Lambda Labs exists because AWS charges around $7/hour for H100s while Lambda charges $3/hour for the same hardware. That's it. That's the whole story.
I burned through a $600 AWS bill last month training a moderately-sized model. The same workload on Lambda? $250. Still pisses me off thinking about it.
What Actually Makes Lambda Different
No CUDA Dependency Hell: Every instance comes with Lambda Stack pre-installed. PyTorch, TensorFlow, CUDA drivers - all the versions that actually work together instead of the usual "install PyTorch" → "CUDA not found" → "reinstall drivers" → "now PyTorch won't import" death spiral. I've wasted entire weekends on this shit.
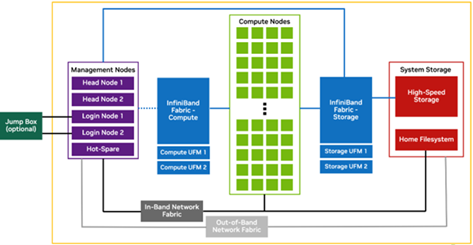
1-Click Clusters That Actually Work: Setting up multi-node training on AWS is a nightmare involving VPCs, security groups, EFA, and about 47 different services. I wanted to throw my laptop out the window debugging this shit. Lambda's 1-Click Clusters actually deploy in under 5 minutes with NCCL over InfiniBand working out of the box. I know because I've done both.

No Egress Fees: Download your 500GB model? Free. AWS would charge you $45 for that download. Those egress fees add up fast when you're iterating on models.
The Catch (Because There's Always a Catch)
Capacity is Limited: Good luck getting H100s during major PyTorch releases or conference deadlines. Lambda has way fewer machines than AWS. Plan ahead or you're screwed.
US Only: All their data centers are in the US. If you need EU data residency, you're out of luck. AWS has 87 regions, Lambda has like 3.
No Spot Instances: AWS has spot instances that are 70% cheaper if you can handle interruptions. Lambda is all on-demand pricing.
Real-World Performance Numbers
I ran a 7B model on both - Lambda was 47 minutes and cost $22. AWS took 52 minutes and cost $65. Had to double-check the bill because that price difference made no sense.
Performance difference? Like 10%. Price difference? Still hurts but not as brutal as I expected.
When to Use Lambda vs Alternatives
Use Lambda if: You want cheaper H100s, hate CUDA setup hell, need InfiniBand for multi-node training, or you're tired of AWS's complex billing.
Use AWS if: You need spot instances, require global data centers, want reserved instance discounts, or need enterprise compliance (HIPAA, FedRAMP, etc.).
Use RunPod if: You need even cheaper GPUs and can deal with consumer hardware like RTX 4090s.
The Lambda Stack Actually Works

Unlike AWS's "figure it out yourself" approach, Lambda pre-installs everything that matters:
- PyTorch 2.1.2 and CUDA 12.1 - the versions that actually work together. Everything else is whatever's latest stable
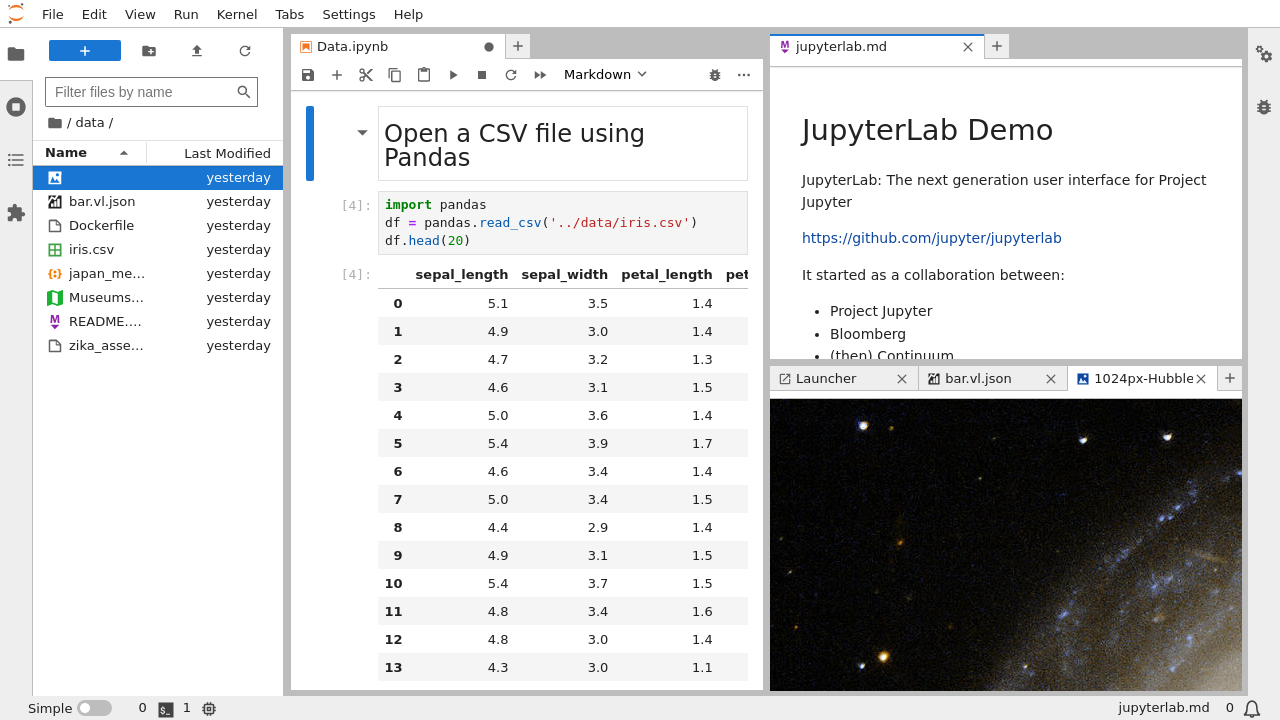
- Jupyter Lab for browser-based development
- All the NVIDIA drivers that actually work
No version conflicts. No "why won't CUDA see my GPUs" debugging at 3am. It just works.

Bottom Line for Engineers
Lambda saves you money and time. H100s cost around 60% less than AWS. Setup takes 5 minutes instead of 5 hours fighting with IAM policies. If you can live with US-only data centers and the occasional "no H100s available" during conference season, Lambda beats the hell out of AWS complexity.