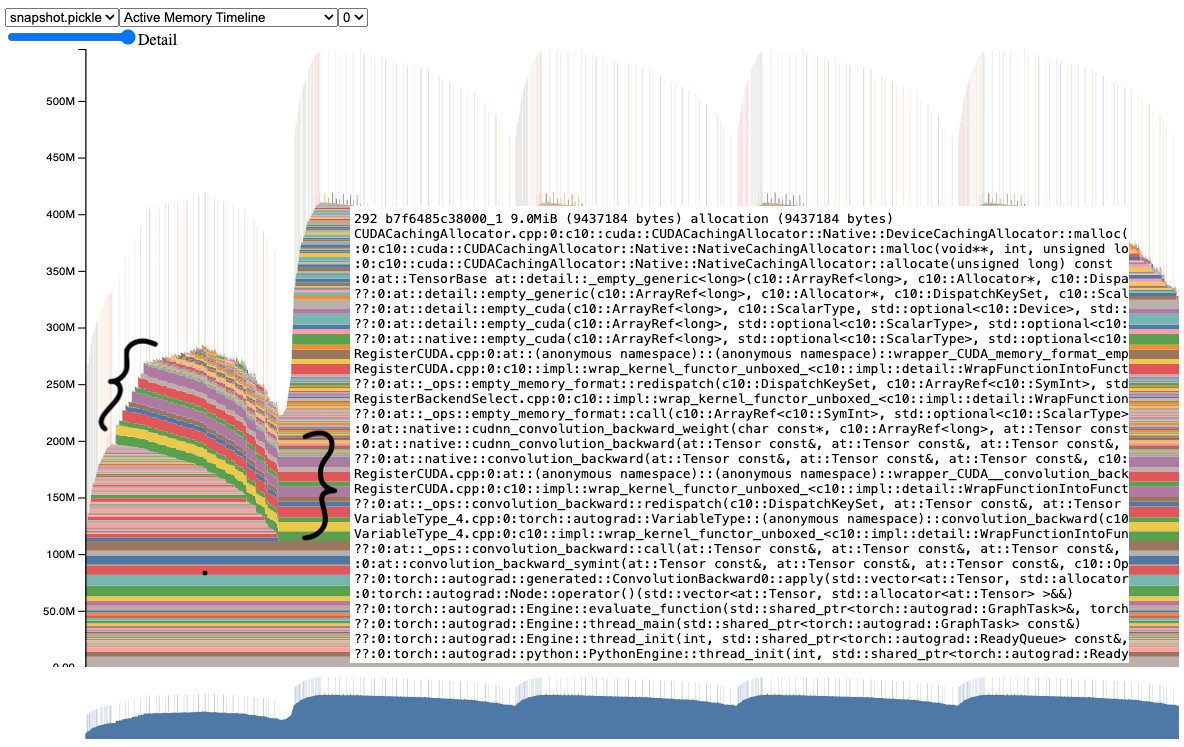
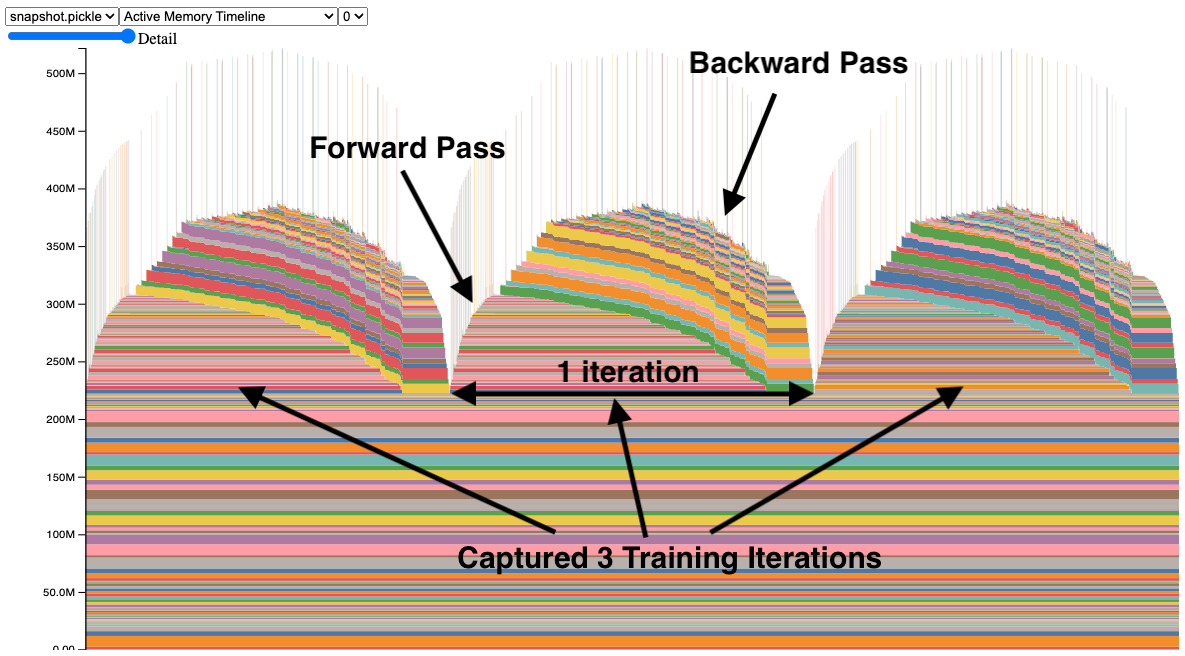
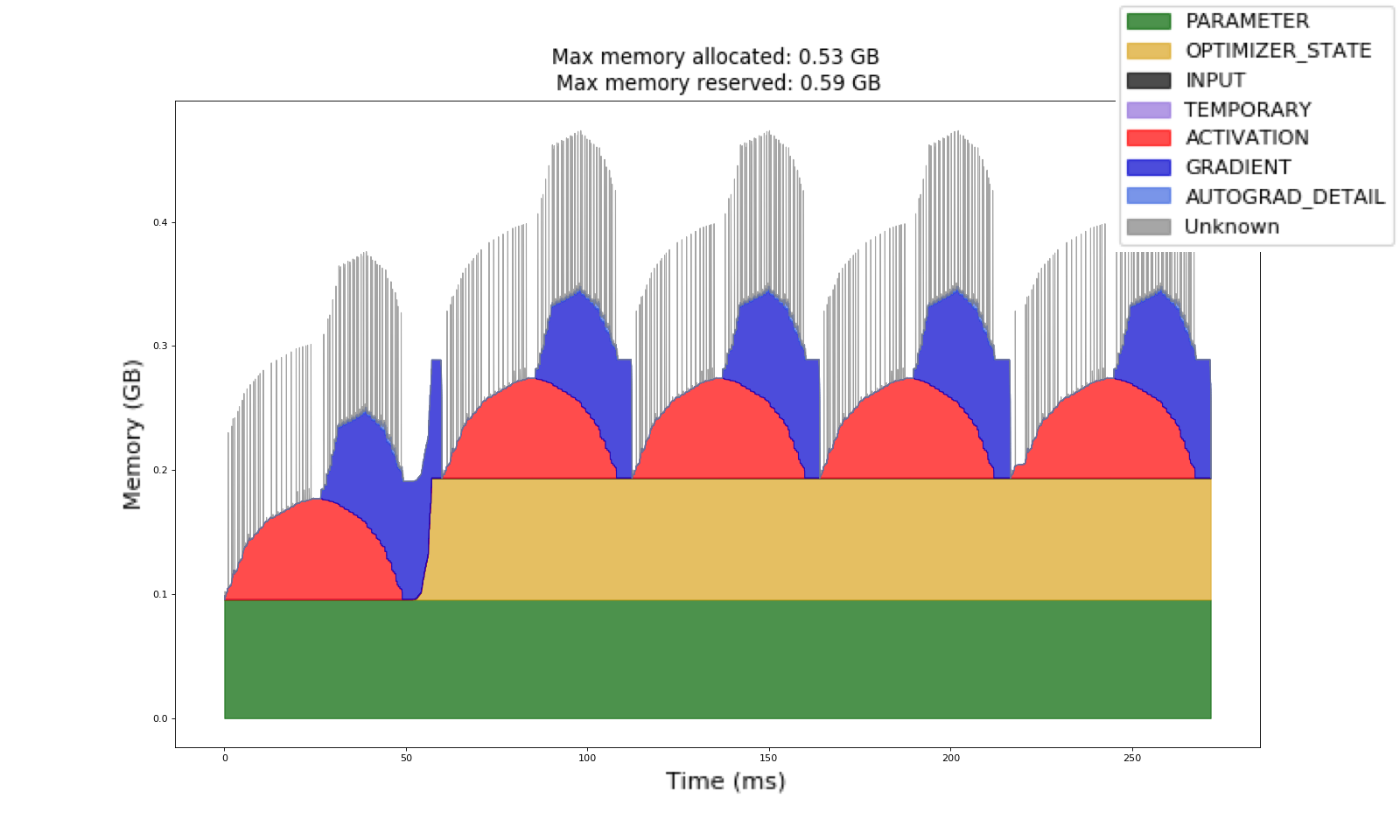
Here's the thing about PyTorch production deployments: most blog posts show you toy examples with single models and perfect conditions. Real production looks different.
The Memory Leak Nightmare
PyTorch has memory leaks in production. Not maybe, not sometimes - it has them. I've seen GPU memory leaks with torch.nn.Linear that accumulate over days until your serving crashes with OOM errors. The community pretends these don't exist, but go check GitHub issues - there are hundreds of them. The CUDA memory management documentation explains how to visualize memory allocation patterns, but doesn't solve the fundamental leak issues in long-running inference services.
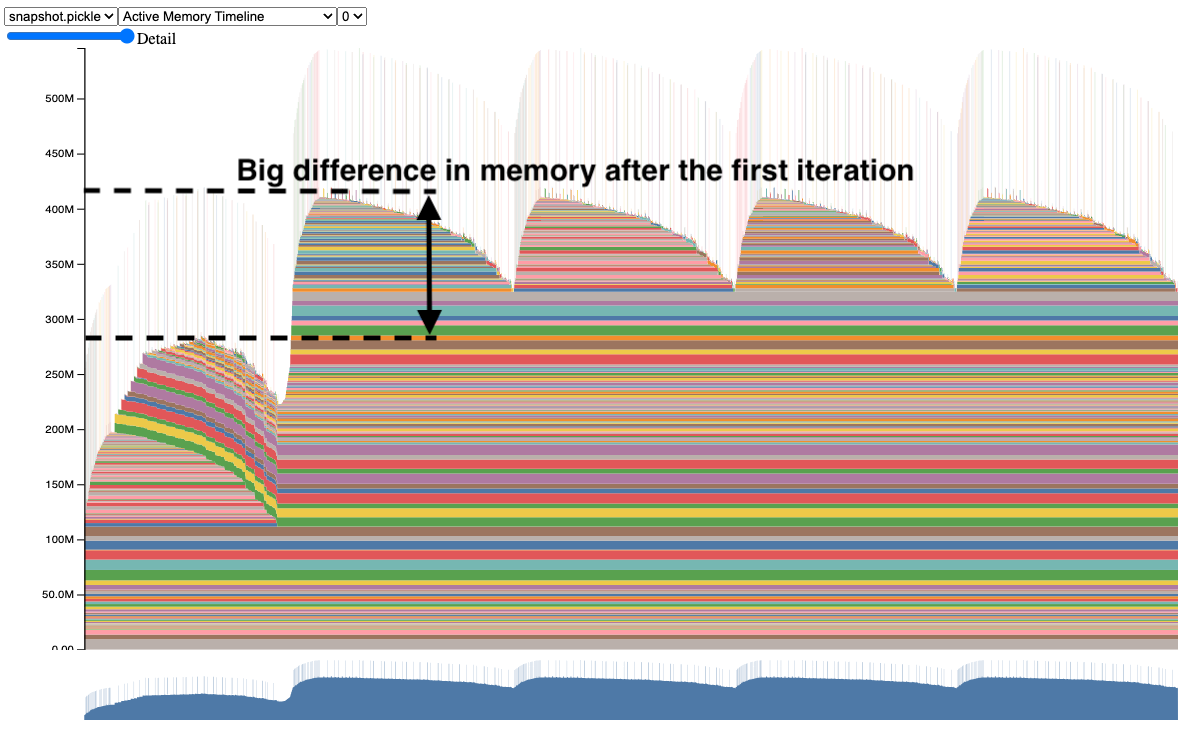
Memory profiler visualization showing GPU memory allocation over time - notice the gradual memory accumulation from leaks
The solution? Restart your workers regularly. Don't fight the memory leaks, manage them:
## This saved my production deployment
MAX_REQUESTS_PER_WORKER = 1000
WORKER_RESTART_INTERVAL = 3600 # 1 hour
## In your serving config
gunicorn --max-requests ${MAX_REQUESTS_PER_WORKER} \
--max-requests-jitter 100 \
--timeout 120 app:application
TorchServe vs FastAPI: The Real Performance Numbers
Everyone debates TorchServe vs FastAPI for serving PyTorch models. I've benchmarked both extensively. The model deployment landscape in 2025 includes multiple options, and TorchServe remains a popular choice for PyTorch-specific serving workflows:
TorchServe is better for:
- Multi-model serving (version management, A/B testing)
- Built-in batching and auto-scaling
- Model archiving and deployment workflows
FastAPI is better for:
- Simple single-model serving
- Custom preprocessing/postprocessing
- Debugging (you can actually step through the code)
- Lower latency for simple models (50-100ms faster)
Performance comparison showing TorchServe vs FastAPI latency and throughput under different load conditions
In practice, I use FastAPI for prototypes and simple models, TorchServe for complex multi-model production setups. Don't use TorchServe unless you need its specific features - the complexity isn't worth it for basic serving.
torch.compile in Production: When It Helps vs When It Hurts
torch.compile can give you 1.5-2x speedups, but it comes with production gotchas:
The Good:
- Real speedups for transformer models (I've seen 40% faster inference)
- Works well with static input shapes
- Reduces memory usage for some models
The Bad:
- Compilation happens on first inference (cold start penalty)
- Breaks debugging completely (issue #97224)
- Memory usage can actually increase with dynamic shapes
- Compilation errors are cryptic as hell
## Production pattern: compile after warmup
@torch.no_grad()
def load_and_warmup_model():
model = MyModel()
model.load_state_dict(torch.load('model.pth'))
model.eval()
# Warmup with expected input shape
dummy_input = torch.randn(1, 3, 224, 224)
for _ in range(10): # Warmup runs
_ = model(dummy_input)
# Now compile for production
if not DEBUG_MODE:
model = torch.compile(model, mode=\"max-autotune\")
return model
Memory Optimization That Actually Works
The 7 hidden memory techniques everyone talks about are mostly academic bullshit. Here's what actually reduces memory usage in production:
1. Gradient Checkpointing (saves 30-50% memory):
from torch.utils.checkpoint import checkpoint
class CheckpointedModel(nn.Module):
def forward(self, x):
return checkpoint(self.heavy_layer, x)
2. Mixed Precision (halves memory usage):
## This actually works and is stable
from torch.cuda.amp import autocast
with autocast():
output = model(input) # Automatically uses FP16 where safe
3. Manual Memory Management (essential for long-running services):
## Call this between batches in long-running services
def cleanup_gpu_memory():
if torch.cuda.is_available():
torch.cuda.empty_cache()
torch.cuda.ipc_collect()
Don't bother with activation offloading or parameter partitioning unless you're training massive models. For inference, these techniques add complexity without meaningful benefits.

Production PyTorch optimization pipeline showing graph transformations and performance improvements