NiFi is basically visual programming for data flows. Instead of writing code to move data from your database to your data lake, you drag boxes around a web interface and connect them with arrows. It's surprisingly powerful once you get past the initial "wait, where's the code?" confusion.

![]()
The main thing NiFi solves is that eternal problem: "We need to get data from System A to System B, transform it a bit, and make sure it doesn't die halfway through." You know, the stuff that sounds simple until you actually try to do it.
The Real Problems NiFi Actually Solves
The "It Just Stopped Working" Problem: Your ETL script worked fine for 3 months, then mysteriously died at 2am. NiFi has built-in retry logic and visual monitoring, so you can see exactly where things broke and it keeps trying until it works.
The "Source System is Faster Than Our Database" Problem: Your API pulls data faster than your database can handle it. NiFi automatically handles backpressure - it'll slow down the input when downstream systems can't keep up.
The "This Data Format Changed Again" Problem: Someone upstream decided to change the JSON structure without telling anyone. Typical. They probably called it a 'minor enhancement' while breaking every downstream consumer. With NiFi, you can modify your transformation logic through the web UI without restarting anything or deploying new code.
The "Where Did This Data Come From?" Problem: Six months later, someone asks why certain records are missing. NiFi tracks every piece of data - where it came from, what happened to it, and where it went. This is called data lineage and it's a lifesaver during investigations.
How This Thing Actually Works
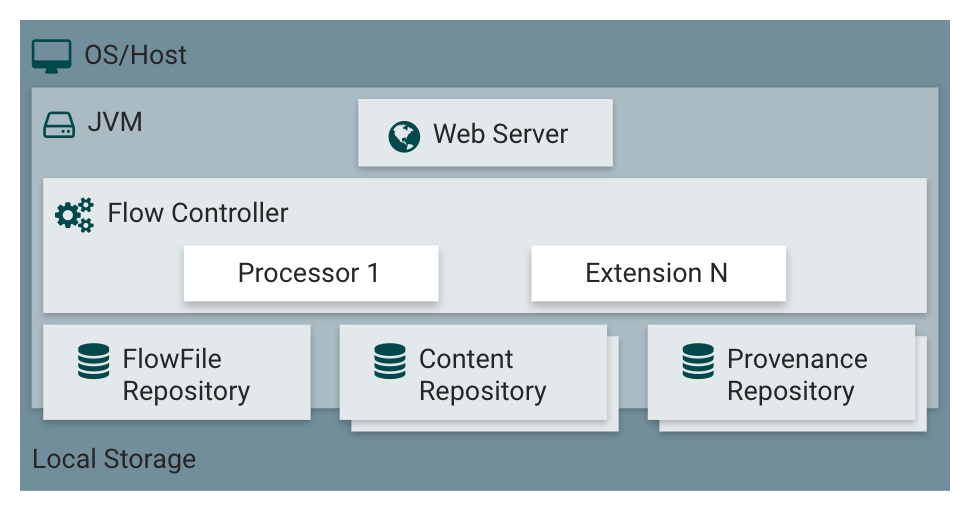
Think of NiFi as a factory assembly line for data. Data comes in (called FlowFiles), gets passed through various machines (Processors) that do stuff to it, and flows out through conveyor belts (Connections).
FlowFiles are packets of data that move through your flow - they have attributes (metadata) and content (the actual data). Think of them as envelopes carrying your data with labels describing what's inside.
The web interface shows you this visually - you can watch data flowing through your system in real-time, see where bottlenecks are happening, and catch problems before they become disasters. The monitoring lets you track queue depths, processing rates, and system health.
The built-in monitoring shows you real-time stats: how many records are flowing, where queues are backing up, which processors are throwing errors. It's like having a traffic control center for your data.
Unlike traditional batch ETL that runs once a day and either works or doesn't, NiFi processes data continuously. It's like the difference between a scheduled bus route and Uber - data gets processed as it arrives.
A lot of companies use this - financial firms for fraud detection, manufacturers for IoT data, government agencies for... whatever government agencies do with data. The current version is 2.5.0 from July 2025, and it runs on any machine with Java.
But how does NiFi stack up against the other tools you're probably evaluating? Let's get real about the competition...