Debezium captures database changes by reading transaction logs, which sounds simple until you actually try to set it up. I've been running this shit for 2 years now, and here's what you need to know before you dive in.
The Setup Reality Check
Debezium runs on Kafka Connect, which means you need Kafka first. If you don't already have a Kafka cluster, plan for 3 weeks of setup, not 3 hours. The documentation makes it look easy - it's not.
Kafka Connect Mode: This is what everyone uses in production. Your connector runs in a distributed cluster, survives single node failures, and scales horizontally. Setting it up properly took me 5 days because the memory settings are garbage by default.
Debezium Server: Standalone mode that doesn't require Kafka. Sounds great, right? Wrong. You lose fault tolerance and horizontal scaling. I tried this first - lasted exactly 2 weeks before I gave up and went back to Kafka Connect.
Embedded Engine: Java library you embed in your app. Don't do this unless you enjoy debugging memory leaks at 3am. The embedded engine will eat your heap and you'll have no idea why.
Database Support (The Real Story)
Version 3.2.2.Final (September 2025) supports these databases, but "supports" is doing some heavy lifting:
PostgreSQL: Works great once you enable logical replication. Just make sure your wal_level is set to logical or you'll waste 4 hours debugging why nothing works.

MySQL: The binlog setup is straightforward, but row-based replication is required. Mixed or statement-based replication will silently fuck you over.
Oracle: Prepare for pain. LogMiner works but requires supplemental logging enabled. XStream is faster but costs extra licensing. Either way, you'll need a DBA who doesn't hate you.
MongoDB: Uses replica set oplog, which means you need a replica set. Single node MongoDB won't work, learned that the hard way.
SQL Server: Transaction log capture works, but the CDC feature must be enabled at both database and table level. Miss one table and you'll be wondering why data isn't flowing.
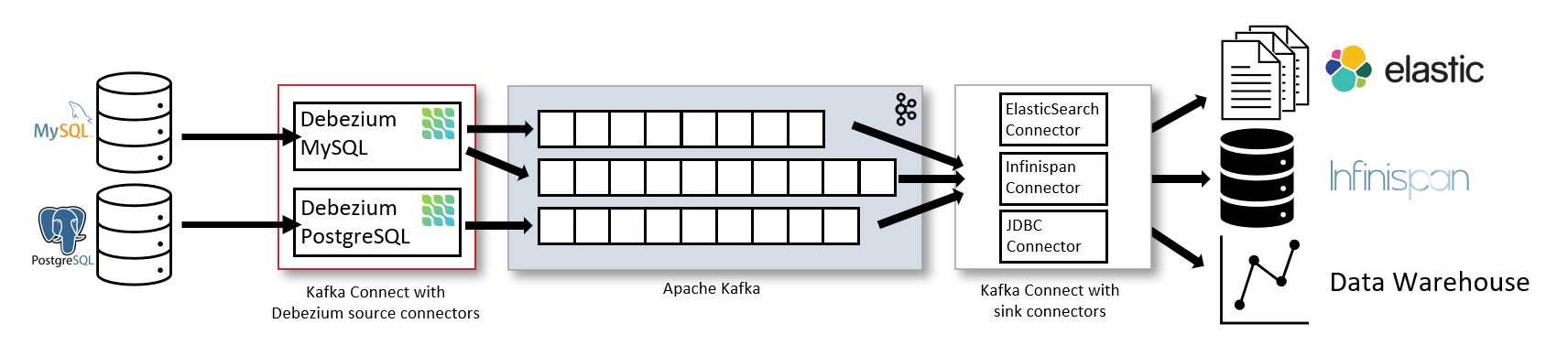
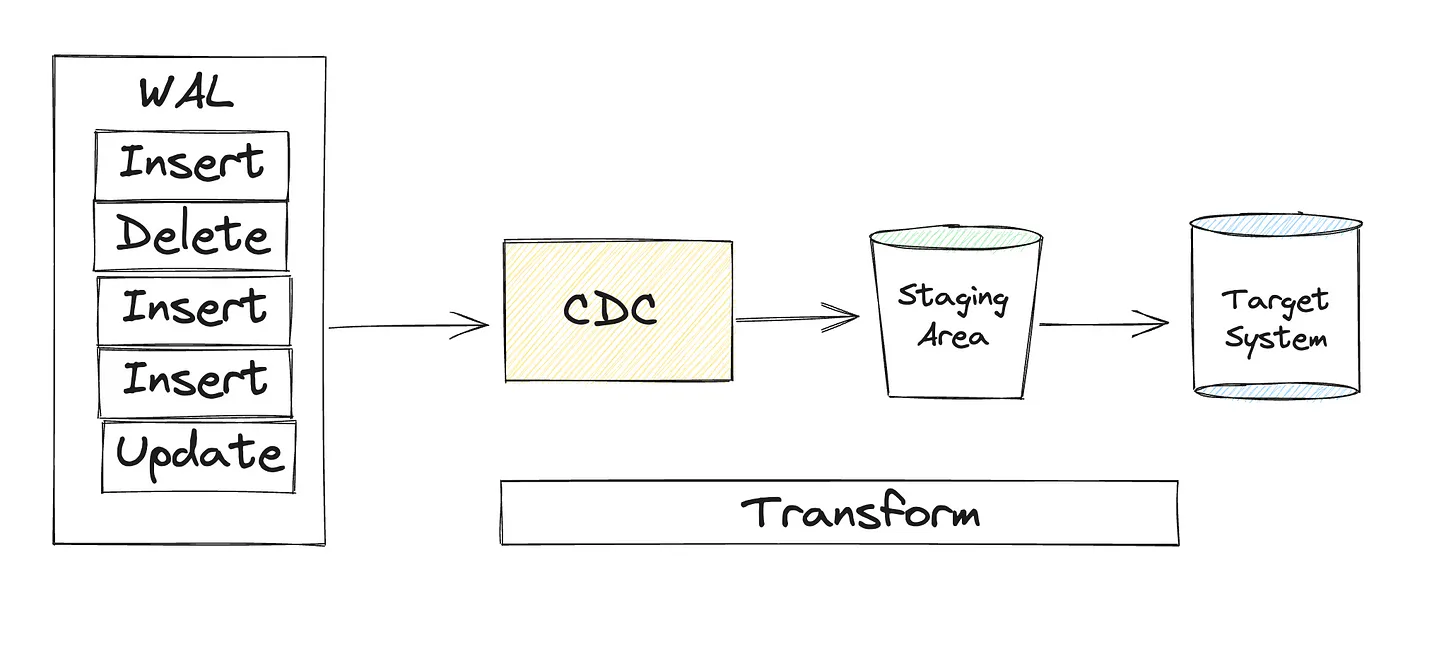
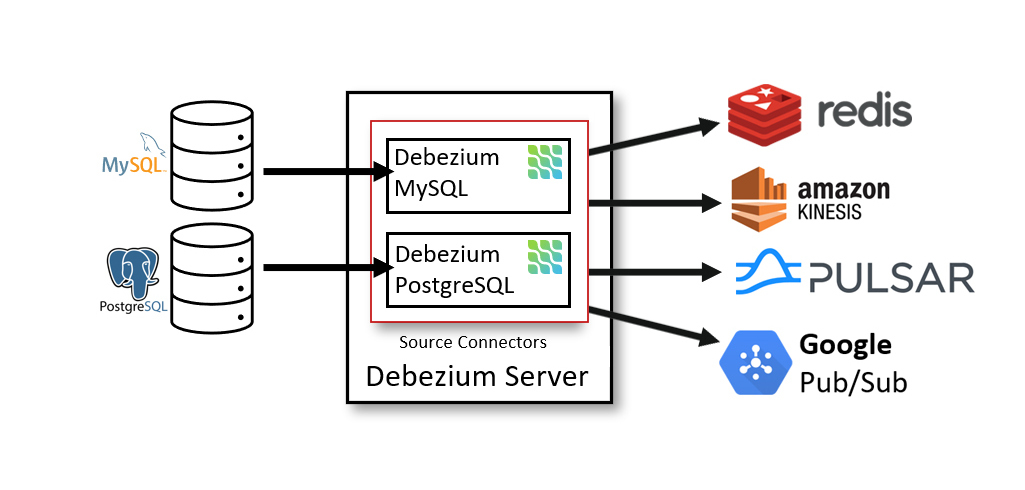
What Actually Works in Production
Latency: Usually sub-second, but can spike to minutes when your connector decides to shit the bed. Monitor your lag metrics or you'll be blind.
Database Impact: Minimal until it's not. Oracle LogMiner can peg a CPU core, and PostgreSQL replication slots will fill your disk if the connector stops consuming. I learned this during a 6-hour outage.
Ordering: Per-partition ordering works, but if you're sharding data across multiple partitions, global ordering goes out the window. Design your partition keys carefully or accept eventual consistency.
Failure Recovery: Debezium stores offsets in Kafka, so recovery works well. But if you lose your offset data, you're starting over with a full snapshot. We've been there - 48 hours to catch up on a 500GB table.
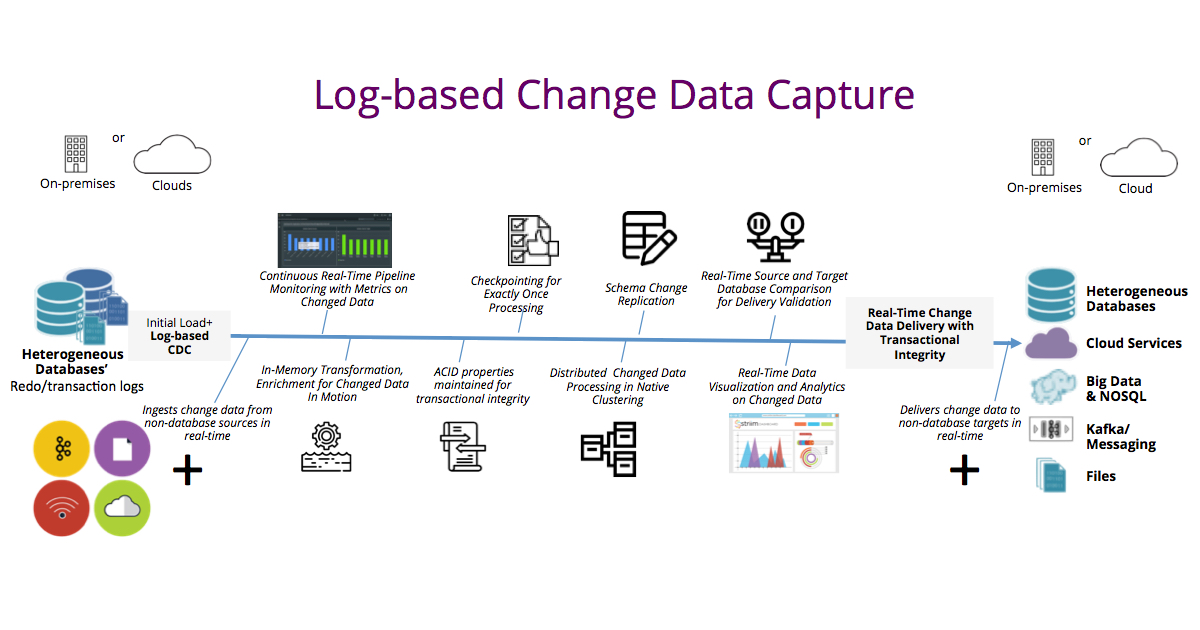
This whole setup lets you stop polling databases and writing triggers, which is worth the complexity. Just don't expect it to work perfectly on day one.