I've spent the last couple years migrating everything from 50GB MySQL shitshows to 2TB PostgreSQL clusters that developers swore would "never get that big." Most tools are designed by people who think production environments are just staging with more RAM. But I found a few that won't make you hate your career choices.
![]()
pgroll - Finally, PostgreSQL Migrations That Don't Lock Everything
pgroll is the first PostgreSQL migration tool that doesn't make me want to throw my laptop out the window. Released by Xata in 2024, it uses shadow columns to avoid table locks completely.
Here's the difference:
-- Old way (pray your app can handle downtime)
ALTER TABLE users ADD COLUMN email VARCHAR(255);
-- Table locked, users can't login, phone starts ringing
-- pgroll way
pgroll start add_email_column.json
-- Table never locked, old and new schema work simultaneously
I migrated a 40GB users table during peak traffic and nobody noticed. The GitHub repo has decent documentation and actual working examples, which is rare.
Real gotchas I found:
- Shadow columns eat extra disk space - maybe 20% more during migration
- Connection pool exhaustion will kill you if
max_connectionsis too low - Version 0.6.1 had a memory leak, stick with 0.6.0 or 0.7.0+
- Foreign key constraints get messy - test thoroughly first
AWS DMS Still Exists (And Still Sucks for CDC)

AWS Database Migration Service works for simple one-shot migrations, but using it for ongoing replication is like using a chainsaw for brain surgery. I've burned three weekends straight debugging why DMS randomly decided to lag 4 hours behind during Black Friday traffic.
The r/aws community agrees - DMS is fine for "lift and shift" but terrible for Change Data Capture. Connection timeouts randomly kill long-running replications, and the error messages are useless.
When DMS doesn't suck:
- Simple MySQL → PostgreSQL one-time migrations
- Small datasets (under 100GB)
- You have enterprise support for when shit breaks at 3am
- Non-critical data where some lag is acceptable
When DMS will ruin your weekend:
- Real-time CDC requirements
- Complex schema transformations
- Mixed workload patterns (heavy writes + reads)
- Any mission-critical data pipeline
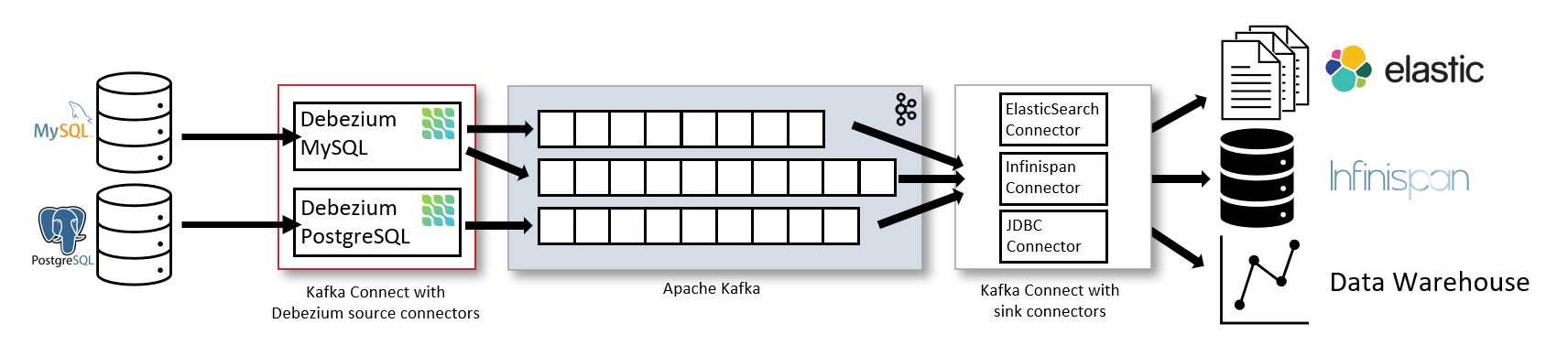
Debezium 3.0 - CDC That Actually Works

Debezium 3.0 released in October 2024 and fixed most of the stuff that made me hate CDC. The autonomous error recovery alone saved my ass multiple times during Black Friday traffic.
Key improvements from someone who's used it in production:
- Smart batching reduced our replication lag from ~30 seconds to under 5 seconds
- Auto-recovery handles about 80% of the stupid connection errors that used to wake me up
- Schema evolution doesn't break when someone adds a column anymore
- Cross-cloud sync between AWS RDS and GCP CloudSQL actually works now
Production reality check: CDC lag turns into complete shit during peak traffic. During our Black Friday sale, lag jumped from 200ms to 3+ minutes and stayed there until I figured out the batch sizes were configured by someone who'd never seen real traffic. The Confluent CDC guide has the settings that actually work - not the defaults that look good in demos.
Container-Native Migrations (Finally Useful)
Liquibase in Kubernetes and Atlas Kubernetes Operator graduated from "toy demo" to "actually useful in production" status.
The big win: database schema changes get versioned with application code. No more "did someone run the migration?" confusion during deployments.
## This actually works in production now
apiVersion: liquibase.io/v1beta1
kind: LiquibaseOperator
metadata:
name: user-schema-migration
spec:
changeLog: migrations/add-email-column.xml
database:
url: postgresql://prod-db:5432/myapp
Kubernetes migration reality check:
- Works great in staging until you discover your production DB has 47 tables that staging doesn't
- RBAC permissions will eat your entire weekend - whoever designed Kubernetes security hates humanity
- Failed migrations leave your cluster in this zombie state where half your pods think they're migrated
- Rollbacks technically work, but you'll be faster just fixing the shit manually at 2am
The Atlas Kubernetes docs are actually readable, which puts them ahead of most database tools.
Links that don't suck:
- pgroll GitHub repo - working examples
- Debezium 3.0 release notes - what actually changed
- AWS DMS best practices - how to not hate it
- AWS DMS migration challenges and solutions - comprehensive problem analysis
- Zero downtime database migration strategies - production best practices
- Netflix production data migrations case study - actual production story
- Liquibase Kubernetes setup guide - setup guide
- Atlas Kubernetes integration guide - real YAML configs
- PostgreSQL logical replication guide - the foundation
- Database migration checklist - from GitHub's tool
- CDC monitoring and alerting - what to watch