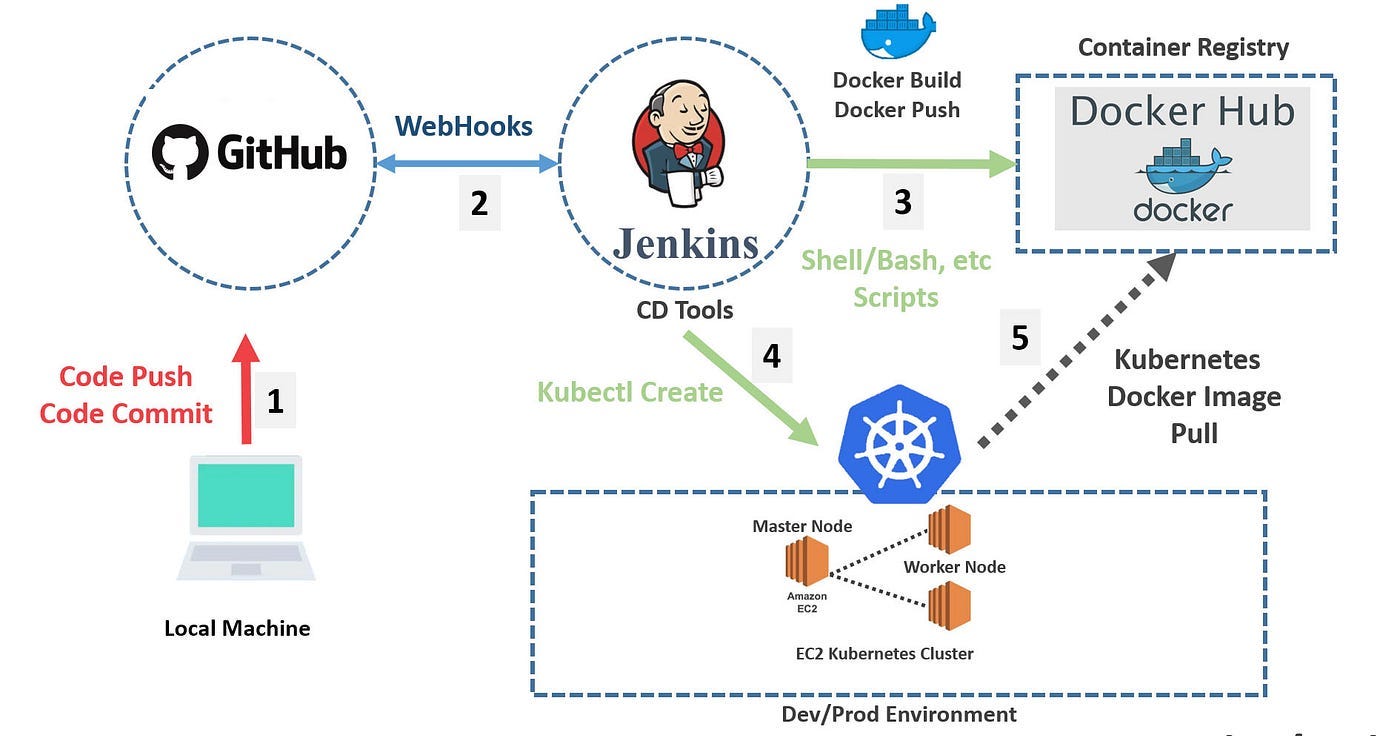
Here's the thing nobody tells you: Jenkins is a fucking dinosaur from 2005 that somehow became the backbone of half the internet's deployments. Docker is simple until you need to debug networking. And Kubernetes is powerful but will consume your entire DevOps team's time.
But they work together, and if you do it right, you can deploy code without breaking production. Usually.
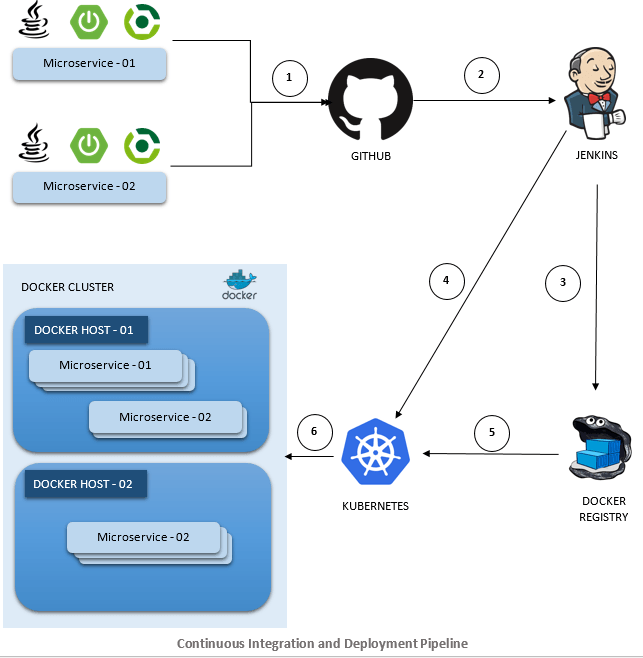
The Real Architecture (Not the Marketing Bullshit)
Jenkins is your build orchestrator - it's like the anxious project manager that keeps checking if everything's done. Docker packages your app into containers so it runs the same everywhere (in theory). Kubernetes is the cluster manager that's supposed to keep everything running but has opinions about literally everything.
Here's what actually happens: Developer pushes code → Jenkins freaks out and starts a build → Docker builds an image (hopefully) → Jenkins runs tests (which fail for mysterious reasons) → If everything passes, Kubernetes gets the image and tries to deploy it → Something breaks → You debug for 3 hours → Repeat.
I spent 6 months setting this up at my last job. The official docs are basically useless for the actual problems you'll hit.
Current State (September 2025): What's Actually Changed
The ecosystem keeps evolving, and not always for the better. Jenkins 2025 versions still have security issues coming out every few months. Kubernetes 1.31 is the current stable release, but if you're on cloud providers, you're probably stuck on whatever version they decide to support.
Docker's still Docker - works great until it doesn't. The main difference now is that everyone's trying to replace it with Podman or containerd, which just adds another layer of complexity to debug.
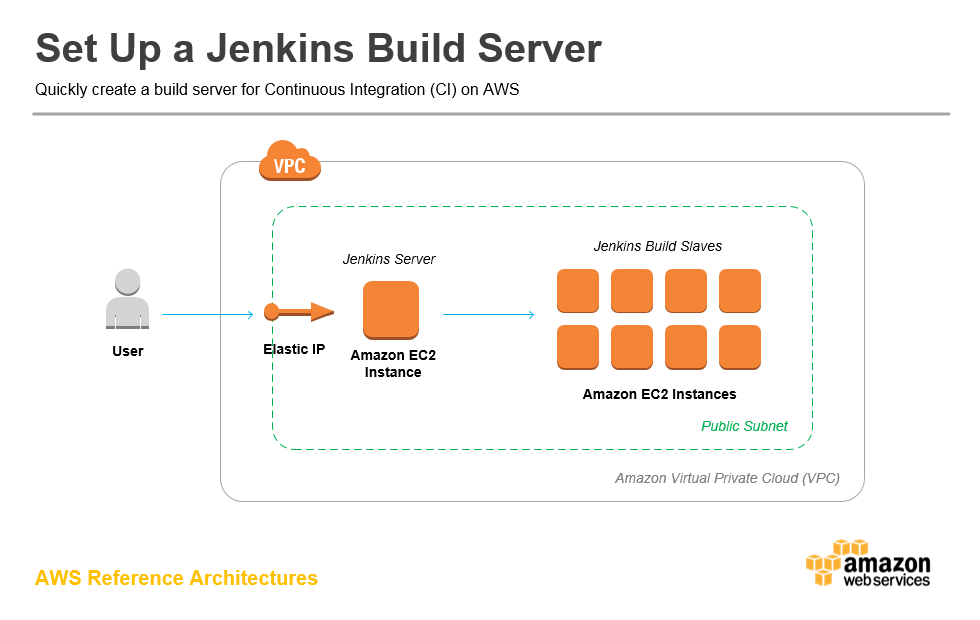
Jenkins: Maximum Flexibility, Maximum Pain

Jenkins has plugins for everything. That's both its strength and its curse. You'll start with a simple pipeline and end up with 47 plugins that all need different versions and break when you update anything.
The Kubernetes plugin sounds great - dynamic agents that spin up as pods! What they don't mention is that these agents randomly fail to connect, eat CPU like crazy, and the logs are completely useless when debugging.
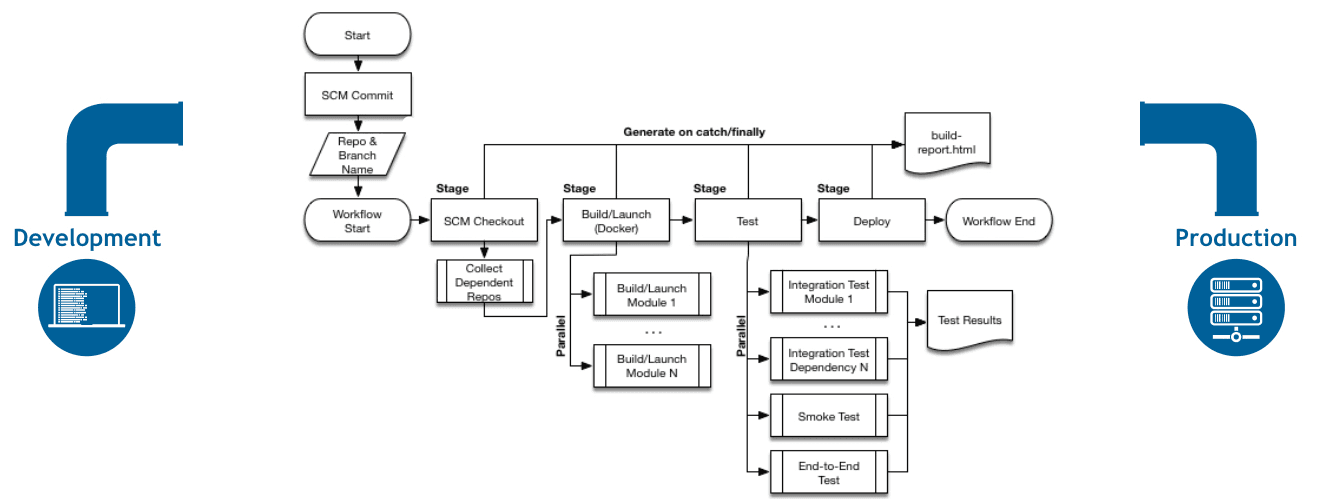
Pro tip: Use pipeline-as-code (Jenkinsfiles) or you'll lose your sanity maintaining freestyle jobs. Learned this the hard way when we had 200+ jobs and no idea what any of them actually did.
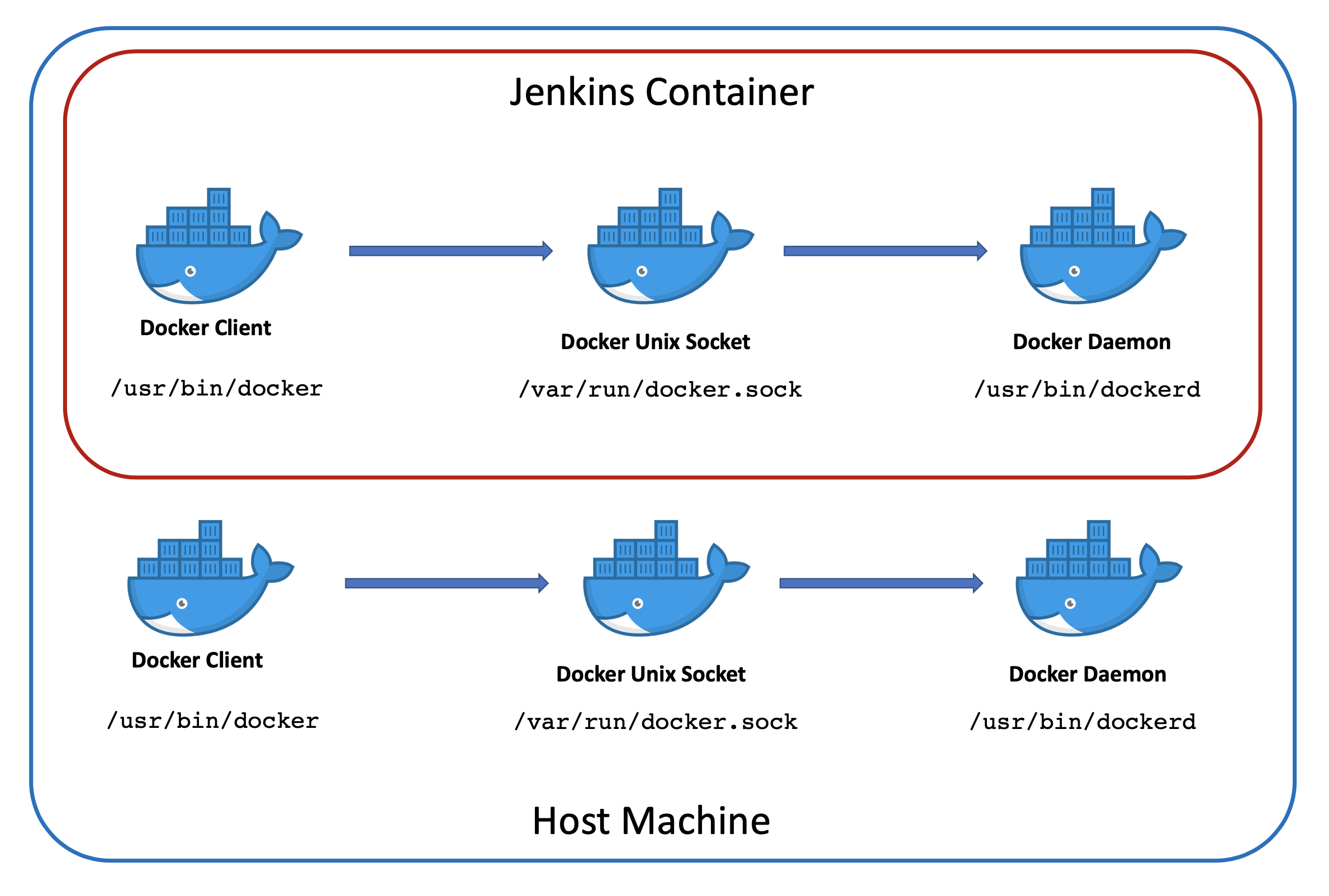
Docker: Simple Until It's Not
![]()
Docker containers are supposed to solve "works on my machine" problems. They do, mostly. But then you hit networking issues, and suddenly you're reading RFC documents at 2am trying to understand bridge networks.
Docker runs a daemon in the background that handles all the container stuff. When it crashes (and it will), everything stops working until you restart it.
Docker builds work great until your disk fills up with layers. Set up layer caching or your builds will take forever. Also, multistage builds are mandatory - nobody wants 2GB images in production.
The Docker daemon loves to randomly stop working. The universal fix is restart, which works about 80% of the time. The other 20%, you'll be googling cryptic error messages.
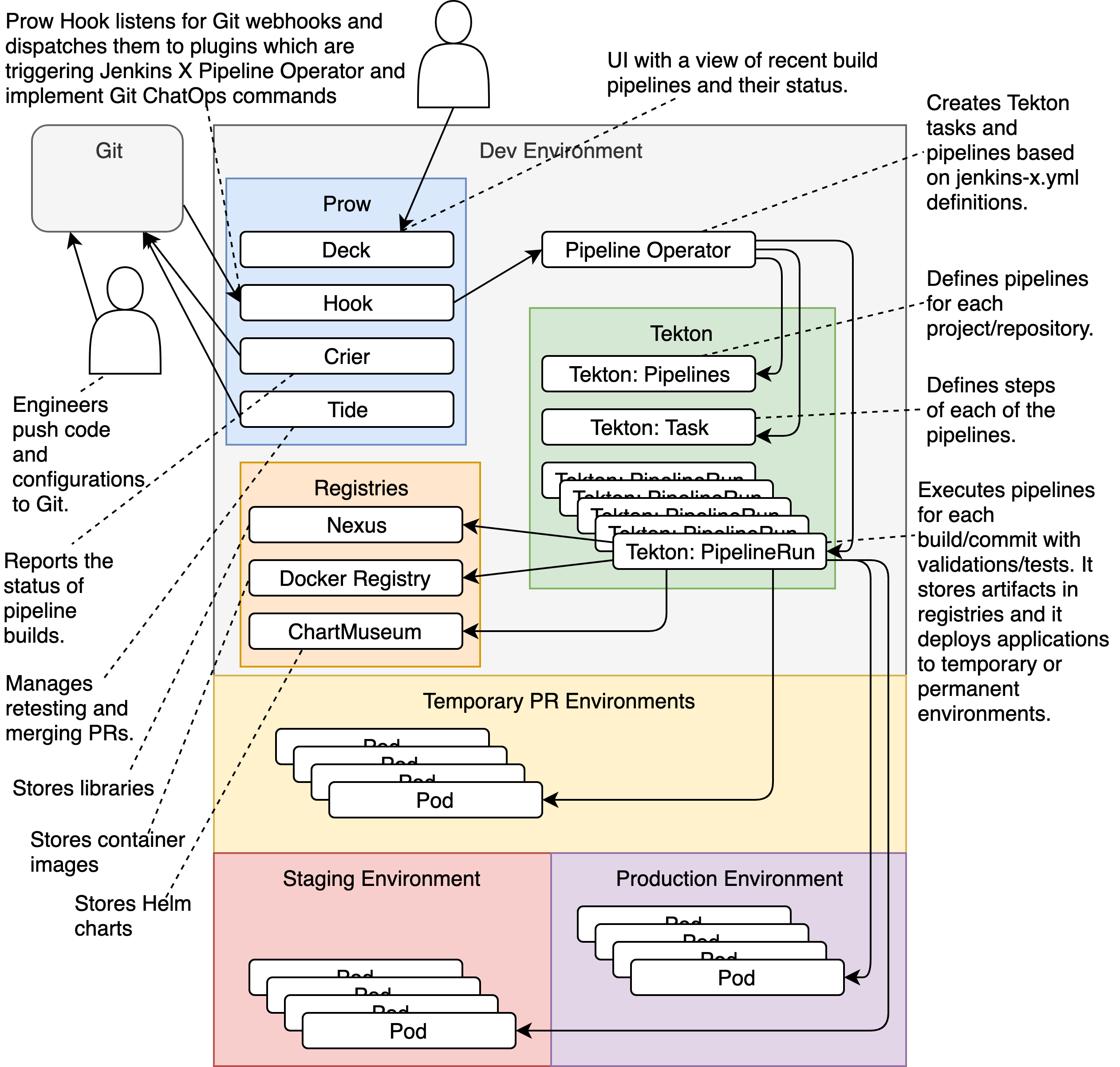
Kubernetes: The Overengineered Beast

Kubernetes can do everything. That's the problem - it's like using a nuclear reactor to heat your coffee. Most teams need maybe 10% of its features but spend 90% of their time fighting YAML files.
Kubernetes has a bunch of control plane services that coordinate everything. When any of them breaks, you'll get vague error messages that help nobody.
RBAC is like playing permission bingo. Everything fails with vague "forbidden" errors until you add the magic annotation that makes it work. The cluster will be fine for weeks, then suddenly nothing can pull images and you'll spend a day figuring out imagePullSecrets.
Pod startup times are unpredictable. Sometimes pods start in 10 seconds, sometimes 5 minutes. The scheduler has opinions you didn't know existed.
What Actually Works in Production
After breaking production more times than I care to count, here's what actually works:
- Keep Jenkins simple - Don't install every plugin. Each one is a potential failure point.
- Docker layer caching saves your sanity - Builds that take 2 minutes vs 20 minutes matter at scale.
- Kubernetes resource limits are mandatory - One pod eating all the CPU will take down your entire node.
- Rolling deployments with readiness probes - Kubernetes won't send traffic to broken pods, usually.
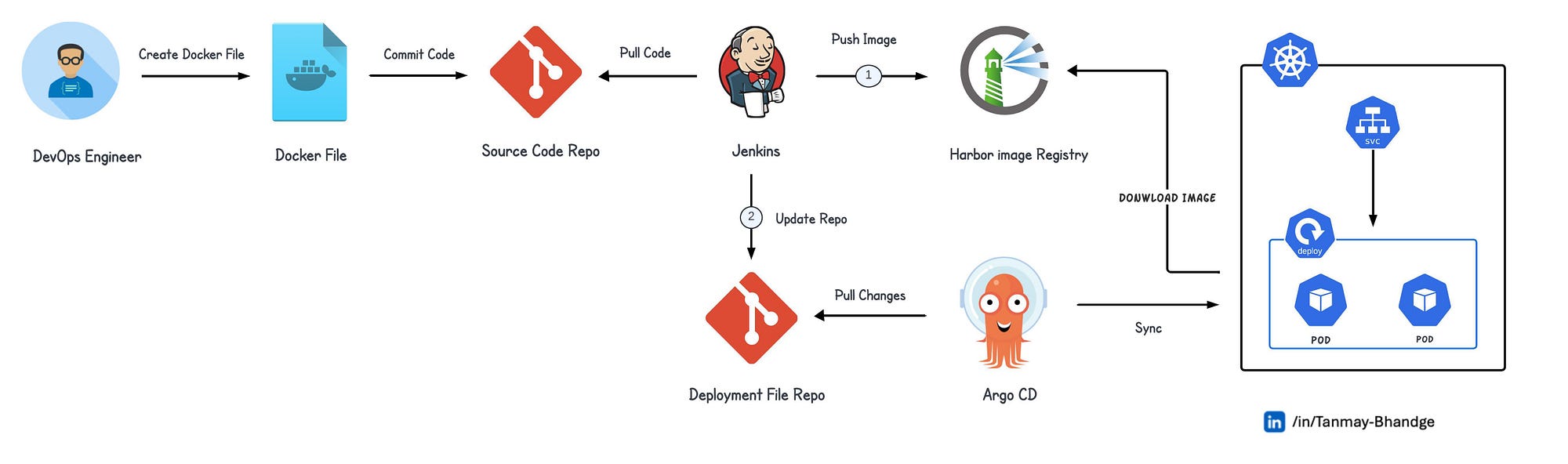
- Separate CI and CD - Jenkins builds and tests, something else (like ArgoCD) handles deployment.
The dirty secret: Most successful teams use Jenkins for CI and something simpler for CD. Kubernetes is great for running apps, terrible for deployment automation.
The Reality Check: What Success Actually Looks Like
Here's what a working setup looks like after 2 years of iteration:
Jenkins runs lightweight - No builds on the master, agents spin up for specific tasks and die. Pipeline libraries contain all the common patterns so teams don't write the same Groovy bullshit 50 times.
Docker images are boring - Alpine-based, multi-stage builds, and under 200MB. The fancy optimizations matter less than consistency.
Kubernetes clusters are cattle, not pets - Immutable infrastructure with everything in Git. When shit breaks, you replace it, not fix it.
The teams that succeed treat this stack like plumbing - boring, reliable, and invisible. The ones that fail get distracted by the latest Kubernetes features instead of focusing on shipping code.