
MongoDB Connection Pool Architecture Overview
Application requests → Connection pool → MongoDB cluster: Understanding this flow is essential for debugging topology errors

Understanding how MongoDB manages connection pools is crucial for preventing topology errors

MongoDB Connection Pool Architecture Specification (CMAP) - Shows connection lifecycle from creation to cleanup
MongoDB topology errors happen when the driver gives up on your database connection. I've debugged these errors hundreds of times - they're usually not what you think they are.
The Real Culprits Behind Topology Destruction
Connection Pool Exhaustion (The #1 Killer)
Your default connection pool has 100 connections, which sounds like a lot until your app tries to use 101 at the same time. I've seen production apps hit this limit in under 5 seconds during traffic spikes. When every connection is busy and new requests timeout waiting for one to free up, the MongoDB driver gives up and destroys the topology.
The MongoDB docs suggest using 110-115% of your expected concurrent operations, but that's useless advice when you don't know your real concurrency patterns. Here's what actually works: Start with 10-15 connections and monitor pool utilization. Most apps never need more than 20.
Network Timeouts (The Silent Killer)
Your network isn't as stable as you think. Firewall rules change, load balancers get reconfigured, AWS has a bad day. The MongoDB driver waits for connectTimeoutMS (defaults to infinite, which is insane) and eventually gives up.
Pro tip: Set a reasonable connection timeout like 30 seconds. Infinite timeouts just make your app hang forever instead of failing fast and retrying.
Your App Running Out of Resources (Most Embarrassing)
When your Node.js app maxes out CPU or memory, it can't process MongoDB responses fast enough. The driver thinks the database died and clears the connection pool. This Stack Overflow thread has 20+ devs who discovered their "database error" was actually their app choking on itself.
Check htop during failures - bet you're pegging CPU at 100%.
Premature Connection Closing (Classic Junior Dev Mistake)
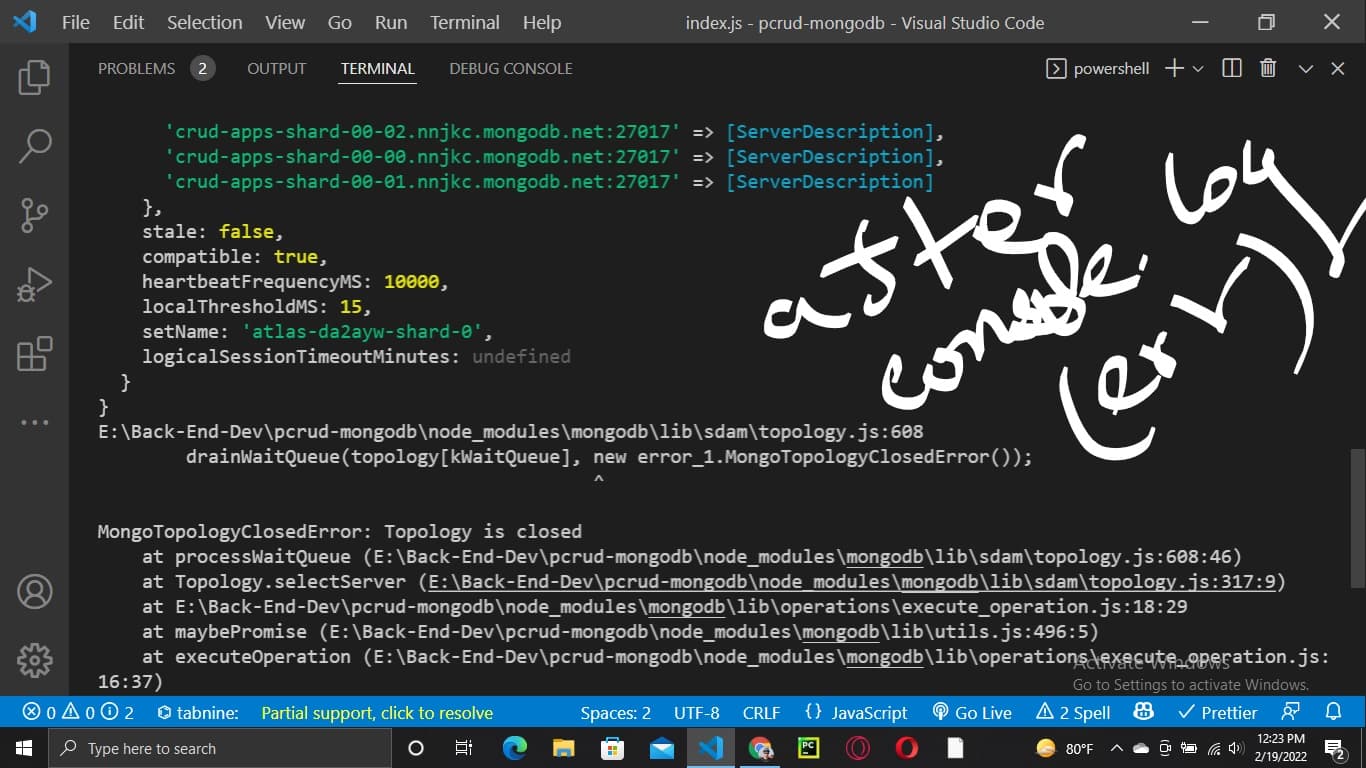
You call mongoose.disconnect() in your test cleanup or app shutdown, but there are still operations in flight. MongoDB driver freaks out because you killed connections while they were working. This GitHub issue shows exactly why this happens and how to fix it.
Always wait for pending operations before disconnecting. Here's the pattern that actually works.
How Connection Pools Actually Work (The Real Version)
Connection pools are shared across all operations from a single MongoClient instance
Each MongoClient gets its own connection pool. Here's what MongoDB doesn't emphasize enough:
- Pool starts empty - connections created on demand (most people don't know this)
- Connections get reused - same connection handles multiple operations
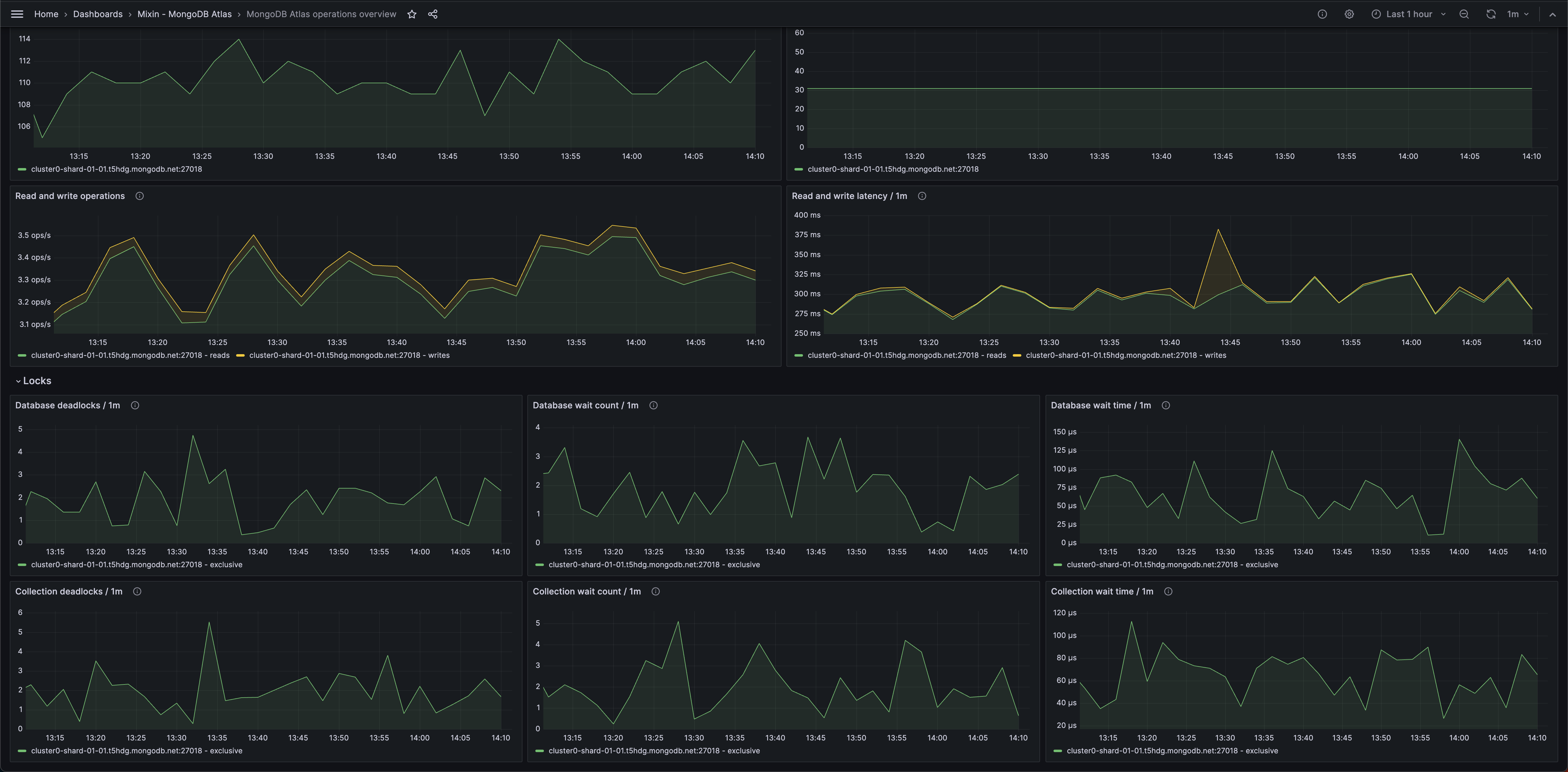
- Pool monitoring runs constantly - driver pings connections to verify they're alive
- Pool clearing is nuclear - when shit hits the fan, driver dumps ALL connections
The problem isn't the pool mechanics - it's that your app creates more concurrent operations than the pool can handle. You queue up 50 database calls, but only have 10 connections. The remaining 40 operations wait in line until timeout kicks in and everything explodes.
This production case study shows how a 12-connection pool handled 500 concurrent users just fine, but died under 1000 users because of poor connection management patterns.
Driver Versions Matter More Than You Think
Old Drivers (pre-4.0) Are Trash
If you're still using MongoDB driver 3.x, you're fucked. These drivers give up permanently on topology errors and require app restarts. Upgrade to 6.18.0 - the current version as of August 2025 - or accept that your app will need manual intervention every time connections fail.
Modern Drivers (6.x) Actually Try to Recover
The latest Node.js driver 6.18.0 (July 2025) has automatic retry logic and better connection pool monitoring. They can survive temporary network hiccups without dying completely. The built-in monitoring helps you see connection failures before they kill your topology.
Mongoose Can Make Things Worse
Mongoose adds its own connection management layer on top of the MongoDB driver. Sometimes this helps by providing buffering and automatic reconnection. Sometimes it makes recovery slower because there are now two layers trying to manage connections. Current Mongoose 8.18.0 works with MongoDB driver 6.18.0, but version compatibility matters.
I've seen Mongoose 6.x paired with older MongoDB drivers create race conditions during reconnection. The Mongoose connection docs cover this better now, but you still need to verify compatibility between Mongoose and the underlying driver version.
The Connection Settings That Actually Matter
Stop cargo-culting connection settings from random tutorials. Here's what you actually need to configure:
maxPoolSize: 10-20- Not the default 100, that's insane for most appsconnectTimeoutMS: 30000- 30 seconds, not infinite (seriously, who thought infinite was a good default?)serverSelectionTimeoutMS: 5000- Don't wait forever for MongoDB to pick a serverheartbeatFrequencyMS: 10000- Check connections every 10 seconds
The key isn't having perfect settings - it's implementing proper error handling that handles temporary failures gracefully. This Medium article shows the most common production mistakes that lead to topology errors.
If you're running in Kubernetes, resource limits and DNS resolution delays can amplify these issues. Container memory limits that are too small will cause topology errors when your app runs out of memory during connection pool management.
The Bottom Line: Most topology errors come from your app, not MongoDB. Connection pool exhaustion and resource starvation are the #1 and #2 causes. Network issues and driver bugs come third.
Now that you understand the real culprits, it's time to fix them. The next section covers emergency triage steps that get you back online in under 5 minutes, plus the exact configuration settings and debugging techniques that prevent these errors from happening again.
 *Mongo
*Mongo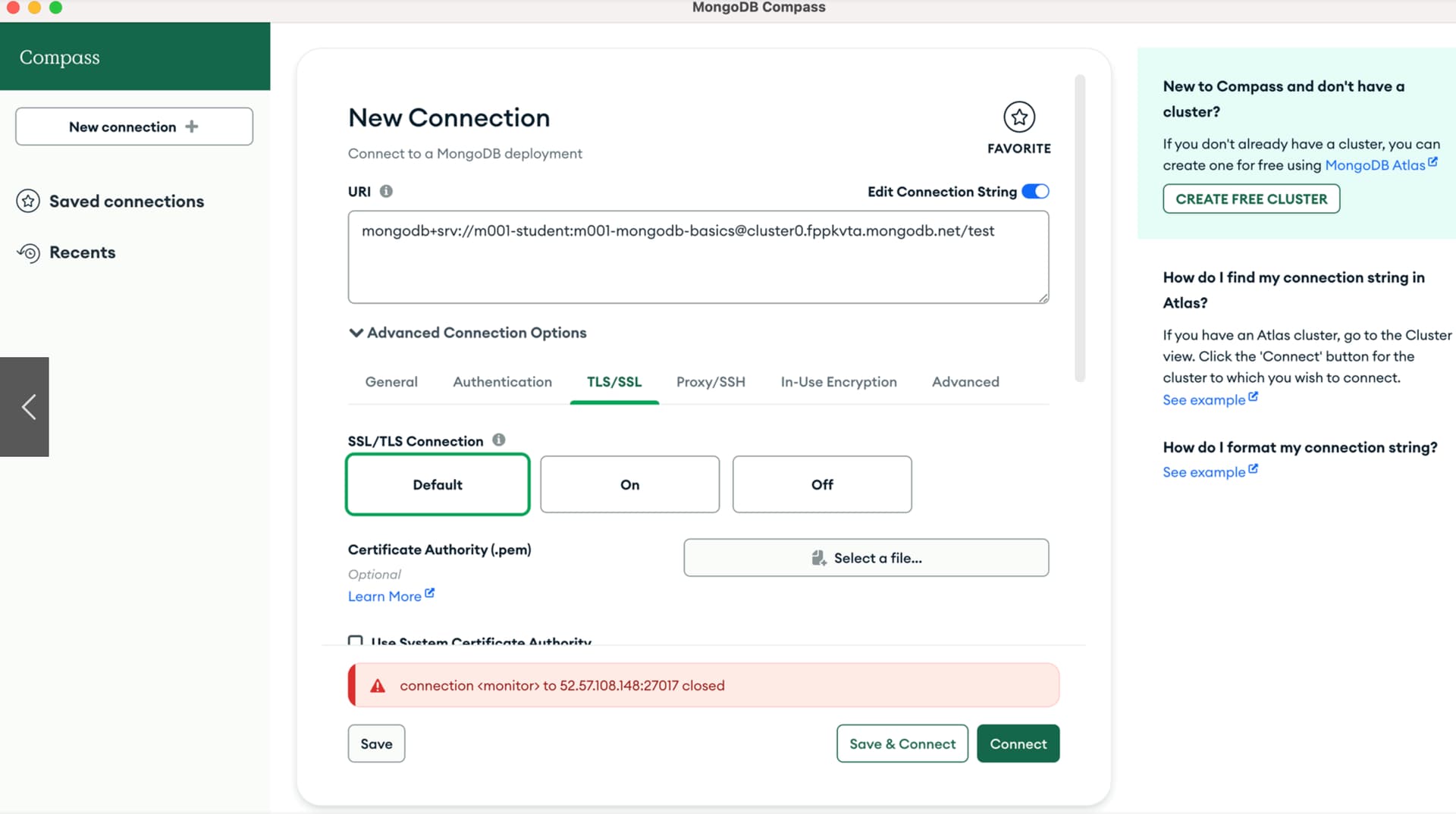 *MongoDB Compass connection monitoring interface
*MongoDB Compass connection monitoring interface