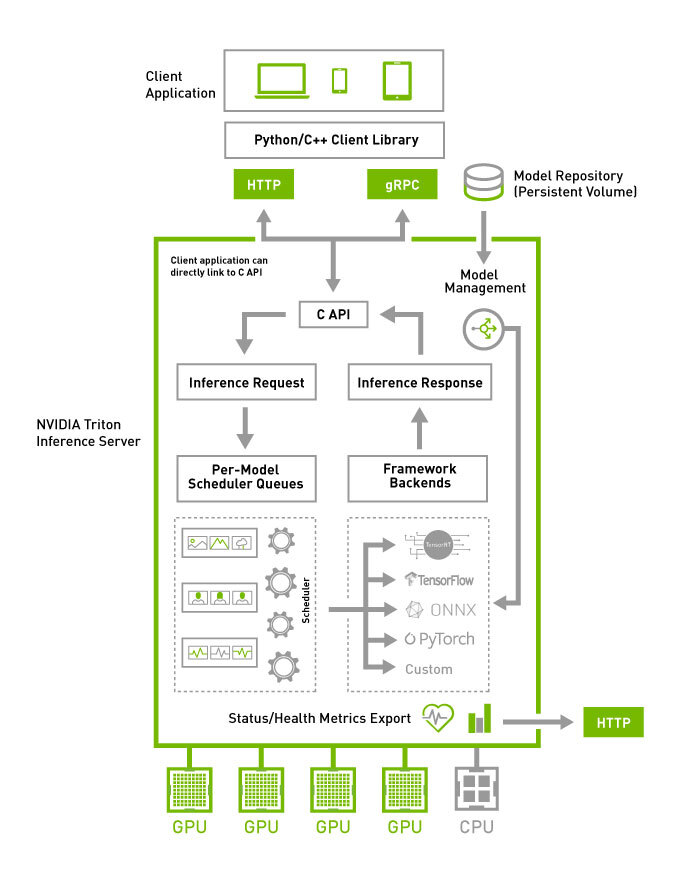
TorchServe was Facebook and AWS's attempt to solve "how do I put this PyTorch model into production without writing a REST server from scratch?" And honestly? It worked pretty well.
Current Status (The Real Story): TorchServe shows "Limited Maintenance" on the GitHub repository. They're not actively adding features or fixing bugs, but they haven't nuked it completely either. Latest release is 0.12.0 from September 2024. Bottom line: if you're starting a new project in 2025, pick something else.
What TorchServe Actually Did Right
The architecture was Java-based (yes, Java) with Python handlers for your actual model code. This sounds weird but actually worked - the Java layer handled HTTP, threading, and memory management while Python did the ML stuff.
Model Management API: You could load/unload models without restarting the server. Big deal for production where you can't have downtime. The Model Archive (MAR) format bundled everything - model, dependencies, custom code - into one deployable file. No more "works on my machine" bullshit.
Batching That Worked: Dynamic batching actually functioned properly, unlike some other frameworks where you spend weeks tuning batch sizes. TorchServe figured out optimal batching automatically based on your hardware and model characteristics.
Zero-Config Metrics: Prometheus metrics came out of the box. Memory usage, request latency, model-specific metrics - all there without writing monitoring code. This saved weeks of instrumentation work.
What actually worked:
- Dynamic batching that didn't suck
- Multi-model serving without memory leaks
- Prometheus metrics without writing monitoring code
- Docker containers that started without 20 minutes of dependency debugging
Where It Got Deployed (And Why)
TorchServe became the default on major platforms because it was the only PyTorch-specific solution that didn't suck:
- AWS SageMaker integration - native support, no containerization hell
- Google Vertex AI runtime - worked without custom Docker builds
- KServe compatibility - plugged into Kubernetes without yaml nightmares
Real companies used it for real things: Walmart's search, Naver's cost reduction, Amazon Ads scale.
Technical Gotchas (Learned the Hard Way)
Python 3.8+ required - sounds obvious but caused deployment failures when prod systems were still on 3.7.
Java memory issues were the fucking worst - default heap size would OOM during BERT model loading with java.lang.OutOfMemoryError: Java heap space. Zero context about what was actually eating memory. Took us a week to figure out we needed -Xmx8g minimum for BERT-large models. Had to dig through Java GC logs like some kind of archaeology project to figure out the JVM was running out of heap during model deserialization.
Custom handlers were a nightmare - writing custom preprocessing/postprocessing meant learning both the Python handler interface and Java serialization weirdness. Documentation examples worked for toy datasets but fell apart with real production data. Spent 3 days debugging why image preprocessing worked locally but threw serialization errors in the container.
Linux-first mentality - Windows and Mac support was experimental at best. Docker on Mac had memory allocation issues that didn't reproduce on Linux.
The 0.12.0 release added security token authentication enabled by default, which broke existing deployments with cryptic HTTP 401 Unauthorized errors. Spent 2 hours debugging why our health checks suddenly returned auth errors before finding the changelog buried in their docs.