![]()
Database replication copies your data to multiple servers. That's literally it. When your primary database shits itself at 3am on a Saturday (and it will), your app keeps running because it switches to a replica.
![]()
Why Your Database Will Fail
Your database will fail. Not might fail - will fail. Hard drives die. Servers catch fire. Network cables get unplugged by janitors. AWS has outages. Your database is a single point of failure until you replicate it.
I learned this the hard way when our MySQL master took a shit during Black Friday. Entire e-commerce site down for 2 hours while we scrambled to restore from backups. Cost the company around $50k in lost sales - we stopped counting when the CEO started stress-eating donuts and muttering about our "fucking incompetence." Never. Fucking. Again.
Master-Slave: The Basic Setup
Most replication starts with master-slave (or primary-replica if you're politically correct). One server handles all writes, copies changes to read-only replicas. Simple, reliable, and works for most applications.
The master writes every change to a binary log. Replicas read this log and apply the changes. Sounds fucking simple until MySQL replication randomly stops working, and the error logs just say "Error reading packet from server: Connection reset by peer (2013)" - which is about as helpful as a chocolate teapot. Half the time it's because the replica ran out of disk space, the other half it's MySQL 8.0.28 having another networking tantrum.
Multi-Master: When You Hate Yourself
Multi-master lets you write to multiple databases simultaneously. Sounds great until you hit write conflicts and your data becomes inconsistent. Spent 3 days debugging why user accounts were randomly disappearing - turns out two masters were deleting the same record at slightly different times. The error logs just said "duplicate key" which meant nothing.
Don't do multi-master unless someone's holding a gun to your head. The complexity isn't worth it, and you'll spend more time hunting phantom data corruption than actually building features users give a shit about.
Synchronous vs Asynchronous: Performance vs Paranoia
Synchronous replication waits for replica confirmation before committing. Zero data loss, but your database becomes slow as hell. Every write now depends on network latency to your replicas. We tried this once and response times went from 50ms to 300ms.
Asynchronous replication commits immediately, replicates later. Fast, but you'll lose data if the master dies before replicating. Most production systems use async because users bitch more about slow sites than losing their last comment - harsh but reality.
Network Latency Will Kill You
Synchronous replication across regions is suicide. The speed of light limits you to about 1ms per 100 miles. Try syncing from New York to London (3,500 miles) and watch your database crawl to 35ms per transaction minimum.
Keep replicas close or use async. Physics beats your wishful thinking every fucking time, and no amount of "optimization" will make light travel faster than the universe allows.
CDC: The Smart Way
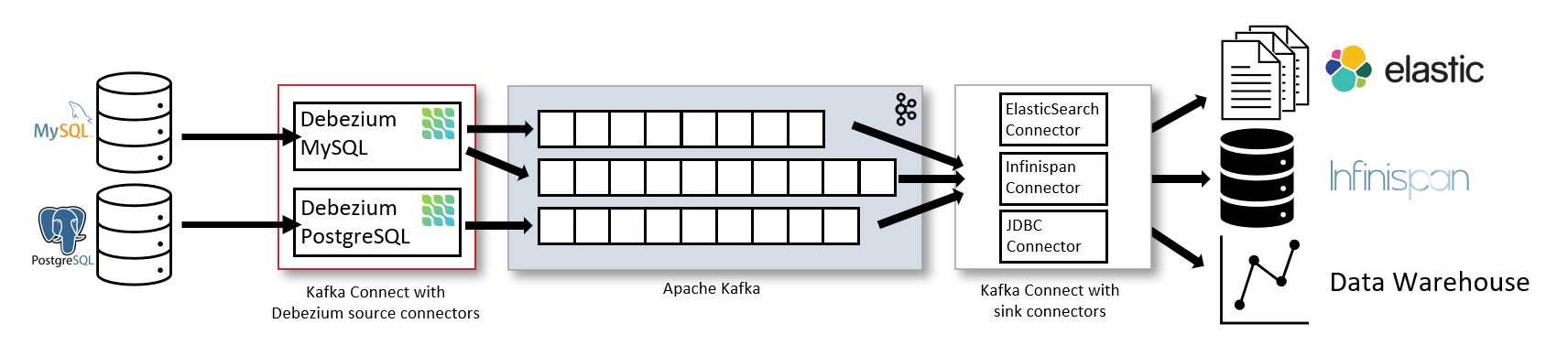
Change Data Capture reads transaction logs instead of polling for changes. More efficient, catches everything including schema changes. Tools like Debezium make CDC "easier," but you'll still spend weeks tuning 50 different parameters.
CDC has better performance than traditional replication, but the operational complexity will make you want to throw your laptop out the window. You'll be debugging Kafka Connect errors at 3am wondering why messages stopped flowing hours ago with zero useful error messages.
Cloud Provider Magic
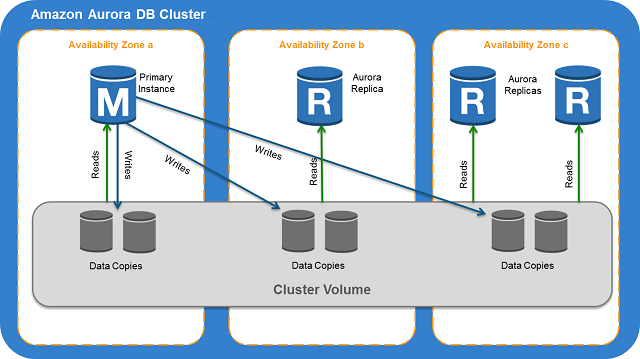
AWS Aurora, Azure Cosmos DB, and Google Spanner hide replication complexity behind managed services. They work great until they shit the bed, then you're stuck waiting for support to fix problems you can't even see.
Aurora's "sub-second failover" is marketing bullshit - it actually takes 30-60 seconds on a good day. I've watched Aurora failovers take 90 seconds during peak traffic while customers screamed at us on Twitter. Not exactly sub-second.
![]()
You've got the basics down - now let's look at how these different replication approaches actually perform in the real world, with numbers that matter.




