The day AI infrastructure security went to hell
August 4, 2025: I was debugging a completely unrelated memory leak when our security team started freaking out about some new Triton CVEs. "How bad could it be?" Famous last words. Turns out, pretty fucking bad - we had RCE vulnerabilities in something that was supposed to be "just" an inference server.
Still pissed about it, honestly. Here's what these idiots did to break our infrastructure, without the vendor marketing bullshit.
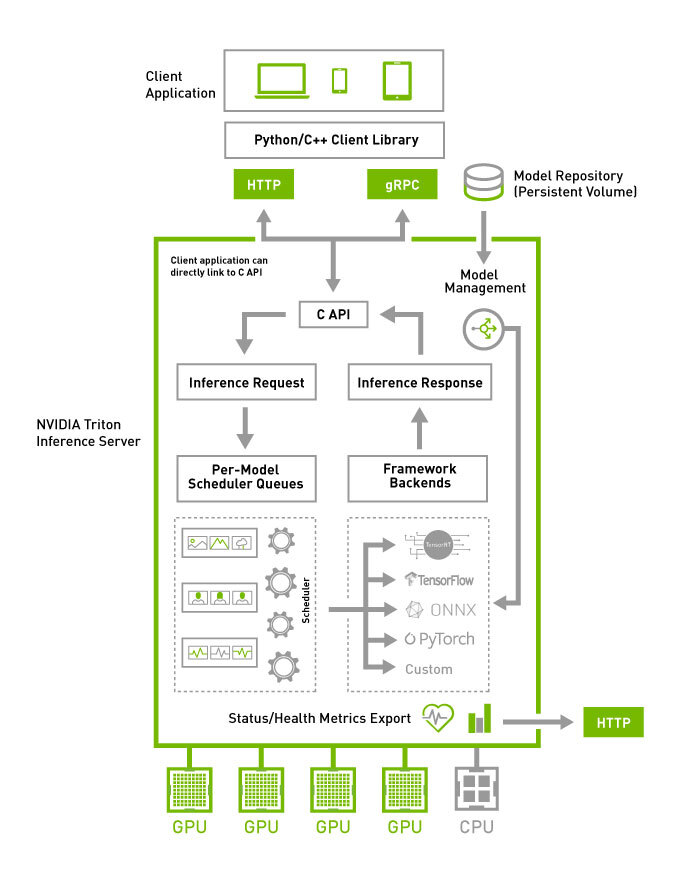
NVIDIA Triton's architecture - all those backend connections are potential attack vectors
The Actual Vulnerabilities (Not Marketing Speak)
The ones that fucked us:
- CVE-2025-23310 (CVSS 9.8): Stack overflow via chunked HTTP. Yes, chunked encoding. In 2025.
- CVE-2025-23311 (CVSS 9.8): More memory corruption in HTTP parsing because apparently we learned nothing from the 90s
- CVE-2025-23319 (CVSS 8.1): Python backend leaks shared memory names in error messages. Brilliant.
- CVE-2025-23320 (CVSS 7.5): Shared memory API lets you register internal memory regions. Who the fuck thought that was a good idea?
- CVE-2025-23334 (CVSS 5.9): Once you own shared memory, IPC exploitation gets you RCE
Real talk: Trail of Bits and Wiz Research didn't just find these bugs - they had working exploits. Not theoretical "maybe if you chain 17 different conditions" bullshit. Actual working code that could own your server. The National Vulnerability Database contains the full technical details, and CISA's Known Exploited Vulnerabilities Catalog now tracks these as actively exploited threats.
The Chunked Encoding Disaster (CVE-2025-23310/23311)
What actually broke:
Triton's HTTP handling had the classic mistake of trusting user input for stack allocation. Some genius decided alloca() was a good idea for parsing HTTP chunks:
// This is the actual code that fucked us (http_server.cc)
int n = evbuffer_peek(req->buffer_in, -1, NULL, NULL, 0);
if (n > 0) {
v = static_cast<struct evbuffer_iovec*>(
alloca(sizeof(struct evbuffer_iovec) * n)); // RIP stack
}
How the exploit works:
Send a bunch of tiny HTTP chunks. Each 6-byte chunk forces a 16-byte stack allocation. Do this enough times and boom - stack overflow. It's elegantly stupid.
Why this hurt in production:
- Something like 3MB of chunked garbage crashed the whole damn server. Took us hours to figure out it was the chunked encoding causing stack overflows.
- No auth needed, of course. Because someone thought default Triton config should just accept HTTP requests from anyone
- Every fucking endpoint was vulnerable:
/v2/repository/index, inference, model management - didn't matter which one you hit - Entire server goes down. Not a graceful 500 error, the whole process just dies and leaves you staring at container restart logs
I won't post the actual exploit code because I'm not an asshole, but the proof-of-concept was literally 20 lines of Python. Socket, chunked headers, loop sending 1\r A\r packets. That's it.
The Wiz Vulnerability Chain (CVE-2025-23319/23320/23334)
This one's actually clever (and terrifying):
Wiz found a three-stage exploit that starts with a minor info leak and ends with full RCE. It's the kind of attack that makes you question your life choices.
Stage 1: Oops, we leaked internal state (CVE-2025-23319)
Send a big request that triggers an error. The error message helpfully includes internal shared memory region names:
{\"error\":\"Failed to increase the shared memory pool size for key
'triton_python_backend_shm_region_4f50c226-b3d0-46e8-ac59-d4690b28b859'...\"}
Yeah, that UUID? That's supposed to be internal. Whoops.
Stage 2: "Your" memory is now my memory (CVE-2025-23320)
Triton has a shared memory API for performance optimization. Problem: it doesn't validate whether you're registering your memory or their memory. So you can just register that leaked internal memory region as if it's yours.
Stage 3: Welcome to the machine (CVE-2025-23334)
Now you have read/write access to the Python backend's IPC memory. From there you can corrupt function pointers, mess with message queues, and basically do whatever the fuck you want. RCE achieved.
Who Got Fucked and How Bad
Vulnerable versions: Everything up to 25.06 (July 2025). If you're running older versions, you're fucked. Check the NVIDIA Security Center for the complete list of affected versions and CVE details.
Fix: Triton 25.07 released August 4, 2025. Upgrade immediately or prepare for pain. The NVIDIA NGC Container Registry has the patched containers ready.
What was actually exposed in production:
- AWS SageMaker endpoints: Thousands of customer inference endpoints running vulnerable Triton
- Kubernetes clusters: Every default Triton Helm chart deployment was vulnerable
- Docker containers: Any
nvcr.io/nvidia/tritonserverimage before 25.07-py3 from the NVIDIA Container Registry - Edge deployments: Jetson devices running Triton were sitting ducks
The real damage: Companies with exposed Triton servers basically had their AI models sitting in a glass house with the door wide open. Model theft, data exfiltration, response manipulation - all on the table.

Vulnerability management lifecycle for AI infrastructure security
Timeline: From Discovery to Public Disclosure
- March 2025: Trail of Bits researcher discovers memory corruption during routine security audit
- May 15, 2025: Wiz Research reports vulnerability chain to NVIDIA
- May 16, 2025: NVIDIA acknowledges both vulnerability reports
- July 2025: NVIDIA develops patches and regression tests
- August 4, 2025: Coordinated public disclosure with patch release
- August 4, 2025: Both research teams publish technical details
Post-Disclosure Reality Check
Immediate industry impact:
- Major cloud providers issued security advisories within 24 hours
- Enterprise AI deployments initiated emergency patching cycles
- Security scanning tools updated signatures for vulnerable containers
- NVIDIA security bulletin became the most accessed document in company history
Long-term implications:
- Trust erosion: First major RCE vulnerabilities in production AI infrastructure
- Security requirements shift: Organizations now mandate security reviews for AI inference platforms
- Regulatory attention: Government agencies initiated reviews of AI infrastructure security
- Industry standards: New security frameworks specifically for AI model serving platforms
Lessons from the August 2025 Crisis
What went wrong:
- Basic memory safety issues in performance-critical HTTP handling code
- Insufficient input validation on public APIs
- Information disclosure through verbose error messages
- Lack of sandboxing between user and internal components
What went right:
- Coordinated disclosure process worked effectively
- NVIDIA responded rapidly with comprehensive patches
- Security community collaborated on impact assessment
- Regression tests implemented to prevent similar issues
The August 2025 vulnerabilities represent a inflection point for AI infrastructure security. Organizations that treat AI inference servers as "just another application" learned that these systems require specialized security expertise and ongoing vigilance. The sophistication of the Wiz vulnerability chain demonstrates that AI infrastructure faces advanced persistent threats, not just script kiddie attacks.
Critical takeaway: These vulnerabilities existed for years in production systems processing sensitive data and valuable AI models. The discovery timeline suggests that well-resourced attackers may have found and exploited these flaws before public disclosure. Every organization running Triton needs immediate security assessment, not just patching.
 Defense-in-depth approach for AI infrastructure security
Defense-in-depth approach for AI infrastructure security Kubernetes cluster architecture showing control plane and worker nodes for secure container orchestration
Kubernetes cluster architecture showing control plane and worker nodes for secure container orchestration Container security best practices for protecting AI inference workloads
Container security best practices for protecting AI inference workloads SIEM dashboard showing real-time threat detection and incident response for AI infrastructure
SIEM dashboard showing real-time threat detection and incident response for AI infrastructure NIST incident response lifecycle adapted for AI infrastructure security
NIST incident response lifecycle adapted for AI infrastructure security