Cluster disasters suck. I've been through a few of them now. Middle of the night, everything was fucked. Not just some pods - the entire cluster was dead. kubectl was hanging, monitoring was dark, couldn't even SSH anywhere. Management was freaking out because we were bleeding money.
That was my introduction to cascade failures - when Kubernetes doesn't just have a problem, it has ALL the problems simultaneously. I've survived three of these disasters now, and they're uniquely horrible because all your debugging tools stop working exactly when you need them most. Oh, and 67% of organizations deal with cluster-wide outages annually - so you're not alone in this hell.
Kubernetes troubleshooting documentation covers the basics, but real cascade failures require understanding the architecture and failure modes. The SIG-Scalability group documents common failure patterns and performance limits. The disaster recovery guide explains backup strategies, while monitoring best practices help detect issues early.
The Control Plane Death Spiral (When kubectl Becomes Useless)

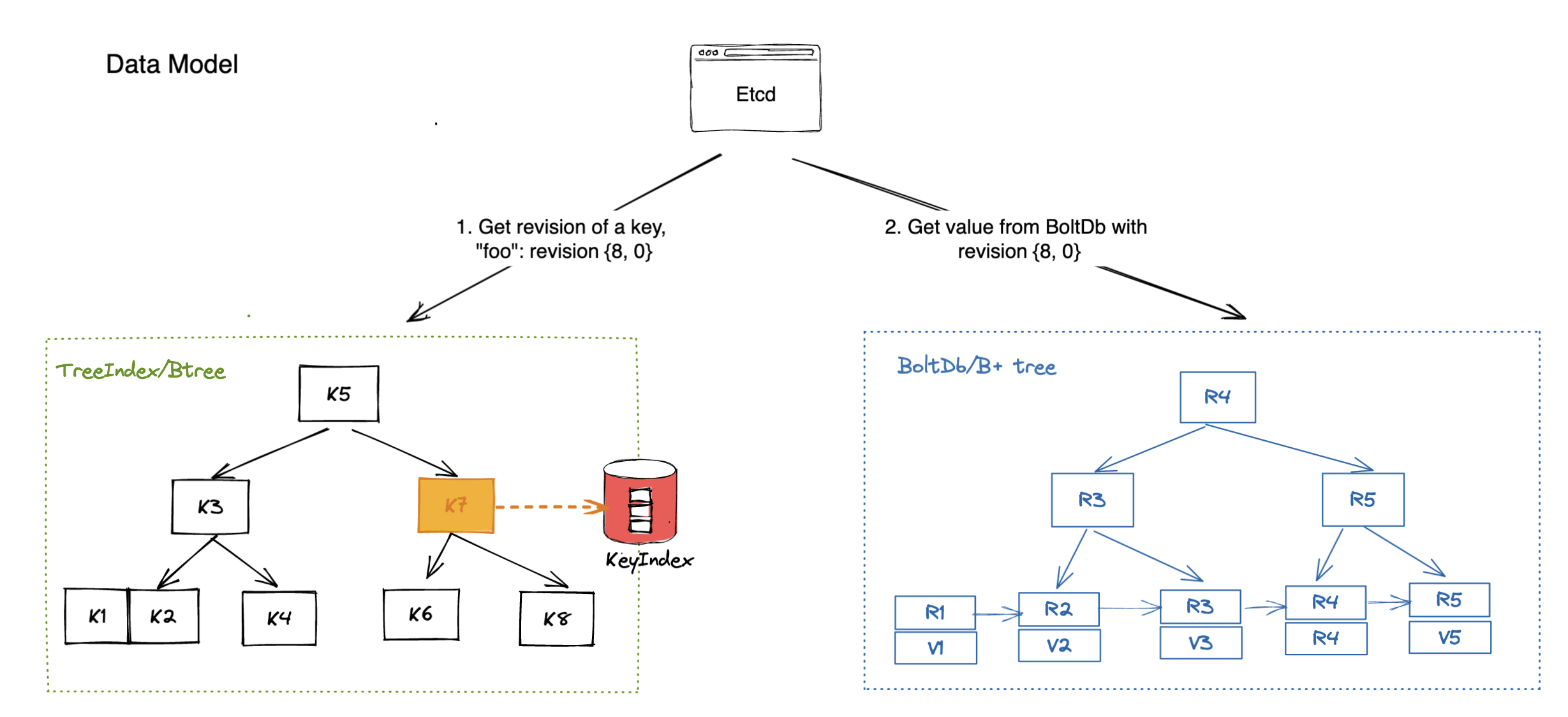
When the control plane dies, all your kubectl knowledge becomes useless. I spent way too long trying to run kubectl get pods while it hung for 45+ seconds before spitting out "Unable to connect to the server: dial tcp: i/o timeout". The API server was getting hammered with 20k+ requests/second, but I didn't know that because my monitoring went dark first. This is where you realize those performance thresholds actually matter.
The API server troubleshooting guide explains timeout configurations, while etcd monitoring helps track control plane health. kubectl timeout settings and client configuration become critical during outages.
The vicious cycle that will ruin your night:
- Something stupid happens - A new monitoring agent, some intern's config change, or resource exhaustion hits your API server
- DNS shits the bed - Services can't find each other because DNS needs the control plane, but the control plane is busy dying
- Nodes start panicking - Kubelet can't talk to the API server, so nodes go "Not Ready" and everything goes to hell
- Your debugging tools abandon you - kubectl hangs, monitoring dies, and you're left staring at spinning cursors while revenue bleeds
The worst part? Your applications might be perfectly healthy, but they're isolated in their own little islands because the networking fabric fell apart. DNS can't find services, pods can't talk to each other, and everything looks broken even though the actual apps are fine.
CoreDNS troubleshooting covers DNS failures, while kubelet debugging explains node communication issues. Network policy debugging and service mesh troubleshooting help diagnose networking failures.
The OpenAI Disaster: When Observability Kills Your Cluster
OpenAI's December 2024 meltdown is every SRE's nightmare - they deployed a monitoring service that murdered their own clusters. Some genius decided to add telemetry to improve observability, but the service hammered the API server with requests that scaled with cluster size. Their huge clusters died first - I think it was like 7,500 nodes or something insane like that, maybe more, fucking massive - because the API calls scaled O(n²) and completely obliterated the control plane. Each node was making like 50+ API calls per minute, multiplied by thousands of nodes = API server death spiral.
Here's the really fucked up part: DNS caching hid the problem for a while. Everyone thought things were fine until the caches expired and suddenly nothing could resolve anything. By then, the API server was so overloaded they couldn't even rollback the deployment that caused it.
What actually happened (not the sanitized version):
- Deploy "harmless" telemetry service across hundreds of clusters
- Service makes expensive API calls * cluster_size (oops)
- Large clusters die first because n² scaling is a bitch
- DNS masks the problem for a while (false sense of security)
- Cache expires, services can't find each other, everything dies
- kubectl becomes useless, can't rollback the thing killing you
- Takes hours of parallel recovery because standard tools are fucked
This is why I always test new services on tiny clusters first. Scale kills you in ways you never expect.
Circular Dependencies (The Architecture That Bites You Back)
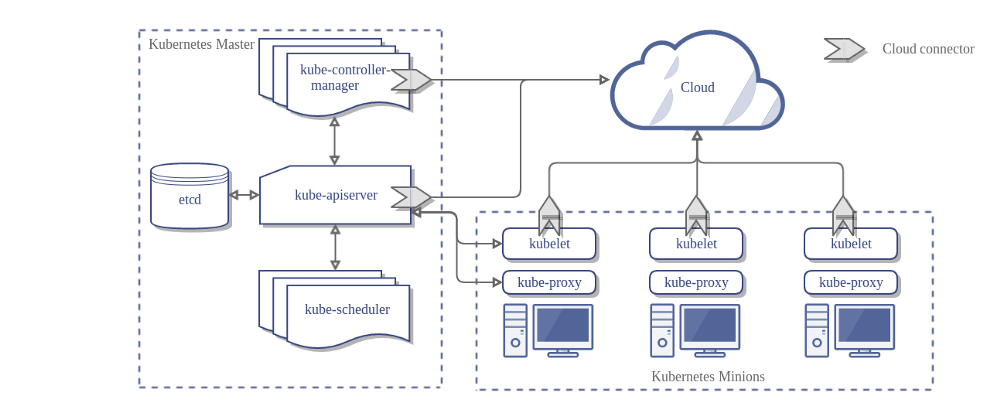
You know what makes cluster disasters extra fun? All those "clever" architectural decisions that seemed brilliant until they created circular death spirals. I learned this the hard way when our authentication service went down and took the entire service mesh with it, which prevented authentication from coming back up. Spent way too long in that deadlock - like 6 hours because Istio 1.17.x has this bug where service discovery fails silently when authentication is down.
The dependency hell that will ruin your weekend:
DNS needs the control plane, control plane needs DNS - Applications can't find services without DNS, but DNS can't resolve anything without a healthy API server. When the control plane chokes, DNS dies, and now your apps can't find the services needed to fix the control plane. It's like needing your car keys to get your car keys out of your locked car.
Monitoring dies when you need it most - Your monitoring infrastructure runs on the same cluster it's supposed to monitor. So when everything goes to hell, your dashboards go dark right when you're desperately trying to figure out what's broken. It's the most useless feature ever.
etcd and storage hate each other - etcd stores cluster state but might depend on cluster-managed storage. If storage fails, etcd can't maintain state. If etcd fails, you can't manage storage. I've seen this kill clusters for entire weekends.
Service mesh + auth = deadlock paradise - Service mesh needs authentication to secure traffic, auth service needs service mesh to communicate. When one dies, they both stay dead forever. Breaking this deadlock usually involves some ugly manual intervention.
When Scale Murders Your Cluster (Staging Never Reveals This Shit)

Large clusters fail in ways that small ones never do, which is why your 50-node staging environment gives you false confidence. I learned this the hard way when we hit around 1,000 nodes, maybe more, and suddenly operations that worked perfectly at 100 nodes brought the entire control plane to its knees. Scale is a cruel mistress - especially with Kubernetes 1.25+ where watch events can overwhelm the API server at scale.
The n² death spiral - Network policies, API calls, and node communication all scale quadratically with cluster size. That monitoring service that barely registers on your 100-node cluster? It'll murder your 1,000-node cluster because it's making 10x more API calls, not just 10% more.
When 1,000 things fail simultaneously - Resource exhaustion in large clusters isn't just worse, it's catastrophic. When 1,000 nodes run out of disk space at the same time, they all scream at the API server simultaneously, creating a secondary failure that kills the control plane. It's like a DDoS attack from your own infrastructure.
Multi-region clusters are split-brain hell - Geographic distribution sounds great until network partitions happen. I've spent entire nights debugging "split-brain" scenarios where half the cluster thinks it's healthy and the other half is panicking. The recovery procedures are completely different from single-region failures and infinitely more complex.
The Warning Signs (If You're Lucky)
Most cascade failures don't just appear instantly - they give you some warning signs if you know what to look for. I missed these signs during my first disaster and regretted it.
The control plane starts choking first:
- API response times get noticeably slow (your first real warning)
- etcd watch latency spikes (etcd is struggling)
- Control plane CPU/memory usage climbs rapidly
- Scheduler and controller-manager logs start showing timeout errors
Network fabric starts getting flaky:
- DNS queries take longer than usual
- Pod-to-pod connections become intermittent (this drove me insane for hours)
- Service discovery fails sporadically
- CNI logs fill with network policy errors
Everything runs out of resources simultaneously:
- Multiple nodes hit resource limits at once (not just one or two)
- PVCs start pending across namespaces
- Ingress controllers can't reach upstream services
- Image pulls timeout cluster-wide (this is when you know you're fucked)
How to Not Panic (And Avoid Making It Worse)
When everything's on fire, your brain wants to try every fix at once. Don't. I've seen smart engineers turn a 2-hour outage into an 8-hour disaster by panicking.
Shit that makes outages worse:
- Multiple people making changes without talking (coordination hell)
- Throwing more resources at the problem without understanding it (expensive and useless)
- Making rapid config changes without waiting to see results (thrashing)
- Switching between recovery approaches every 5 minutes (start over hell)
What actually works when you're stressed:
- One person calls the shots, everyone else follows orders
- Follow the runbook even when it feels slow (improvisation kills you)
- Parallel teams work on different problems (not the same problem)
- Updates every 15 minutes with actual status, not technical details that confuse management
Now that you understand how cluster disasters unfold and what warning signs to watch for, the next section covers what to actually do when kubectl stops working and you need to debug a cluster that's actively dying. Because understanding the theory is one thing - having commands that work at 3AM when everything's broken is what separates experienced engineers from those who panic.