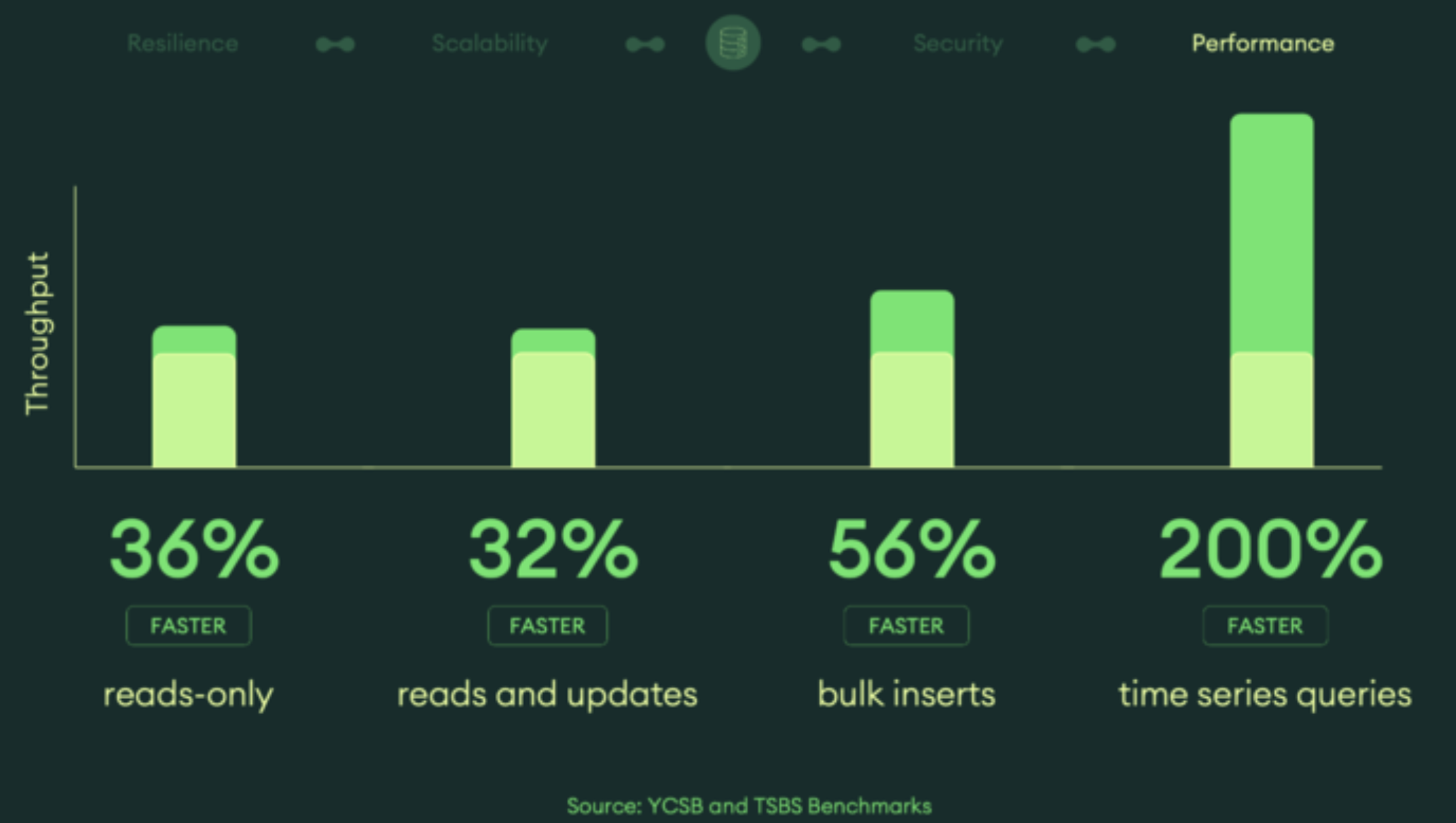
MongoDB stores data as JSON documents instead of SQL tables, which sounds great until the flexible schema bites you in the ass. Here's what you actually need to know.

Document Storage Reality
MongoDB organizes data like this:
- Documents: JSON objects that can have completely different fields
- Collections: Groups of documents (think "tables" but messier)
- Databases: Containers for collections
MongoDB lets you throw user profiles, preferences, and whatever else in one document without JOINs. This works great when you're prototyping, but production apps need some discipline or your data structure becomes a nightmare.
The Schema Flexibility Problem
MongoDB's "no schema" approach means you can add fields whenever you want without ALTER TABLE bullshit. Sounds amazing until you have documents in the same collection with completely different structures and your queries start breaking.
Try mixing different product types and watch your queries break. I learned this the hard way when half our products had ISBN fields and the other half had technical_specs arrays. Writing consistent queries becomes impossible when your data structure looks like it was designed by committee.
Sharding: Automatic Until It Isn't
When you outgrow a single server, MongoDB can shard your data across multiple machines. The "automatic" part is marketing bullshit - you'll spend weekends figuring out shard keys and wondering why some shards are hot while others sit empty.
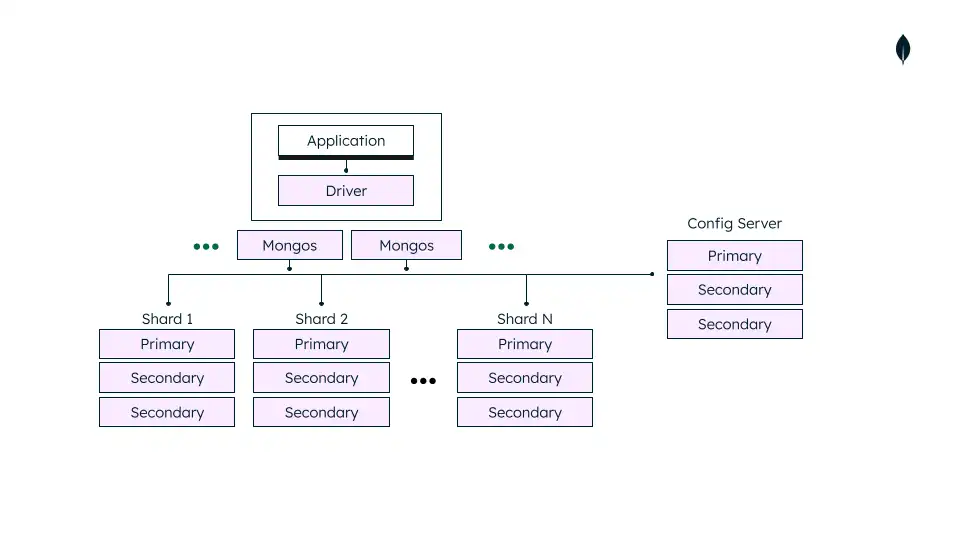
Choose your shard key wrong and you're fucked. MongoDB can't easily change shard keys once you've committed - I wasted a weekend debugging sharding because our product IDs made terrible shard keys. Unlike PostgreSQL where you just add more RAM, MongoDB forces you to think about data distribution from day one.
Replica Sets: Works Until It Doesn't
MongoDB's replica sets keep copies of your data on multiple servers. When the primary goes down (not if, when), a secondary takes over. Usually works great, except when network partitions happen and you get split-brain scenarios.

The primary handles writes while secondaries can serve reads, which seems smart until you realize read-after-write consistency isn't guaranteed. Your user updates their profile, immediately refreshes the page, and sees old data because they hit a lagging secondary. Spent 3 hours figuring out why reads were slow before realizing we were hitting a lagging secondary. Welcome to eventual consistency hell.
What They Don't Tell You
MongoDB works best when you design around its strengths instead of fighting them. Embed data you always access together, reference data that changes independently. Don't try to normalize everything like SQL - embrace some denormalization and duplicate data strategically.

For complex queries, learn to use aggregation pipelines effectively - they're MongoDB's answer to SQL JOINs and GROUP BY operations. I wasted a day figuring out why queries were slow before realizing I needed a compound index.
Watch out for version gotchas: MongoDB 5.0 changed how indexes work with arrays - update your query patterns if you're upgrading from older versions. MongoDB 6.0 will throw "MongoServerError: PlanExecutor error during aggregation" if you try using old aggregation syntax with the new optimizer.