Look, I've been through the pain of running Pinecone alongside PostgreSQL with pgvector, and it's exhausting. You spend half your time making sure the vectors match the actual data, and the other half debugging sync failures at 2am. MongoDB Atlas Vector Search puts everything in one place so you don't have to keep two databases from drifting apart.
Having Everything in One Database Actually Matters
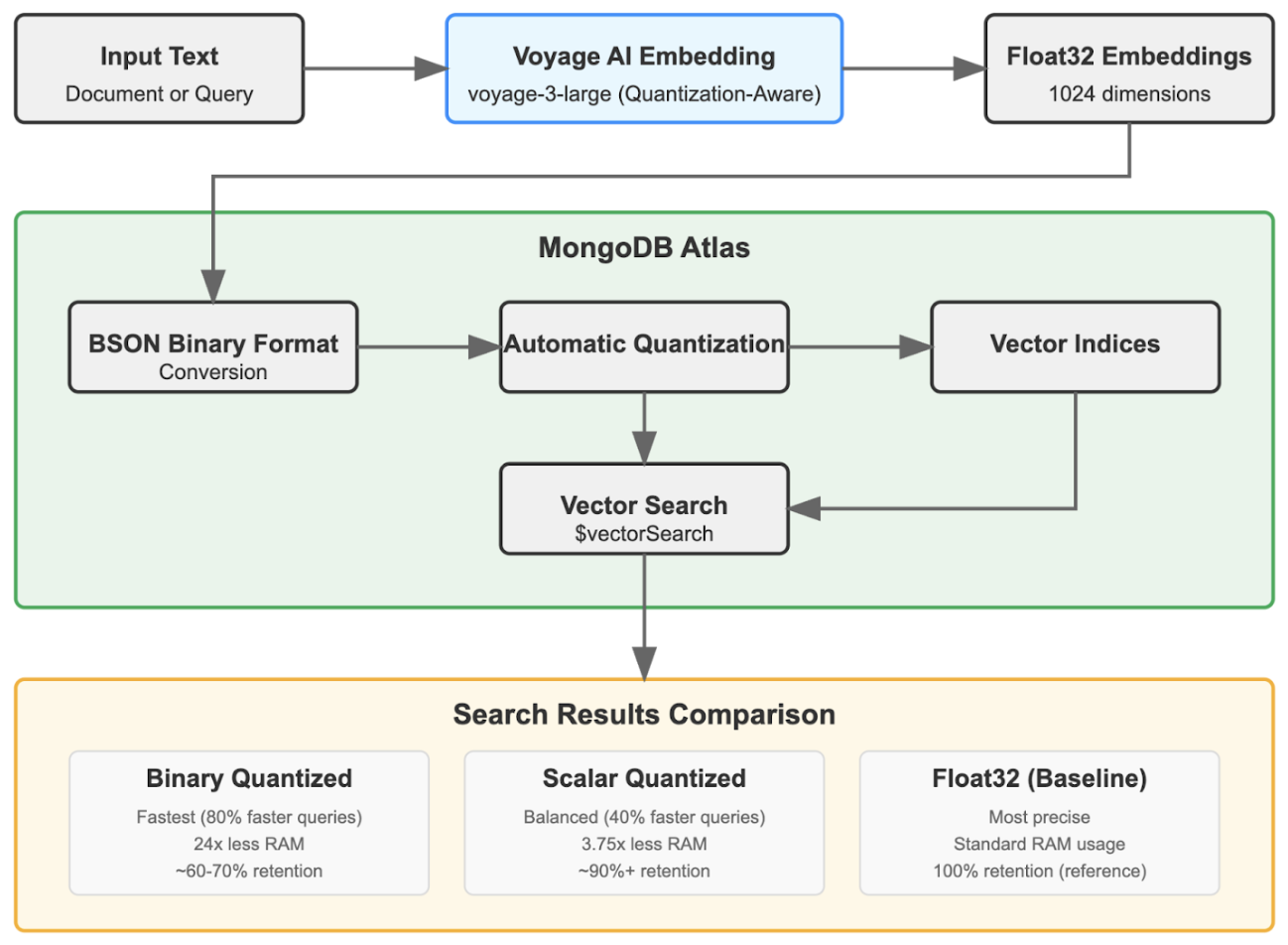
Your product data and its vector embeddings live in the same MongoDB document. When your product catalog updates, the vectors update in the same transaction. No more writing ETL jobs to sync data between your main database and Qdrant or Weaviate. No more discovering that half your vectors are stale because someone forgot to update the sync job.
I learned this the hard way trying to keep Supabase pgvector in sync with a separate API database. The vectors would drift, search results would get weird, and you'd spend hours figuring out which data was newer. With Atlas, your vectors update atomically with your data because they're literally in the same document.
You Don't Need to Learn New Security Bullshit
If you're already running MongoDB, Atlas Vector Search uses the same security model you know. Same RBAC, same encryption, same audit logs. You don't have to figure out how Milvus handles authentication or whether ChromaDB even has proper user management.
Most vector databases treat security as an afterthought. Pinecone has API keys and that's about it. Good luck explaining to your security team why your vector data doesn't have the same access controls as your user data. With Atlas, it's all the same system.
Search Nodes Cost Extra But Prevent Your App From Dying
Search Nodes are MongoDB's way of saying "pay extra so vector search doesn't make your database slow as hell." Vector similarity calculations eat CPU and RAM like Chrome eats battery. Without dedicated nodes, a heavy vector search can make your API timeouts spike.
With pgvector on PostgreSQL, you're stuck - vector queries compete with your normal database operations for the same resources. Your checkout process slows down because someone's doing similarity search on product images. Search Nodes fix this by isolating the workloads, but they cost extra and the pricing gets complicated fast.
Quantization Works Until It Doesn't
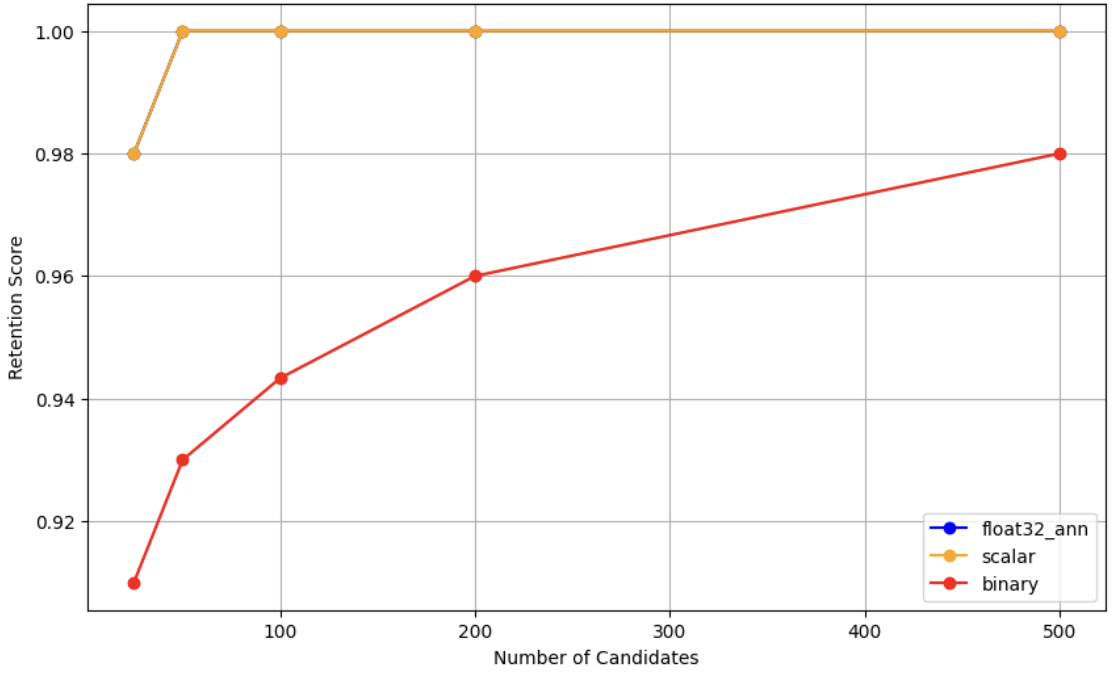
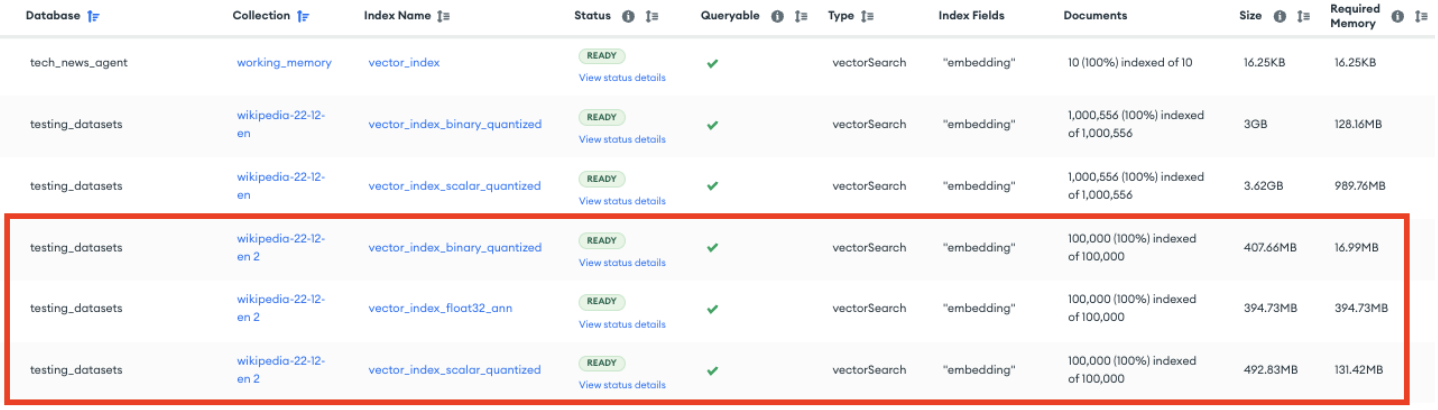
MongoDB's quantization compresses your vectors and prays the search quality doesn't suck. The numbers look great - 3.75x memory reduction with scalar quantization, 24x with binary quantization - but it depends entirely on your embedding model not being garbage at low precision.
The 95% recall retention only works with specific models like Voyage AI's voyage-3-large that were trained with quantization in mind. Use OpenAI's text-embedding-ada-002 with binary quantization and your search results will turn to shit. Test thoroughly before enabling this in production, because "order-of-magnitude cost reductions" mean nothing if users can't find what they're looking for.
HNSW Algorithm Is Magic I Don't Understand But It's Fast
MongoDB uses HNSW (Hierarchical Navigable Small World) for approximate nearest neighbor search, the same algorithm everyone else uses. It's basically magic math that builds a graph structure to find similar vectors without checking every single one.
The nice thing about Atlas is you don't have to tune the HNSW parameters yourself. With Faiss or Annoy, you spend hours figuring out numCandidates and efConstruction values. MongoDB picks defaults that work for most cases, though you can still manually tune them if you need to squeeze out more performance.
Hybrid Search Actually Works (Unlike Most Vector DBs)
Most vector databases suck at filtering. You search for similar vectors, get back 10,000 results, then filter by metadata and end up with 3 matches. MongoDB's query planner can combine vector similarity with normal MongoDB queries like {category: "electronics", price: {$lt: 100}} without scanning every vector first.
This matters when you're building real applications. Your users want "find me similar red shoes under $50," not "find me the most similar items globally then hope some are red shoes under $50." With Pinecone or Weaviate, you either pre-filter and hurt recall or post-filter and hurt performance.
LangChain Integration Actually Works
Atlas has native support for LangChain, LlamaIndex, and Haystack. The MongoDB team maintains these integrations themselves, so they don't break every time someone updates a dependency.
Compare that to trying to get ChromaDB working with LangChain version 0.2.x - half the examples on Stack Overflow don't work because the API changed. With Atlas, the integration code stays stable and gets updated alongside new MongoDB features.
Bottom line: If you're already using MongoDB for your app data and need to add vector search, Atlas makes sense. You don't have to learn Qdrant's API or figure out how to scale Milvus. But if you're starting fresh and performance matters more than convenience, Pinecone is still faster for pure vector workloads, even if it costs 3x more.
Some links that might help: MongoDB's HNSW implementation details, vector quantization research, BSON binary vector format specs, Atlas Search Node architecture, and the official MongoDB Vector Search tutorial.