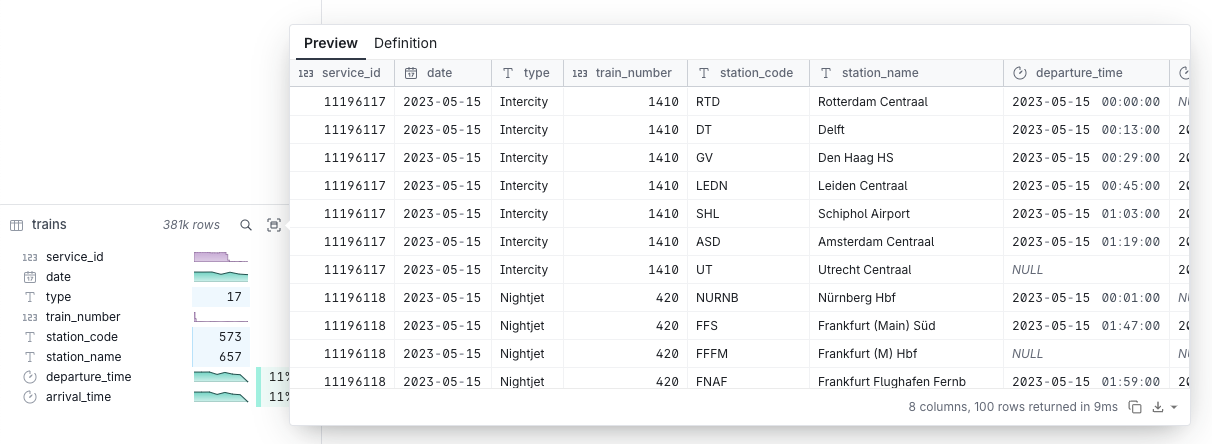
DuckDB solves the "my laptop can't handle this dataset but Spark is overkill" problem. It's basically SQLite for analytics - runs embedded in your process, handles datasets that break pandas, and doesn't require a PhD in distributed systems.
Why It Actually Works
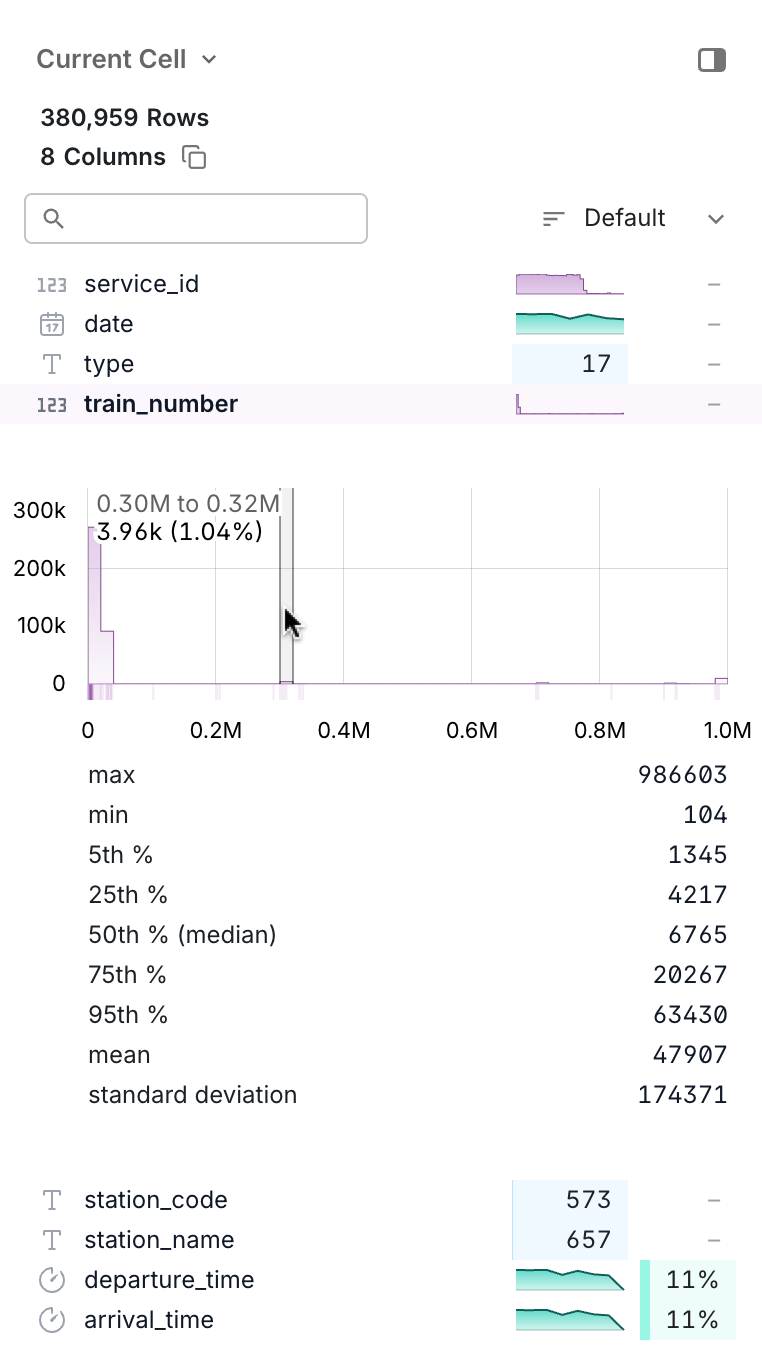
DuckDB stores data in columns instead of rows, which makes aggregations way faster. When you want to sum millions of numbers, it processes them in batches instead of one-by-one like traditional databases.
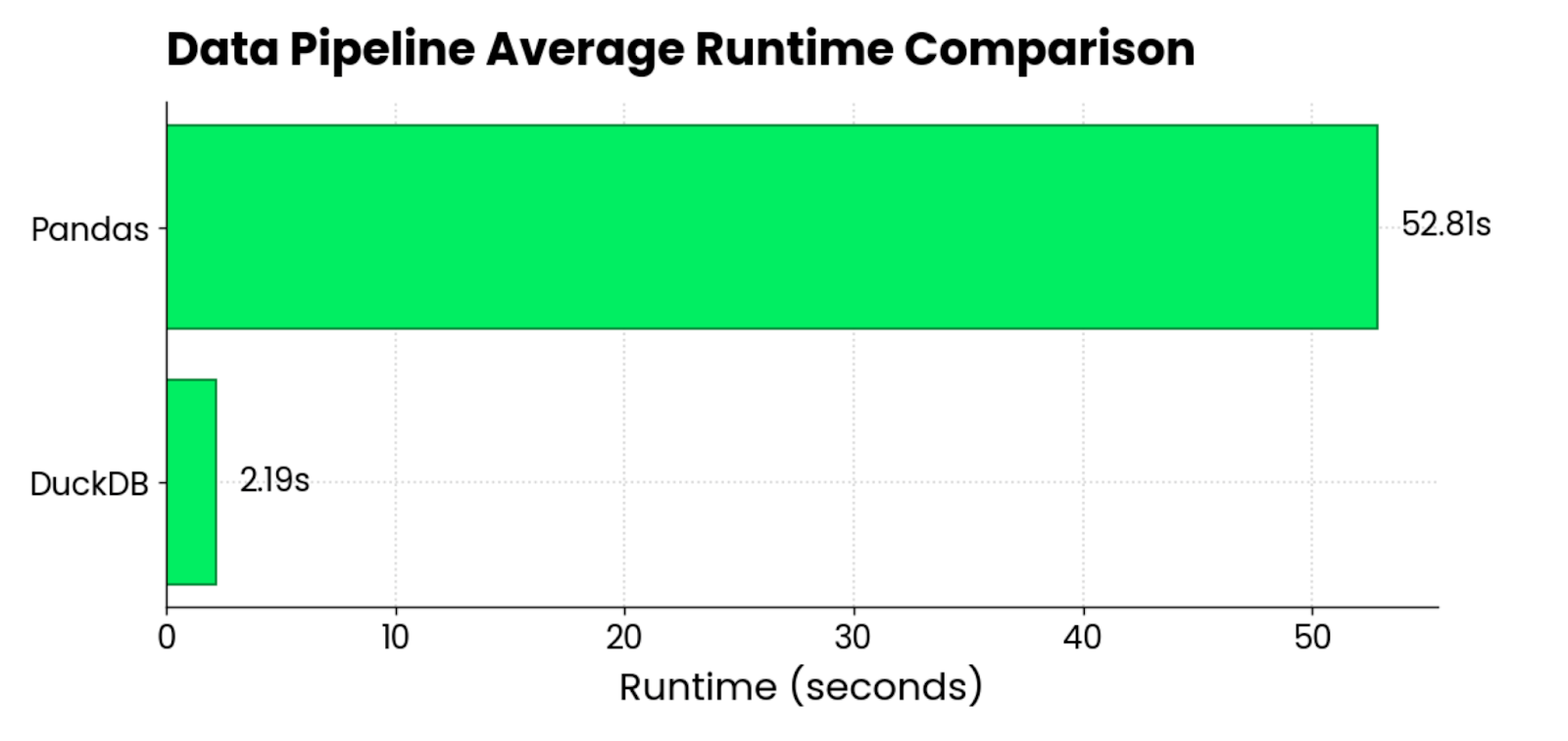
I threw a 40-something GB CSV at it on my MacBook and pandas just gave up after eating all my RAM. DuckDB handled it in maybe 30 seconds? Could've been a minute, I wasn't timing it exactly. No distributed computing bullshit, just better architecture.
The in-process thing means no network bullshit, just direct memory access. Setup is literally pip install duckdb and you're done. Sometimes.
SQL That Doesn't Make You Cry
![]()
DuckDB speaks PostgreSQL SQL, so if you know Postgres, you already know DuckDB. Window functions, CTEs, complex joins - they all work exactly like you'd expect. Over 200 functions that actually do useful things.
Actually useful features:
- Advanced analytics functions (percentiles, window functions)
- Complex data types (arrays, JSON, nested structs)
- Modern SQL features (CTEs, recursive queries)
- PostgreSQL compatibility (not some weird proprietary dialect)
Data Integration Without the ETL Hell
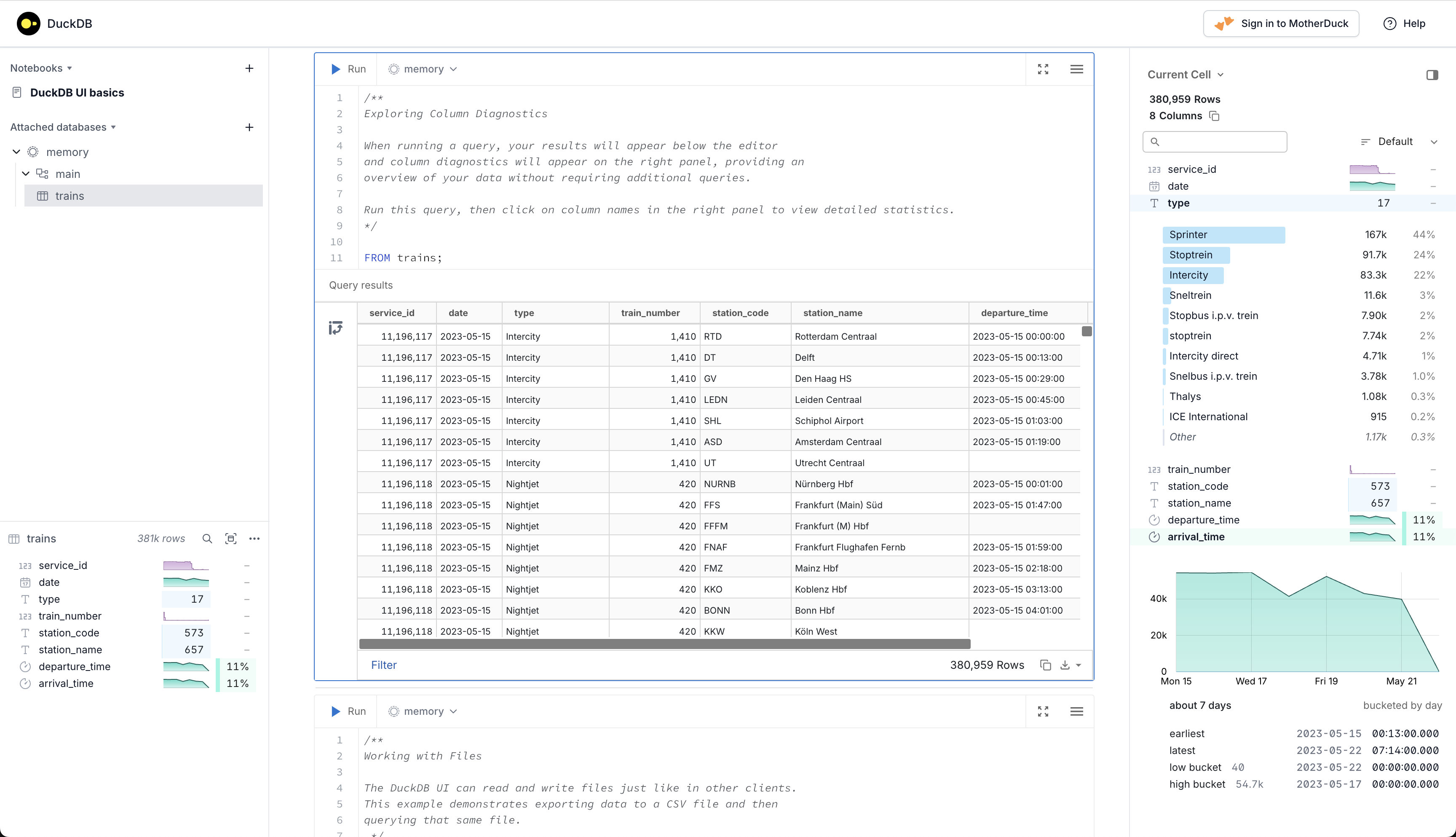
Here's where DuckDB really shines - it reads Parquet, CSV, JSON directly. No ETL pipeline, no data loading step, no waiting 3 hours for imports. Point it at a 10GB Parquet file in S3 and query it like a local table.
Python integration actually works. Query pandas DataFrames with SQL, get results back as DataFrames. Similar integration for R, Java, Node.js. It fits into existing data science workflows instead of requiring you to rewrite everything.
import duckdb
import pandas as pd
## This actually worked on the first try, which never happens
df = pd.read_csv('huge_data.csv') # Usually there's some dependency conflict
result = duckdb.query("SELECT category, AVG(revenue) FROM df GROUP BY category").df()