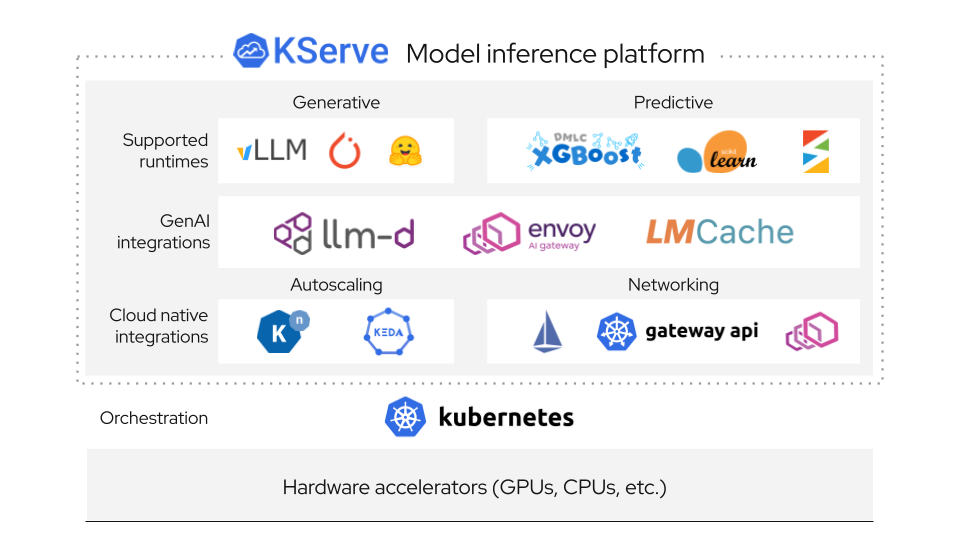
Before KServe, deploying ML models meant building custom serving infrastructure for every single model type. You'd write Flask APIs for scikit-learn models, deal with TensorFlow Serving's Byzantine configuration, and then panic when someone wanted to deploy a 7B parameter LLM that wouldn't fit in memory.
Originally called KFServing (part of the Kubeflow ecosystem), KServe became independent and joined the CNCF when people realized model serving was hard enough without being tied to a massive MLOps platform.
The Model Serving Nightmare
Here's what model serving looked like before KServe: Every team built their own Docker containers, wrote custom load balancing logic, and spent weeks debugging why their scikit-learn model worked locally but crashed in production with an OOMKilled error. Then someone would ask for A/B testing between model versions, and you'd spend another month building traffic splitting logic.
Add generative AI to this mess, and suddenly you need completely different infrastructure. Your traditional ML models need millisecond response times, but your LLMs need GPU scheduling, batch processing, and enough RAM to load a 13B model without crashing your entire cluster.
Kubernetes CRDs That Actually Make Sense
KServe uses Kubernetes Custom Resource Definitions to turn model deployment into a simple YAML file. Instead of writing 500 lines of Docker and Kubernetes configuration, you write:
apiVersion: serving.kserve.io/v1beta1
kind: InferenceService
metadata:
name: my-model
spec:
predictor:
sklearn:
storageUri: s3://my-bucket/model.joblib
That's it. KServe handles the networking, health checks, autoscaling, and all the operational crap that normally takes weeks to get right. You can deploy using kubectl or GitOps workflows, just like any other Kubernetes resource.
Both Traditional ML and LLMs (Finally)
Version 0.15 (released in early 2025) fixed the biggest pain point: supporting both traditional ML models and large language models in the same platform. Before this, you'd run KServe for your scikit-learn models and then cobble together something completely different for your Llama deployments.
Now you get OpenAI-compatible APIs for LLMs and traditional prediction endpoints for everything else. Same infrastructure, same monitoring, same headaches - but at least they're consistent headaches.
Production Reality Check
Companies like Bloomberg, IBM, Red Hat, NVIDIA, and Cloudera run KServe in production, which means it's battle-tested enough to handle real workloads. The GitHub repository has over 300 contributors and regular releases, suggesting it won't disappear next year.

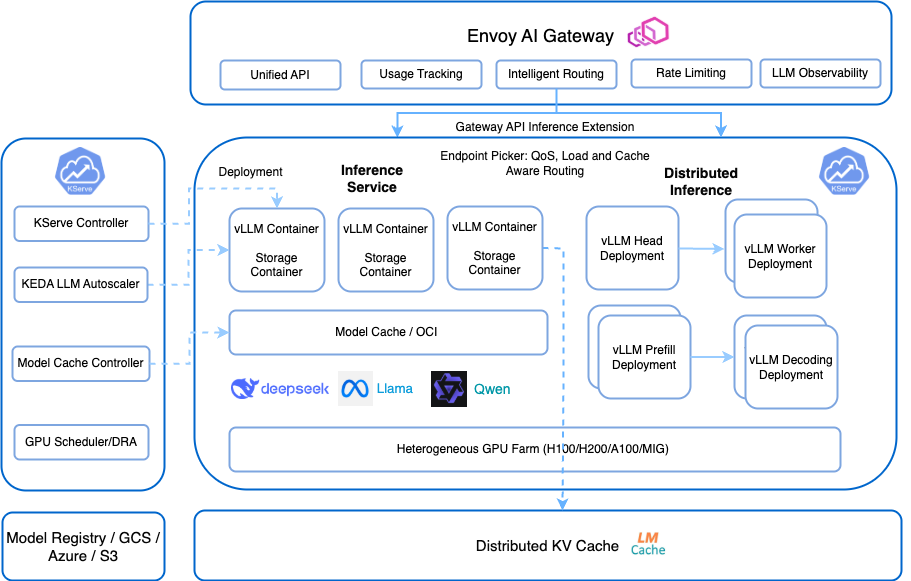
But here's the catch: KServe requires Kubernetes expertise. If your team is still figuring out pods and services, KServe will add another layer of complexity. Managed services like AWS SageMaker cost 3x more but keep your weekends free from Kubernetes debugging sessions.
Understanding how KServe actually works under the hood will help you decide if the complexity trade-off is worth it for your use case.