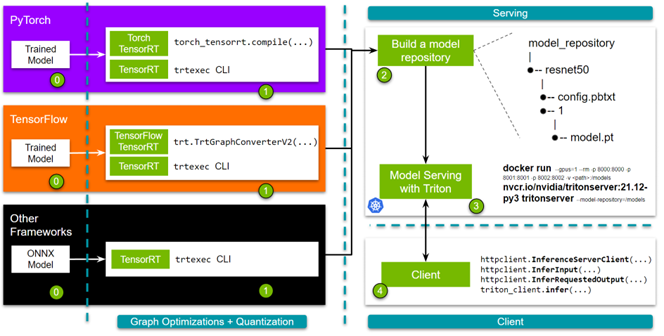
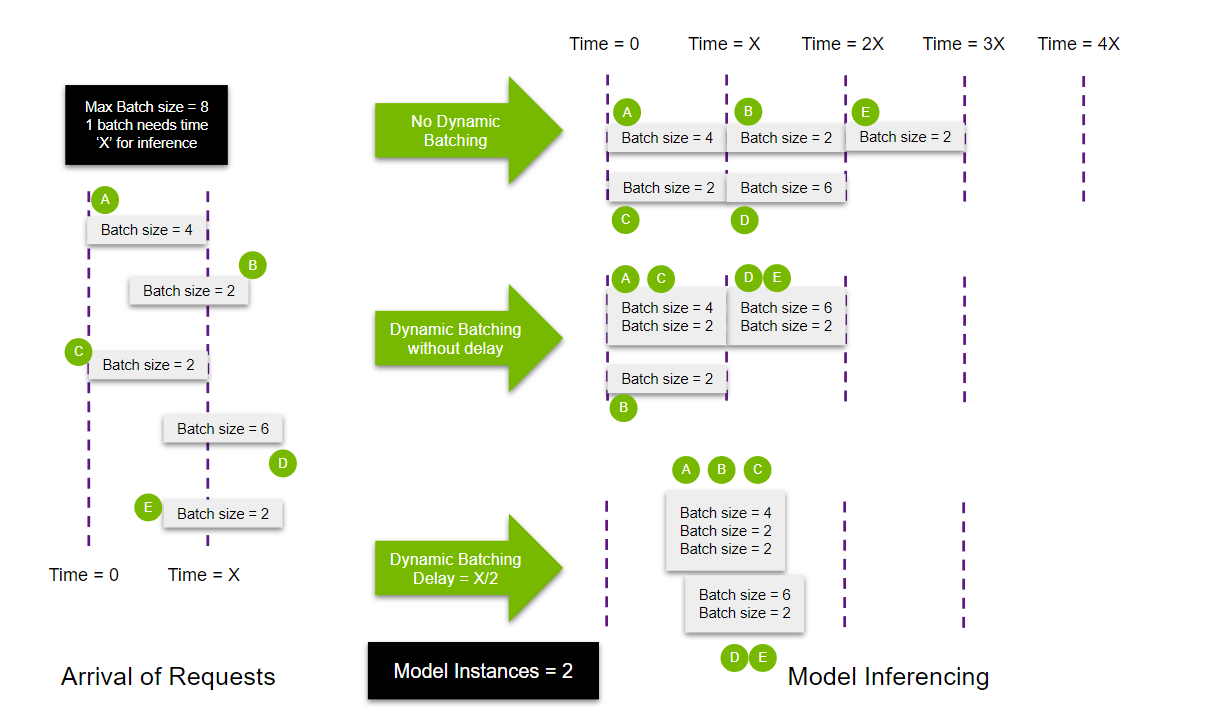
Dynamic batching sounds simple - batch requests, get better performance. Yeah, right. It's a memory-eating monster that will crash your server and leave you staring at CUDA out of memory errors during dinner while your family's calling you to come eat.
The Memory Problem Nobody Talks About
Dynamic batching works by collecting requests and batching them together. Simple enough. What the docs don't mention is that recent Triton versions have memory leaks where batched requests don't get garbage collected properly, especially with ONNX models.
We found this out the hard way when our production cluster started OOMing after like 6 hours? Maybe 8? I was half asleep. Memory usage would just climb until everything crashed. Found this GitHub issue that covers the same problem we hit. Fucking memory leaks everywhere.
Quick fix: Restart your Triton server every 4 hours with a cron job. Not elegant, but it works:
0 */4 * * * docker restart triton-server
Configuration That Actually Works
Skip the simple dynamic_batching { } - it'll use defaults that are garbage. Here's what we use in production:
dynamic_batching {
max_queue_delay_microseconds: 50000
preferred_batch_size: [4, 8]
max_queue_size: 256
}
Why these specific numbers work: max_queue_delay_microseconds: 50000 gives you 50ms to collect requests without users thinking your API is broken. preferred_batch_size: [4, 8] is the sweet spot for most transformers - smaller batches start processing immediately, larger batches actually improve throughput. max_queue_size: 256 stops the queue from eating all your fucking memory when traffic spikes.
Multiple Instances: More Complex Than It Looks
Multiple model instances sound like free performance, but they're memory hungry and the scheduler is dumb as hell. We tried 4 instances of a BERT model and the scheduler kept sending all requests to instance 0 while the others sat idle.
There was a round-robin scheduling bug that was supposedly fixed in earlier versions, but we still see uneven load distribution in current releases. Monitor your instances with nvidia-smi and you'll see what I mean.
Config that works:
instance_group [
{ count: 2, kind: KIND_GPU, gpus: [0] }
]
Start with 2 instances max. More than that and you're just asking for memory issues and debugging nightmares. The performance gains drop off hard after 2 instances anyway - this benchmark shows diminishing returns.
Real Performance Numbers (Not Marketing BS)
Here's what we actually see in production with a ResNet-50 model on an A100:
- Baseline (no optimization): ~380-420 infs/sec, P95 latency around 28ms
- Dynamic batching only: ~1150-1300 infs/sec, P95 latency 42-48ms
- Dynamic batching + 2 instances: ~1650-1850 infs/sec, P95 latency 52-58ms
- All optimizations + TensorRT: ~2200-2500 infs/sec, P95 latency 33-38ms
Don't believe the marketing bullshit about 300% improvements. Real gains are more like 100-150% if you're lucky and everything works perfectly.
Testing methodology: Used perf_analyzer with 16 concurrent clients, 10-minute runs, because anything shorter gives you bullshit numbers that don't reflect production load.
Debugging Tips That Would Have Saved Me Hours
When dynamic batching goes wrong (and it will), check these first:
- GPU memory usage:
nvidia-smi -l 1in another terminal while running tests - Queue depths: Enable Triton metrics and watch
nv_inference_queue_duration - Batch sizes: Log actual batch sizes - you'll be surprised how different they are from what you expect
- Memory profiling: If you're on PyTorch, memory snapshots help but they're a pain to set up
Most "performance" issues are actually memory problems in disguise. If your latency starts climbing after 30 minutes of load, you've got a memory leak somewhere.