Every month it's the same shit: AWS bill comes in 50% higher than expected and nobody knows why. Your EKS cluster is burning through money but AWS Cost Explorer just shows you EC2 instance costs. Useless.
The \"My Bill Exploded\" Problem
Here's what actually happens: Your data team spins up a Jupyter notebook for some "quick analysis" and accidentally leaves a model training job running all weekend. Meanwhile, your dev teams are deploying pods with CPU requests of 2 cores that actually use 0.1 cores. Nobody notices until the monthly AWS bill shows up at $47k instead of $30k.
Real production horror stories:
- ML team's TensorFlow job ran on GPU nodes for 3 weeks straight - cost $12k
- Staging namespace using production-sized RDS instances - nobody turned it off
- Persistent volumes growing to 500GB because log rotation was broken
- LoadBalancer services left running in 12 different namespaces
KubeCost Shows You Where the Money Goes
This is where KubeCost saves your sanity (and budget). Instead of staring at meaningless EC2 line items, you get actual answers.
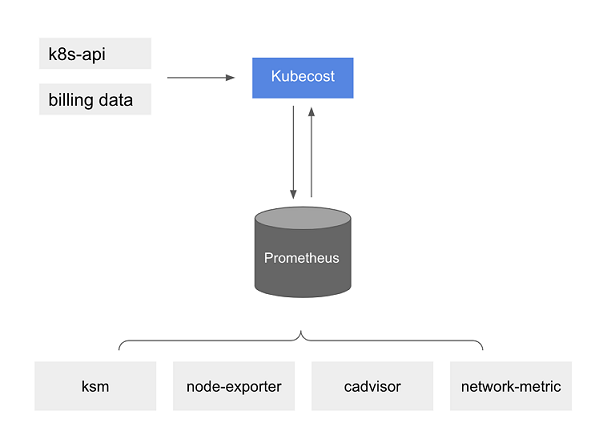
KubeCost deploys as a pod in your cluster and scrapes Prometheus metrics to figure out exactly what's consuming resources. It then applies real AWS pricing data to show you costs down to the individual pod level.
The architecture is straightforward: KubeCost runs in your cluster, connects to Prometheus for resource metrics, pulls pricing data from cloud providers, and serves a web UI for cost visibility.
What you actually get:
- Pod-level costs: "That Redis pod costs $47/month"
- Namespace breakdown: "QA environment is costing $8k/month"
- Idle resource detection: "You have $3k/month of unused CPU"
- Network costs that AWS hides in separate line items
Works with GKE, AKS, and even on-premises clusters if you hate yourself enough to run K8s on bare metal.
IBM Bought Them (September 2024)
IBM acquired KubeCost for their Apptio portfolio. Good news: Enterprise features actually work now. Bad news: Expect pricing to go up. The free tier still exists (up to 250 CPU cores) but enterprise features cost real money.
What changed post-acquisition:
- Better multi-cluster federation
- Actual support instead of "check our Slack"
- Integration with IBM's FinOps tools
- More reliable RBAC integration
- KubeCost 2.7 (April 2025) added enhanced cost visibility and reporting flexibility
- Free trial of Enterprise Cloud extended through the rest of 2025

Links you'll actually need:
- Official installation guide (use this, not the old docs)
- Helm chart repo (where the real config lives)
- AWS EKS integration docs (AWS finally documented it properly)
- Community Slack (for when things break at 3am)
- GitHub issues (where the real problems are documented)
- r/kubernetes cost management thread (real user experiences)
- Cost optimization best practices (actually useful, not marketing fluff)