Here's what nobody tells you about Airflow's scheduler in production: the scheduler is a piece of shit that will break in creative ways you never imagined.
My First Production Disaster: The DAG File Parsing Nightmare
We hit our first wall around 180 DAGs. Not 300 like the documentation suggests - 180. The scheduler would choke, CPU would spike to 100%, and tasks would just sit there doing nothing. The web UI would show everything as "queued" while our ETL jobs missed their SLA windows.
The error? Nothing. No fucking error. Just this in the logs:
INFO - Loaded 180 DAGs
INFO - Loaded 180 DAGs
INFO - Loaded 180 DAGs
Over and over, every 30 seconds. The scheduler was parsing every single DAG file like a brain-damaged robot, taking longer each time until it got stuck in an infinite parsing loop.
The fix that actually worked: Cranked `dag_dir_list_interval` up to 300 seconds and threw 8GB of RAM at the scheduler. Did it solve the problem? Kind of. Did it feel like applying duct tape to a structural problem? Absolutely. The official troubleshooting guide mentions this exact issue but buries it in paragraph 47.
Silent Failures Are Airflow's Specialty
You know what's fun? When your scheduler process shows as "running" in htop but hasn't actually scheduled anything in 3 hours. This happened to us on a Tuesday morning when our overnight ETL jobs just... didn't run.
The actual error message (buried in logs you have to dig for):
sqlalchemy.exc.OperationalError: (psycopg2.OperationalError) connection to server on socket \"/var/run/postgresql/.s.PGSQL.5432\" failed: No such file or directory
Translation: PostgreSQL connection died, but Airflow didn't bother to retry or alert anyone. It just kept pretending everything was fine while our data pipelines turned into expensive paperweights. The connection pooling documentation exists but good luck finding the actual settings that prevent this.
The Database Becomes Your Enemy
Here's something I learned the hard way: Airflow treats your metadata database like a punching bag. Every task state change hammers the DB with writes. We started with MySQL because that's what the tutorial used. Big mistake.
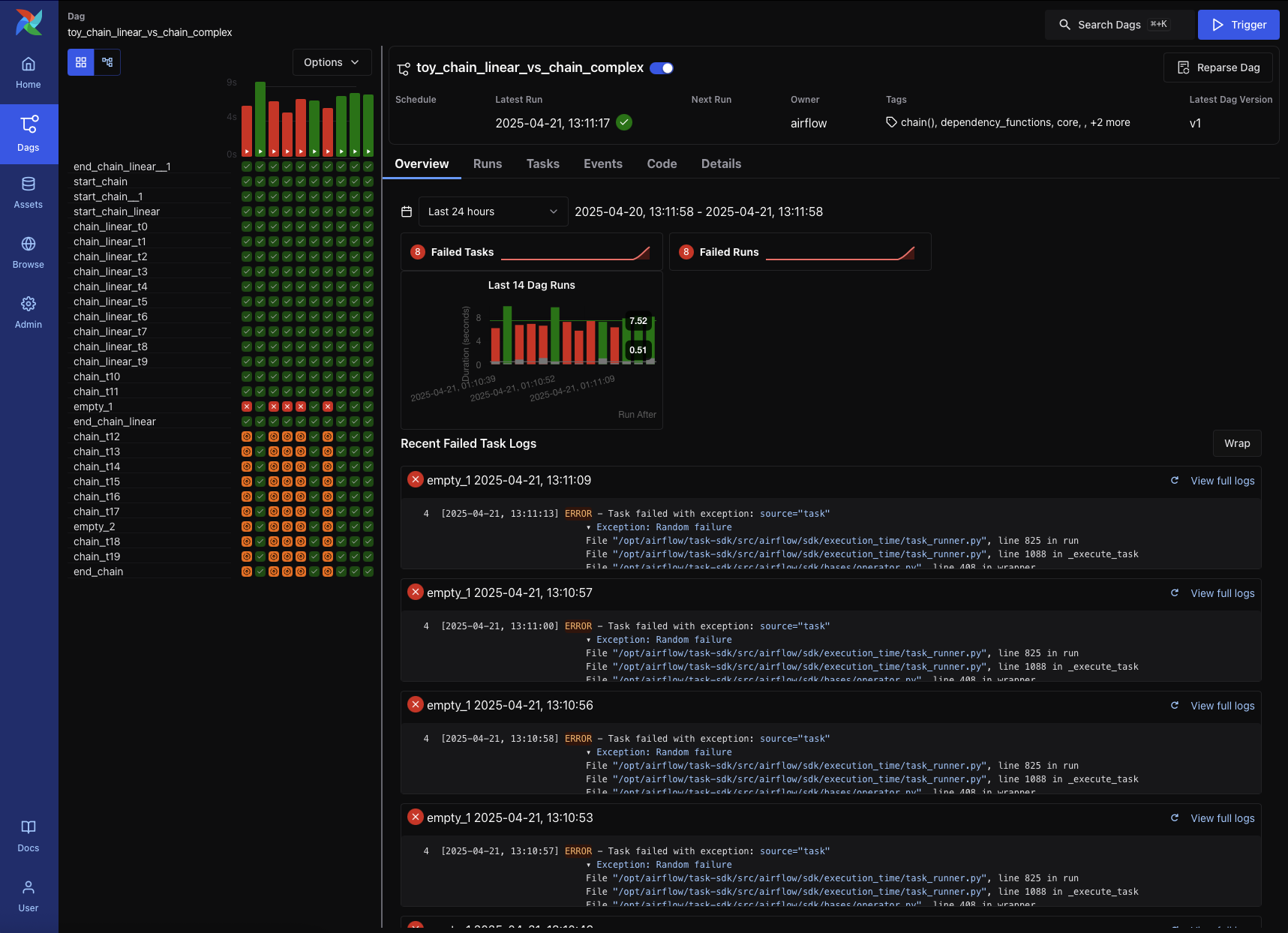
At around 500 concurrent tasks, MySQL would shit itself. Connection pool exhaustion, deadlocks, and my personal favorite error:
ERROR - Task unable to sync to database: too many connections
Switching to PostgreSQL helped, but even Postgres starts crying when you hit 1000+ concurrent executions. And good luck figuring out the optimal connection pool settings - the documentation is about as helpful as a chocolate teapot. This GitHub issue has 200+ comments of people trying to figure out the same damn thing.
Memory Leaks: The Weekly Restart Ritual
Every Friday at 2 PM, we restart all Airflow services. Why? Because the scheduler has a memory leak that would make Internet Explorer 6 proud.
It starts at 2GB RAM usage. By day 5, it's consuming 12GB and the server is swapping like crazy. The OOM killer eventually puts it out of its misery, but by then your pipelines have been dead for hours.
The "solution": Cron job to restart the scheduler every 3 days. Professional? No. Does it work? Unfortunately, yes. Half the internet does this exact same hack.
Airflow 3.0 Won't Save You
Everyone's excited about Airflow 3.0 because it promises to fix the scheduler. I've tested it. Here's the truth: it's faster at being broken.
The new Task SDK is nice in theory, but now you have MORE components to babysit. The web UI is prettier, but still times out when you have actual data volumes. And the breaking changes mean you get to rewrite half your DAGs for the privilege of slightly better performance.
Bottom line: If you're hoping 3.0 will magically solve your production nightmares, prepare for disappointment.
The Real Cost: Your Sanity
Want to know the true cost of running Airflow? It's not the server resources or the database licenses. It's the 2 AM Slack messages, the weekend debugging sessions, and the constant fear that your data platform is held together with prayer and automated restarts.
You need someone who understands both Airflow's quirks AND database tuning AND Kubernetes AND monitoring. Good luck finding that unicorn. Most teams end up with someone (usually me) who becomes the designated Airflow whisperer through sheer necessity.
I've seen grown engineers quit over Airflow. I've seen teams scrap months of work to switch to something simpler. And I've personally lost more sleep to Airflow scheduler crashes than I care to admit. Check out this Reddit thread if you want to see 300+ comments of engineers sharing similar pain.
Look, maybe you think I'm being dramatic. "It can't be that bad," you're probably thinking. Let me share the harsh reality of what actually happens when you try to scale this thing.