Analytical queries on regular databases are slow as shit. Last Tuesday I watched PostgreSQL churn through some 50-million-row aggregation for like 10 minutes while ClickHouse did the same thing in 3 seconds. This happens constantly.
Column Storage Finally Makes Sense
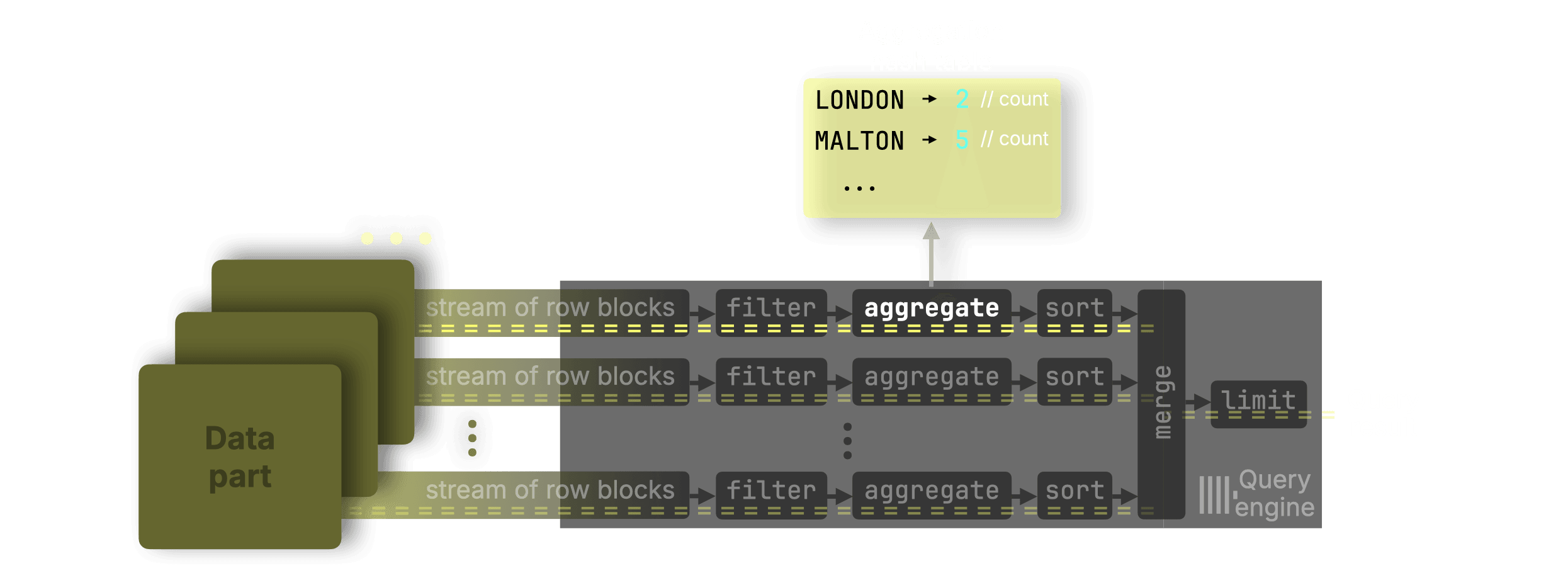
Here's why columnar storage matters: when you're summing revenue by month, you don't give a fuck about customer names or addresses. ClickHouse only reads the columns you need. PostgreSQL reads entire rows even when you only want one column, which is why your analytics queries time out and analysts complain all day. This architectural difference is what makes ClickHouse significantly faster for analytical workloads.
I learned this debugging a production dashboard that kept dying every morning. Simple query - just summing orders by date - but PostgreSQL was reading all 47 columns for 100 million rows. Took forever. Moved it to ClickHouse and that 5-minute query became a 2-second query. Analysts finally shut up about slow dashboards.
Performance Numbers That Matter
Yeah, ClickHouse is faster. How much depends on your specific clusterfuck of data:
- Simple aggregations: Usually 10-50x faster
- Complex analytics: 100x+ speedups happen a lot
- Single-row lookups: PostgreSQL might actually win here
That "4,000x faster" marketing bullshit comes from very specific benchmark conditions with 600 million rows and perfect conditions. Real world is messier, but even 10x faster matters when your current queries take 30 minutes.
Stuff I've actually measured in production:
- COUNT(*) with GROUP BY on maybe 100M rows: PostgreSQL took like 8 or 9 minutes, ClickHouse did it in 12 seconds
- Some complex JOIN aggregation: PostgreSQL timed out after 30+ minutes, ClickHouse finished in 45 seconds
- Time-series analytics on around 1 billion events: PostgreSQL just gave up, ClickHouse took 3 minutes
When ClickHouse Will Fuck You Over
Don't use ClickHouse for:
- User auth systems - UPDATE/DELETE operations were garbage until version 25.7
- Shopping carts - No real transactions means you'll corrupt data eventually
- Comment systems - Small frequent writes will kill performance due to part optimization overhead
- Any normal CRUD app - Just use PostgreSQL, don't be clever
ClickHouse is for analytics, not applications. I've watched teams try to use it as a regular database. It's always a disaster. The use cases documentation makes this clear but nobody reads it.
Memory Usage Will Kill Your Budget
ClickHouse eats RAM like crazy. A query processing 1GB of data might use 4GB of RAM during execution. Size your servers with way more RAM than you think you need or get ready for OOM kills at 3am when the overnight jobs run. The memory settings documentation is essential reading, and you'll want to monitor system.query_log for memory-hungry queries.

Row vs Column storage: Why ClickHouse reads only the columns you need instead of entire rows