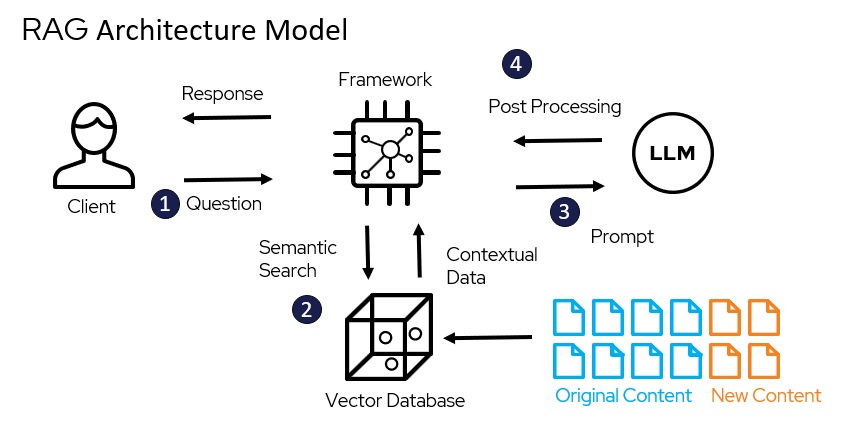
I've deployed this shit three times. Two worked okay, one was such a spectacular failure that I learned more debugging it than I did from the successful ones. Here are the patterns that don't completely fuck you over when your CEO asks "why is this so slow?" and your AWS bill is climbing faster than your startup's burn rate.
The "I Don't Want To Think About Infrastructure" Pattern
When to use this: Your traffic is all over the place and you're tired of babysitting servers
This pattern saved my ass during a Series A demo when our traffic spiked 50x overnight because some influencer mentioned us. Lambda scales automatically - 10 queries or 10,000, it just works. Pair it with Pinecone for vectors and whatever serverless database doesn't suck this week (spoiler: they all suck a little).

Architecture Components:
- Document ingestion: Lambda + S3 triggers
- Embedding generation: Modal for cost efficiency (way cheaper than OpenAI APIs)
- Vector storage: Pinecone serverless (starts cheap but scales fast)
- Retrieval + Generation: Lambda functions with vLLM endpoints
What actually happens: Cold starts will fuck you for the first few hundred milliseconds, but then it's smooth sailing. We went from spending 3 hours every morning scaling pods to just... not caring. Traffic spike during a product launch? Lambda handles it. Late night when everyone's asleep? You're not paying for idle containers.
When it breaks: Lambda times out after 15 minutes, so don't try processing massive PDFs in one go. Found this out when our demo died trying to process some massive PDF during a client meeting. Took us forever to figure out what was happening because Lambda just... stops. No error, nothing useful in the logs. Also, complex retrieval with 1000+ candidates will eat your memory allocation and you'll get cryptic OOM errors that make no sense.
Don't use this if: You need sub-200ms response times, you're processing massive documents, or your queries are consistently complex. Use ECS or Kubernetes instead.
The "We Have a DevOps Person" Pattern
![]()
When to use this: You need predictable performance and have someone who actually knows kubectl
This is the pattern large companies typically use. When you need predictable performance and have someone who actually knows Kubernetes YAML hell, this works. Just make sure that someone isn't you unless you enjoy debugging ingress controllers at 2am while your entire system is down.
Architecture Components:
- Ingestion pipeline: Airflow on Kubernetes for batch processing (prepare for YAML hell)
- Embedding service: SentenceTransformers with GPU pods (T4 if you're budget-conscious, A10 if you need speed)
- Vector database: Self-hosted Weaviate or Qdrant clusters
- API gateway: Istio with intelligent routing and caching (if you hate yourself)
What actually happens: We got latency under 500ms most of the time, but it took three months of tweaking HPA configs and arguing about resource limits. The GPU bill hurts - T4 instances aren't cheap - but at least your latency doesn't randomly spike when someone decides to batch-process their entire document archive.
Here's the reality: You need someone who lives and breathes kubectl. Expect 2-3 months of absolute misery setting up Istio service mesh, Prometheus monitoring, and cert-manager. But once it's running and you've sacrificed your sanity to the YAML gods, it just fucking works.
Essential tools: Helm charts, ArgoCD, Grafana dashboards, Jaeger tracing. Good luck learning all of these without wanting to throw your laptop out the window.
The "We Have Compliance People" Pattern
When to use this: Enterprise with HIPAA/SOC2 requirements and lawyers who get nervous about cloud data

The pattern that passes SOC2 audits combines on-premises document processing with cloud-based inference. Sensitive data never leaves the corporate network while still using cloud AI services for generation.
Architecture Components:
- On-premises: Document ingestion, chunking, and embedding using pgvector
- Secure tunnel: VPN or private cloud interconnect
- Cloud services: Azure OpenAI or Amazon Bedrock for generation
- Monitoring: OpenTelemetry with on-premises Prometheus stack
What actually happens: Network latency kills you - over a second average because your data has to hop through three different security layers. But when the HIPAA auditors show up, you sleep well knowing every query is logged and your sensitive docs never left the building.
Compliance tools: Falco runtime security, OPA policy engine, Vault secrets management.
Regulatory Benefits: Data residency compliance, complete audit trails, and air-gapped document processing. Essential for healthcare, finance, and government deployments.
The Anti-Patterns That Kill Systems
❌ The Monolithic API: Single container handling ingestion, retrieval, and generation
Why it fails: I've debugged this nightmare. Document processing slowly eats RAM until your container gets OOMKilled, taking down the entire API. One PDF parser bug crashes everything. Our monolith died on a busy shopping day when someone tried to upload a bunch of corrupted PDFs. Took us 2 hours to figure out it wasn't traffic - it was one bad document killing the whole damn thing.
Debugging tools: memory profiling with py-spy, container monitoring.
❌ The Everything-Custom Approach: Building vector databases and embedding models from scratch
Why it fails: "How hard can it be to build a vector database?" - famous last words. Spent 8 months building something that Pinecone or Weaviate does better out of the box. Don't reinvent the wheel unless you've got Spotify-level engineering talent.
❌ The Single-Framework Lock-in: Betting everything on one RAG framework
Why it fails: LangChain broke our production pipeline when they deprecated the entire chains API between 0.2 and 0.3. Spent two weeks rewriting everything because they decided to "improve" it. Had a production system serving 10K queries daily that just died overnight. LangChain's constant updates mean something breaks every month.
Choosing Your Architecture Pattern
Use Serverless if:
- Monthly query volume < 100K
- Cost optimization is the primary concern
- Your team lacks dedicated infrastructure expertise
- Traffic patterns are highly variable
Use Kubernetes if:
- Latency requirements < 500ms p95
- Monthly query volume > 500K
- You have dedicated DevOps resources
- Performance predictability matters more than cost
Use Hybrid Cloud if:
- Regulatory compliance requirements
- Sensitive document processing
- Existing on-premises infrastructure investment
- Air-gapped deployment requirements
The fundamental principle: start simple and add complexity only when simple stops working. Most RAG projects fail because teams try to build the perfect system instead of shipping something that works. Start simple with LangChain or LlamaIndex, get it working, then optimize. Premature optimization is the root of all evil - and bankrupted budgets.