Got an NVIDIA GPU and want to use it in Docker? Without this toolkit, Docker completely ignores your GPU. Your containers crawl along on CPU while your expensive graphics card sits there doing nothing.
The NVIDIA Container Toolkit fixes this disaster. Version 1.17.8 dropped on May 30, 2025, and honestly, it's the only way that actually works. Before this existed, you'd spend days manually mounting /dev/nvidia* devices and copying driver files around like an animal.
Here's what actually happens: when you run a container that needs GPU access, the toolkit automatically mounts the right driver files and sets up all the CUDA libraries your container needs. No more manually mounting /dev/nvidia0 or copying driver files around like some caveman.
How It Actually Works
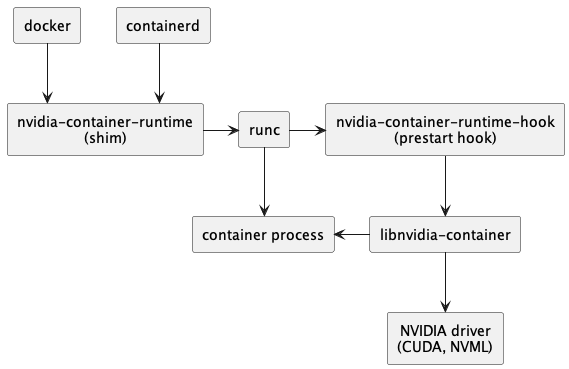
The toolkit has four main pieces that do the heavy lifting:
nvidia-container-runtime - Wraps Docker's runtime and tells it "this container wants GPU access." Works with Docker, containerd, whatever.
nvidia-container-toolkit - The hook that runs before container start. Figures out which GPU files to mount and does the setup. This replaced the old nvidia-docker2 mess that nobody misses.
libnvidia-container - The low-level library doing the heavy lifting. Mounts devices, injects CUDA libraries, discovers GPUs. This is where the actual work happens.
nvidia-ctk - Command line tool for configuration. You'll use this to set up Docker daemon configs and generate CDI specs.
The flow: Docker sees --gpus all → toolkit hook runs → mounts driver files → CUDA libraries appear → your container can finally see the GPU. It's automated device passthrough that doesn't suck.
What Actually Works (And What Doesn't)
![]()
Docker Engine - This is where it all started and works best. If you're running Docker on Ubuntu or RHEL, you'll probably have a good time. The installation guide is actually decent.
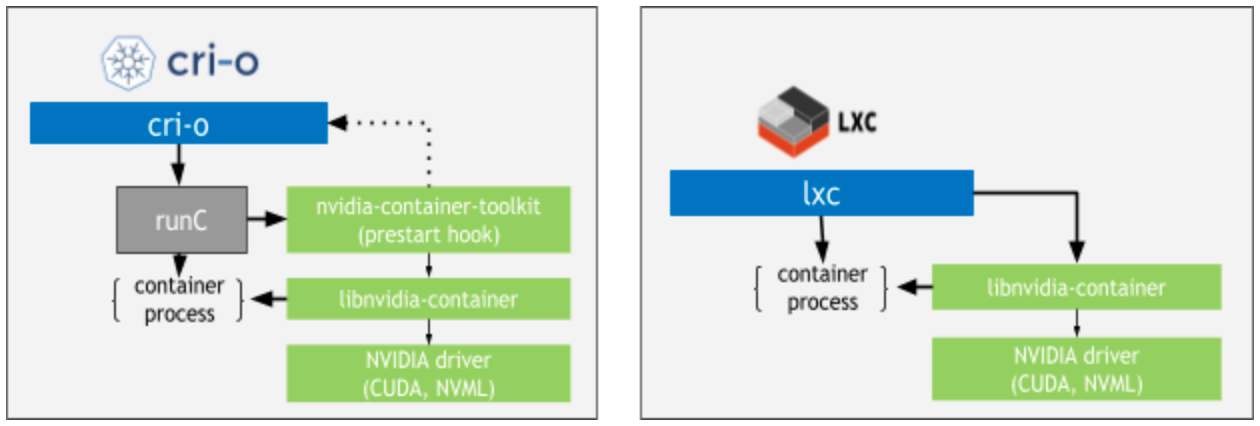
containerd - Kubernetes uses this by default. Works fine once you get past the initial setup headaches. Configuration is more involved than Docker, and you'll need to understand CRI plugins.
Podman - Great for rootless containers, but the GPU support is still a bit janky. Expect to spend extra time troubleshooting cgroup issues.
CRI-O - OpenShift's container runtime. Works but you'll be reading a lot of Red Hat docs.
For orchestration:
Kubernetes is the most popular orchestration platform for GPU containers.
- Kubernetes: Use the NVIDIA GPU Operator. It handles most of the complexity but debugging GPU scheduling issues will make you question your life choices.
- Docker Swarm: Technically supported but GPU scheduling is primitive
- Everything else: You're on your own, check the supported platforms list
What You'll Actually Use This For
Machine Learning: Training PyTorch models or running TensorFlow inference without your containers falling back to CPU. Companies like Uber use this for their ML pipelines because it actually works at scale. Popular frameworks include RAPIDS, Hugging Face, and JAX.
CUDA Applications: Any scientific computing or data processing that needs serious GPU power. Molecular dynamics, weather simulations, crypto mining (yes, people containerize mining). Check out NVIDIA HPC containers for pre-built images.
Graphics Workloads: OpenGL/Vulkan apps in containers. Useful for remote rendering or running CAD software in the cloud. You'll need X11 forwarding or VNC setups.
Check out NVIDIA's official CUDA container images for pre-built containers.
Jetson Edge Devices: GPU containers on NVIDIA Jetson hardware. Works but the ARM ecosystem can be painful. Check the Jetson containers repo for pre-built images.
The real benefit is that once you get this working, your containers behave the same way whether they're running on your dev laptop, a beefy DGX server, or in AWS EC2 P4 instances. No more "works on my machine but not in production" GPU disasters.
Just remember: the toolkit handles mounting drivers and CUDA libraries automatically, but you still need to actually install the NVIDIA drivers on your host. The containers don't magically create GPUs out of thin air.