the relevant section.
Schema Evolution: Adding a column is fine. Renaming or dropping columns will break your CDC pipeline in exciting ways. Debezium pain points blog covers what actually breaks in production.
Network Partitions: When your CDC process can't reach Kafka for 30 minutes, fun things happen to your lag metrics. Kafka Connect troubleshooting has the monitoring queries you'll need.


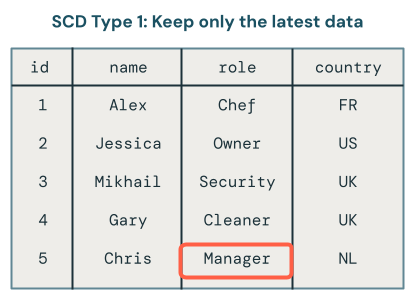
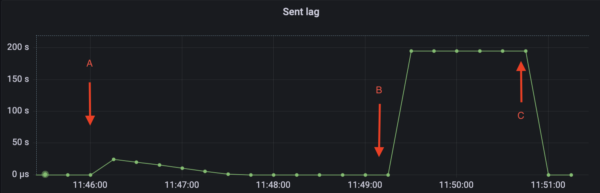 PostgreSQL WAL accumulation: If CDC falls behind, WAL files pile up. Set
PostgreSQL WAL accumulation: If CDC falls behind, WAL files pile up. Set