The CUDA Development Toolkit is NVIDIA's parallel computing platform that lets you tap into thousands of GPU cores to accelerate computationally intensive workloads. Released in August 2025, CUDA 13.0 drops support for older GPUs and changes enough APIs to guarantee you'll spend a day fixing build errors.
At its core, CUDA transforms your NVIDIA GPU from a graphics renderer into a massively parallel processor. Instead of managing individual threads like traditional CPU programming, you write kernels that execute simultaneously across thousands of lightweight threads organized in thread blocks and grids. This Single Instruction, Multiple Thread (SIMT) model sounds elegant until you hit divergent branches and watch your performance tank.
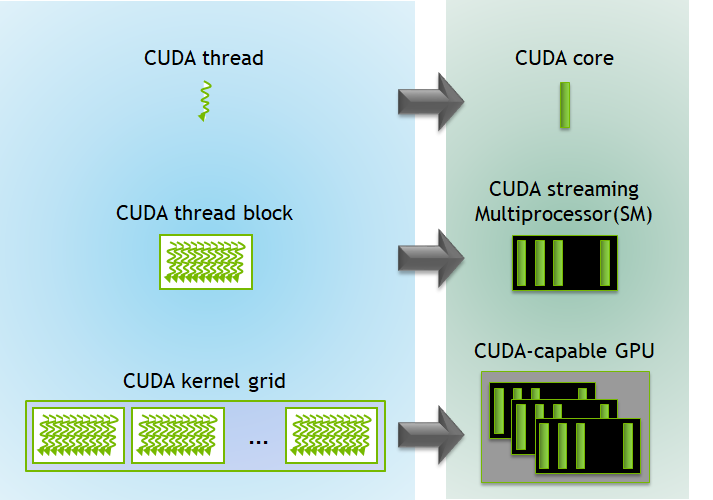
The Developer Reality
CUDA gives you access to raw GPU hardware through CUDA Runtime API and CUDA Driver API. The runtime API handles memory management and kernel launches automatically, while the driver API gives you low-level control at the cost of complexity. Most developers stick with the runtime API unless they enjoy debugging context management at 3am.
The platform includes everything developers need to get started: the `nvcc` compiler, debugging tools like `cuda-gdb`, profiling tools like Nsight Systems, and specialized libraries like cuBLAS and cuFFT. The catch? Each update breaks something. CUDA 13.0 removes support for Maxwell, Pascal, and Volta architectures (compute capability < 7.5), meaning if you're still running those GPUs, you're stuck with CUDA 12.x forever.
Memory Management Hell

CUDA's biggest learning curve isn't parallel programming concepts—it's memory management. You'll spend weeks figuring out the difference between `cudaMalloc`, `cudaMallocManaged`, and `cudaHostAlloc`. Unified Memory promised to solve this with cudaMallocManaged, letting you allocate memory accessible from both CPU and GPU. In practice, you'll still hit mysterious segfaults and performance cliffs.
Memory errors are CUDA's specialty. `CUDA_ERROR_UNKNOWN` tells you absolutely nothing. `cudaErrorInvalidValue` could mean anything from misaligned pointers to exceeding thread limits. The error messages are so generic that Stack Overflow has better debugging advice than official documentation.
CUDA 13.0 Breaking Changes

The latest release introduces several "improvements" that'll break your existing code:
- Blackwell Architecture Support: New compute capability 10.0 for B200/B300 GPUs and RTX 5000 series
- ZStd Compression: Fatbin compression switched from LZ4 to ZStandard, reducing binary size by up to 17%
- Unified Arm Support: Single installation now works across server and embedded Arm platforms
- Vector Type Changes:
double4,long4, and friends are deprecated in favor of_16aand_32aaligned variants - Green Contexts: Lightweight contexts for better resource isolation on supported hardware
The Tile Programming Future
CUDA 13.0 introduces foundational support for tile-based programming, complementing the existing thread-parallel model. Instead of managing thousands of individual threads, you'll work with tiles of data and let the compiler handle thread distribution. This sounds great until you realize it's mostly infrastructure work—the actual programming model won't arrive until later 13.x releases.
The tile model promises to map naturally onto Tensor Cores, NVIDIA's specialized matrix processing units. Whether this actually simplifies GPU programming or just adds another layer of complexity remains to be seen.
CUDA remains the de facto standard for GPU computing because nothing else comes close to its ecosystem. Just don't expect the learning curve to get easier.