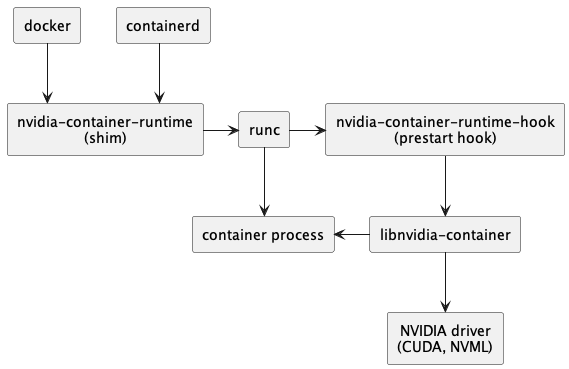
Most Docker Compose GPU tutorials show toy examples with a single container. Real production setups need multiple containers sharing GPUs, proper resource limits, monitoring, and failover handling. Here's what actually works when you have $50k in AWS bills riding on your GPU containers.
The Production-Ready Docker Compose Template
This isn't a "hello world" - it's a battle-tested setup I've deployed across dozens of production environments. It handles GPU sharing, resource constraints, health checks, and monitoring:
version: '3.8'
services:
# Primary ML inference service
inference-api:
image: nvidia/pytorch:24.08-py3
deploy:
resources:
reservations:
devices:
- driver: nvidia
device_ids: ['0']
capabilities: [gpu]
environment:
- NVIDIA_VISIBLE_DEVICES=0
- CUDA_VISIBLE_DEVICES=0
- NVIDIA_DRIVER_CAPABILITIES=compute,utility
volumes:
- ./models:/app/models:ro
- nvidia_ml_repos:/app/workspace
ports:
- "8080:8080"
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:8080/health"]
interval: 30s
timeout: 10s
retries: 3
start_period: 60s
restart: unless-stopped
logging:
driver: "json-file"
options:
max-size: "100m"
max-file: "5"
# Background processing service sharing GPU
batch-processor:
image: nvidia/tensorflow:24.08-tf2-py3
deploy:
resources:
reservations:
devices:
- driver: nvidia
device_ids: ['0']
capabilities: [gpu]
environment:
- NVIDIA_VISIBLE_DEVICES=0
- CUDA_VISIBLE_DEVICES=0
- CUDA_MPS_ENABLE_PER_CTX_DEVICE_MULTIPROCESSOR_PARTITIONING=1
volumes:
- ./data:/app/data:ro
- ./output:/app/output
depends_on:
inference-api:
condition: service_healthy
restart: unless-stopped
# GPU monitoring and metrics
gpu-exporter:
image: mindprince/nvidia_gpu_prometheus_exporter:0.1
restart: unless-stopped
ports:
- "9445:9445"
deploy:
resources:
reservations:
devices:
- driver: nvidia
capabilities: [gpu]
# Redis for job queuing
redis:
image: redis:7-alpine
ports:
- "6379:6379"
volumes:
- redis_data:/data
restart: unless-stopped
volumes:
nvidia_ml_repos:
redis_data:
GPU Resource Management in Production
The biggest production nightmare is containers fighting over GPU memory. Here's how to prevent your containers from stepping on each other:
Memory Limit Enforcement:
environment:
- CUDA_MEMORY_POOL_LIMIT=50 # Limit to 50% of GPU memory
- TF_FORCE_GPU_ALLOW_GROWTH=true # TensorFlow-specific
- PYTORCH_CUDA_ALLOC_CONF=max_split_size_mb:512 # PyTorch memory fragmentation fix
For detailed GPU memory management strategies, see NVIDIA's CUDA Best Practices Guide and TensorFlow GPU Memory Growth.
MPS (Multi-Process Service) Setup:
When you need multiple containers sharing a single GPU efficiently, NVIDIA MPS is your friend:
sudo nvidia-smi -i 0 -c EXCLUSIVE_PROCESS
sudo nvidia-cuda-mps-control -d
Then in your compose file:
environment:
- CUDA_MPS_PIPE_DIRECTORY=/tmp/nvidia-mps
- CUDA_MPS_LOG_DIRECTORY=/tmp/nvidia-log
Health Checks That Actually Work
Don't just check if your container is running - check if the GPU is accessible and performing:
healthcheck:
test: |
python -c "
import torch
assert torch.cuda.is_available(), 'CUDA not available'
assert torch.cuda.device_count() > 0, 'No CUDA devices'
x = torch.randn(1000, 1000).cuda()
y = torch.mm(x, x.t())
assert y.device.type == 'cuda', 'GPU computation failed'
print('GPU health check passed')
"
interval: 60s
timeout: 30s
retries: 3
The Production Gotchas Nobody Tells You
Container Init Process Issues:
Your containers might hang during GPU initialization. This usually happens when multiple containers start simultaneously and compete for GPU resources during CUDA context creation.
Solution: Use depends_on with health checks and stagger container startup:
depends_on:
inference-api:
condition: service_healthy
Driver Version Mismatches:
Works in dev, breaks in prod because your production hosts have different driver versions. Always pin your base images:
image: nvidia/cuda:12.2-devel-ubuntu22.04 # Pin exact versions
Permission Disasters:
AppArmor, SELinux, or container security policies can block GPU device access. I spent 6 hours debugging this on a fresh Ubuntu 22.04 install - AppArmor was blocking access to /dev/nvidiactl. Check Docker security and AppArmor documentation for proper configuration.
Check:
docker run --rm --gpus all nvidia/cuda:12.2-base-ubuntu22.04 ls -la /dev/nvidia*
Network Issues:
GPU containers often need to communicate with each other for distributed training. Make sure your compose networks are configured properly:
networks:
gpu-network:
driver: bridge
ipam:
config:
- subnet: 172.20.0.0/16
Monitoring GPU Utilization
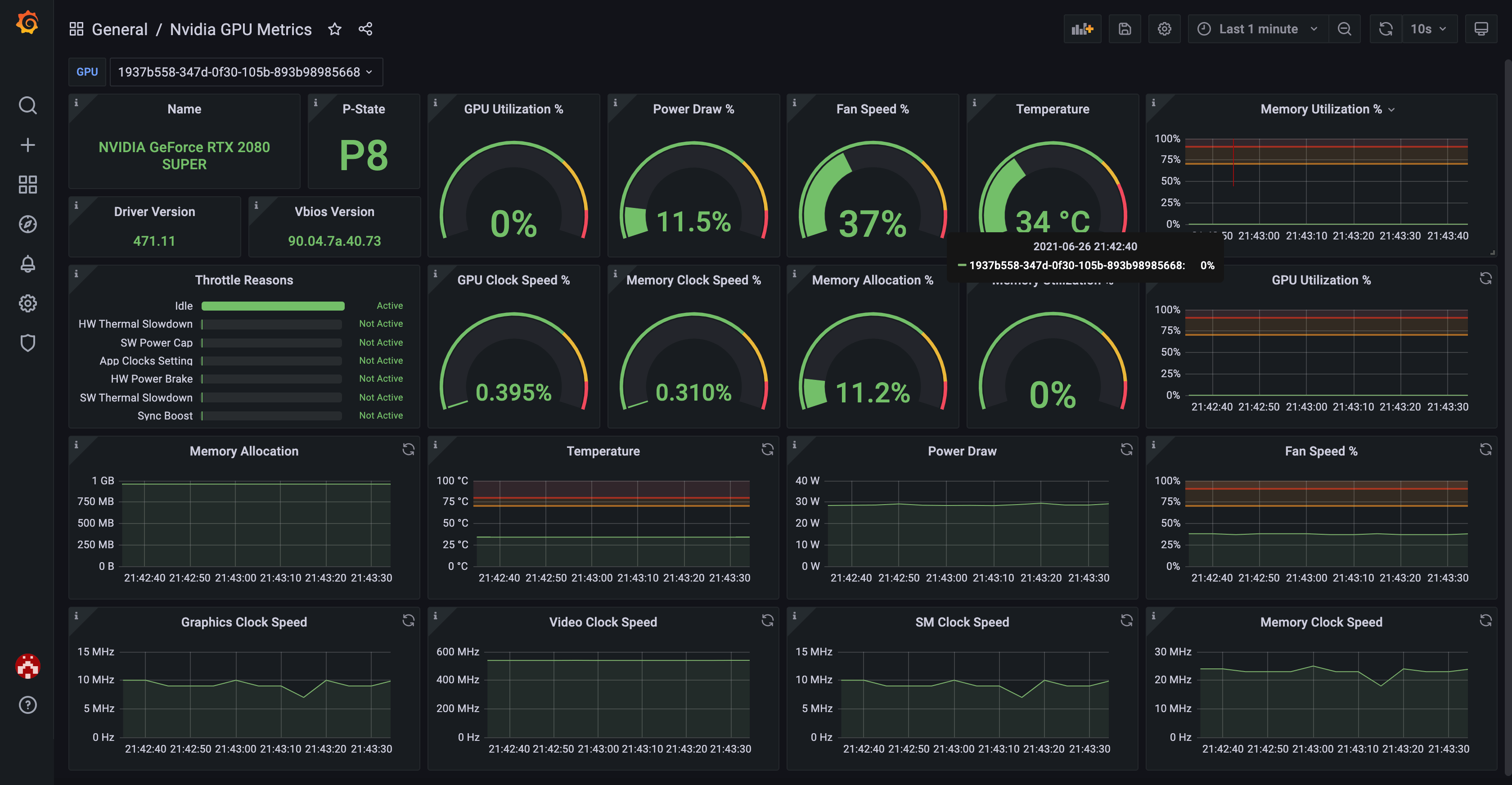
You need visibility into what your GPUs are doing. This Prometheus + Grafana setup gives you the metrics that matter:
prometheus:
image: prom/prometheus:latest
ports:
- "9090:9090"
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
restart: unless-stopped
grafana:
image: grafana/grafana:latest
ports:
- "3000:3000"
environment:
- GF_SECURITY_ADMIN_PASSWORD=admin
volumes:
- grafana_data:/var/lib/grafana
restart: unless-stopped
Key metrics to track:
- GPU utilization percentage
- GPU memory usage
- Temperature and power consumption
- CUDA context switches
- Container-level GPU usage
Real talk: I once spent 2 hours debugging why our ML pipeline was running slow, only to discover that one rogue container was hogging 90% of GPU memory doing nothing useful.
Load Balancing Multiple GPUs
When you have multiple GPUs, you want to distribute containers across them intelligently:
services:
worker-gpu0:
<<: *worker-template
environment:
- NVIDIA_VISIBLE_DEVICES=0
- CUDA_VISIBLE_DEVICES=0
deploy:
resources:
reservations:
devices:
- driver: nvidia
device_ids: ['0']
capabilities: [gpu]
worker-gpu1:
<<: *worker-template
environment:
- NVIDIA_VISIBLE_DEVICES=1
- CUDA_VISIBLE_DEVICES=1
deploy:
resources:
reservations:
devices:
- driver: nvidia
device_ids: ['1']
capabilities: [gpu]
Using YAML anchors (<<: *worker-template) keeps your compose file DRY and maintainable.
This setup has saved my ass in production more times than I can count. The health checks catch issues before they cascade, the resource limits prevent container wars, and the monitoring gives you visibility when things go sideways at 2am.
For additional Docker Compose best practices, see Docker's official production guide and NVIDIA's Container Toolkit documentation.