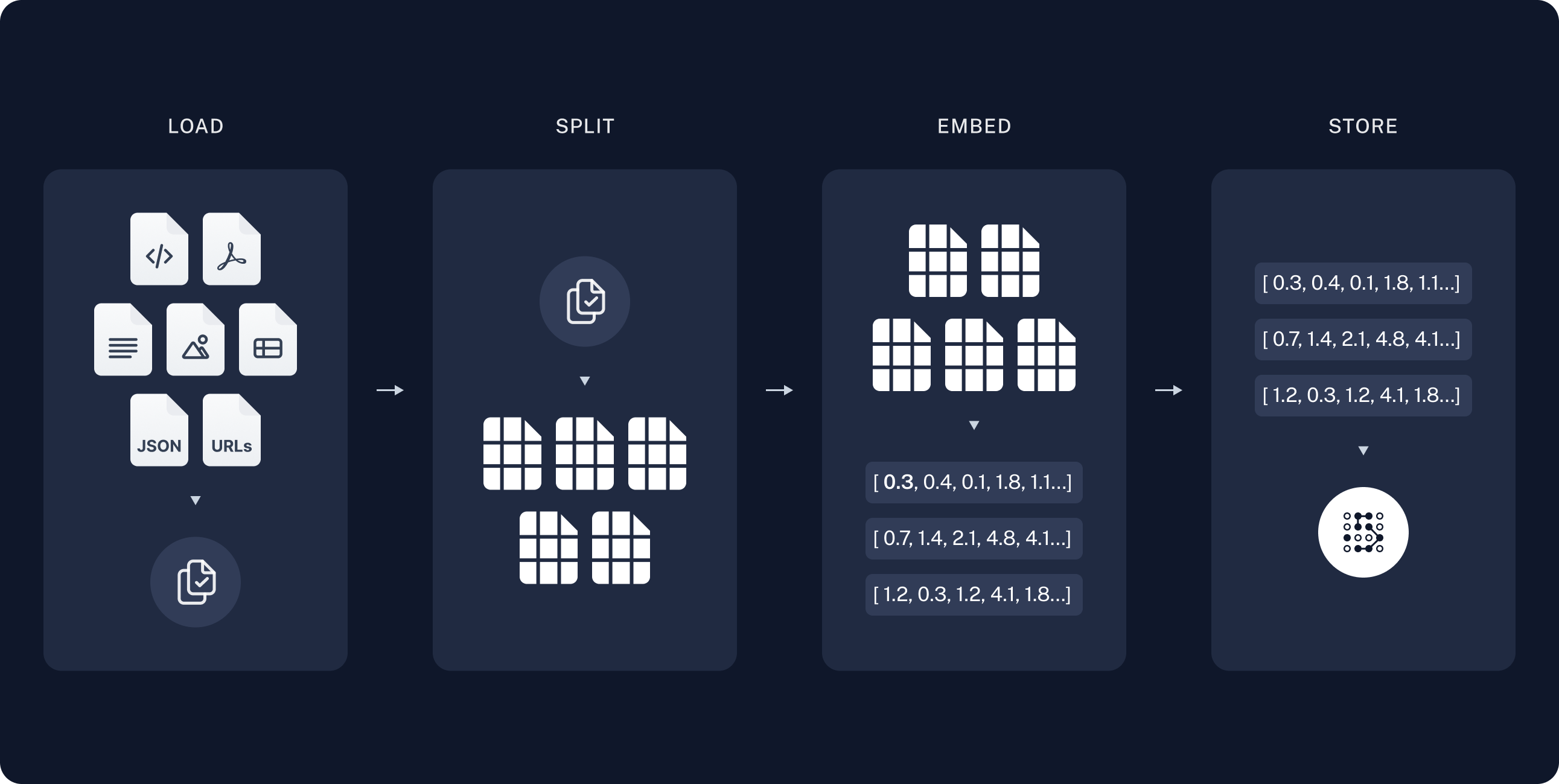
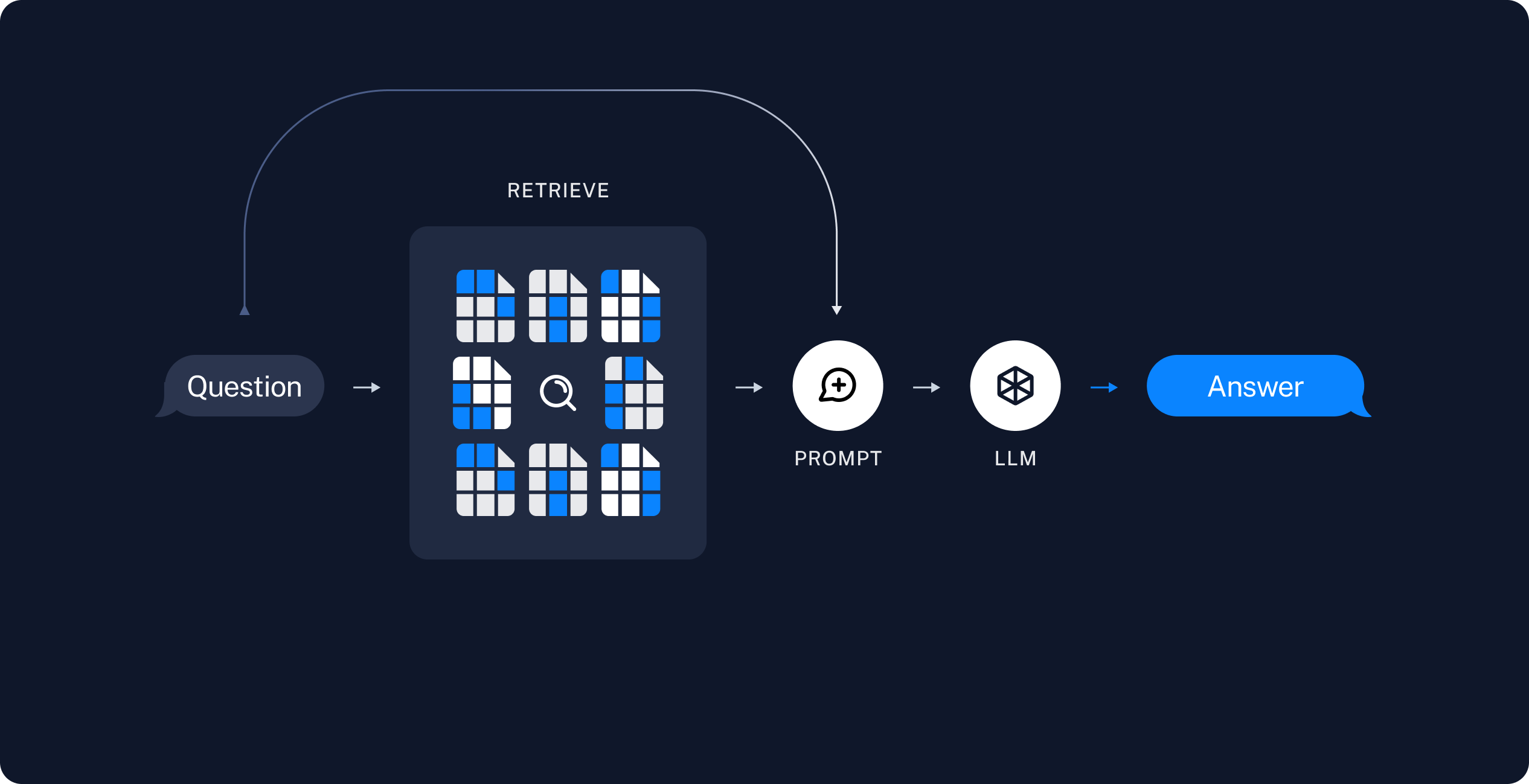
I've been running ChromaDB in production for 8 months. Version 1.0.21 dropped in late 2024, and it finally fixed the memory leak that was eating my containers alive. Before this version, I had a fucking cronjob restarting ChromaDB every Tuesday and Friday at 3 AM. Worked great until I forgot to update it after daylight saving time.
Local Development That Actually Works
ChromaDB doesn't make me choose between "works on my laptop" and "works in production." Weaviate's GraphQL mutations make me want to switch careers. Qdrant's documentation assumes I have a PhD in distributed systems. Pinecone works perfectly until you realize you're burning $400/month on their "starter" plan.
ChromaDB has 23.3k GitHub stars because you can literally pip install chromadb, import it, and have vector search working in under a minute. Same exact API from your Jupyter notebook to production. No YAML configuration nightmare, no Kubernetes operators, no vendor lock-in APIs. The documentation doesn't suck, and their getting started guide assumes you're a normal human being.
The API Doesn't Hate You
Four functions. That's it. Create a collection, add documents, query them, filter results. I explained it to our intern in 3 minutes - she had it running before lunch. Compare that to Weaviate where I wasted a full week trying to understand their Byzantine schema system before giving up.
## This is all you need. Seriously.
import chromadb
client = chromadb.Client()
collection = client.create_collection("docs")
collection.add(documents=["some text"], ids=["doc1"])
results = collection.query(query_texts=["search text"])
Built in Rust (61.8%) with Python (18.4%) using HNSW indexing and SQLite for metadata, so it's fast enough and doesn't eat all my RAM like the Java-based solutions. Check out their architecture overview and performance benchmarks to understand why it performs better than pure Python implementations. The project roadmap shows where they're heading with scalability improvements and cloud offerings.
Production War Stories
Version 1.0.21 added sparse vector support and AVX512 optimization. The AVX512 stuff gave me a 15% speed bump on my Intel machines, but broke spectacularly on older hardware. Spent 3 hours debugging why ChromaDB wouldn't start on our staging servers - turns out they didn't support AVX512.
The garbage collection improvements actually matter. Before this version, ChromaDB would slowly eat memory until the Linux OOM killer nuked the process. Now it's stable enough that I don't need those restart cronjobs anymore.
Integration Reality Check
LangChain integration works great with detailed examples. LlamaIndex integration exists but their examples are outdated. Spent an afternoon making LlamaIndex work with ChromaDB 1.0.x - their docs still reference 0.4.x APIs. The community Discord was actually helpful for debugging integration issues.
But here's the thing: once you get it working, it stays working. Unlike some other solutions where every minor update breaks your imports.
Why Not The Alternatives?
Pinecone: Expensive as hell but rarely breaks. Great if you have VC money.
Weaviate: Powerful but their learning curve is vertical. Good luck with their GraphQL mutations.
Qdrant: Fast but the Python client is a mess. Rust client is solid though.
MongoDB Atlas Search: Don't. Just don't. Trust me on this one. If you want document search, use Elasticsearch instead. For deeper comparisons, check out this vector database comparison and benchmarking results. The vector database landscape guide provides good context on different approaches.