Here's the thing nobody talks about: Kubernetes resource requests are basically educated guesses that cost you thousands every month. You set CPU requests to 500m "just to be safe," then watch your pods use 50m while you pay for the full allocation. Meanwhile, your memory requests are either too small (causing OOMKilled nightmares) or too big (burning cash on unused RAM).
Traditional monitoring tools love showing you pretty dashboards with "recommendations" that nobody implements because:
- Changing resource requests in prod is scary as hell
- Spot instances disappear during your most important demos
- Your HPA scales everything to the moon during traffic spikes
- Database costs somehow exceed your entire compute budget
CAST AI actually fixes this shit automatically across AWS EKS, Azure AKS, and Google GKE. Instead of giving you another dashboard to ignore, it watches your workloads for a few days, learns their actual patterns, then starts optimizing resources in real-time. The platform works with standard tools like Terraform, Helm, and integrates with Prometheus for monitoring.
What CAST AI Actually Does (Without the Marketing Bullshit)
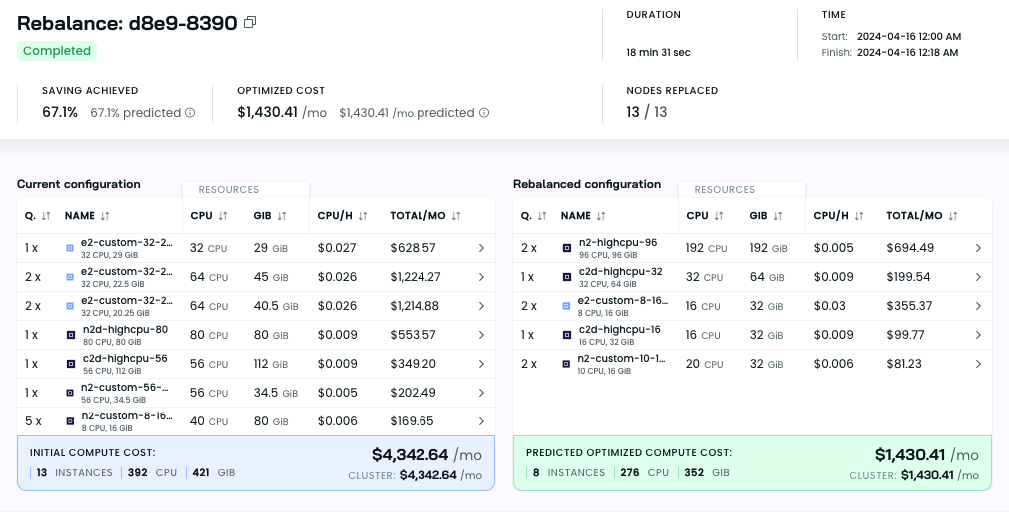
Pod Rightsizing That Doesn't Break Everything: Remember that service requesting 2GB RAM but using 200MB? CAST AI gradually reduces allocations while monitoring for performance issues. If something breaks, it backs off automatically. No more "let's just request 4 cores to be safe" conversations during 2am production incidents. Kubernetes added in-place pod resizing recently - still buggy as hell but CAST AI makes it work. I learned this the hard way after spending a weekend debugging OOMKilled errors that turned out to be caused by my "conservative" 128Mi memory limits.
Spot Instance Management That Actually Works: Spot instances are 70% cheaper until AWS yanks them during your product demo (seriously, why does this always happen during demos?). CAST AI handles the complex orchestration - it monitors pricing across instance types, automatically moves workloads before interruptions, and falls back to on-demand when spot capacity disappears. No more getting paged at 3am because your batch jobs got killed and your data pipeline is backed up for 6 hours. Our ETL jobs get killed by spot interruptions constantly - usually happens at the worst possible time during month-end processing when accounting needs the reports ASAP.
Node Bin-Packing Without the Tetris Nightmares: Instead of running 20 nodes at 30% utilization, it packs workloads efficiently onto fewer nodes. The algorithm considers CPU, memory, and network requirements to avoid the "everything crashes when one node dies" problem. Pro tip: nodes randomly fail to drain sometimes. When it happens, you get stuck manually cordoning everything like it's 2018.

Security Scanning That Finds Real Problems: Scans for exposed services, misconfigured RBAC, and vulnerable container images. More importantly, it prioritizes fixes based on actual exposure risk instead of generating 10,000 "critical" alerts for unused test clusters. Their security posture management solution launched in January 2025. Found 3 LoadBalancers with 0.0.0.0/0 access in our prod cluster that nobody knew about - including one for our internal admin panel that was basically a backdoor to everything.
Database Query Optimization Without Touching Code: The new Database Optimizer (DBO) automatically adds intelligent caching layers that intercept expensive queries. Your Rails app keeps making the same slow query 1000 times per minute, but now most hits come from cache instead of hammering Postgres. This autonomous caching solution requires zero code changes. Perfect for those N+1 queries you know you should fix but never have time for - took our Postgres load from 85% CPU to 40% in production without touching a single line of ActiveRecord. Fair warning: cache conflicts with Rails apps are common enough that you'll want to test thoroughly first.

AI Workload Cost Control: If you're running LLM inference workloads, this prevents you from accidentally spending $10k/month on GPT-4 calls when GPT-3.5 would work fine. The AI optimization features automatically route requests to cheaper models based on performance requirements.

Why Automation Actually Matters (And Why Manual "Optimization" Fails)
Here's the brutal truth: you'll never manually optimize Kubernetes costs. You'll set up Grafana dashboards, create Slack alerts, and hold weekly "cost optimization" meetings where everyone nods and nothing changes. Meanwhile, your AWS bill keeps growing because:
- Resource requests are set once during deployment and never touched again
- Nobody wants to risk breaking production by changing pod limits
- Spot instance management requires constant babysitting
- Performance testing with different resource allocations takes weeks
The 8 tips for Amazon EKS cost optimization, 10 steps for GKE cost optimization, and 10 tips for AKS cost optimization all point to the same conclusion: manual optimization doesn't scale.
We tried manual optimization for 6 months and saved maybe 10%. Then Black Friday hit and our "perfectly tuned" cluster crashed because we sized pods for normal traffic - spent 4 hours scaling everything back up while the site threw 503 Service Unavailable errors at customers. Marketing launched a surprise campaign the next week and the whole thing fell apart again. Turns out predicting load is harder than tuning a few YAML files.
CAST AI implements changes automatically because it has safety nets you don't. It can:
- Test resource reductions gradually with automatic rollbacks
- Monitor performance metrics in real-time during optimizations
- Handle spot instance interruptions without your 3am pager alerts
- Learn from patterns across thousands of similar workloads
Their 2025 Kubernetes Cost Benchmark Report (yeah, I actually read it) shows most organizations waste 40-60% of their Kubernetes spend on overprovisioned resources. The report analyzed actual usage from 2,100+ organizations across AWS, GCP, and Azure - turns out everyone makes the same expensive mistakes.
CAST AI raised $108 million in Series C funding in April 2025, bringing their valuation to around $850 million. They're calling their approach some fancy acronym, but it's just automation that actually works instead of breaking everything.
They've been busy in 2025 - new logo, better platform, and they added some database caching thing that actually works.
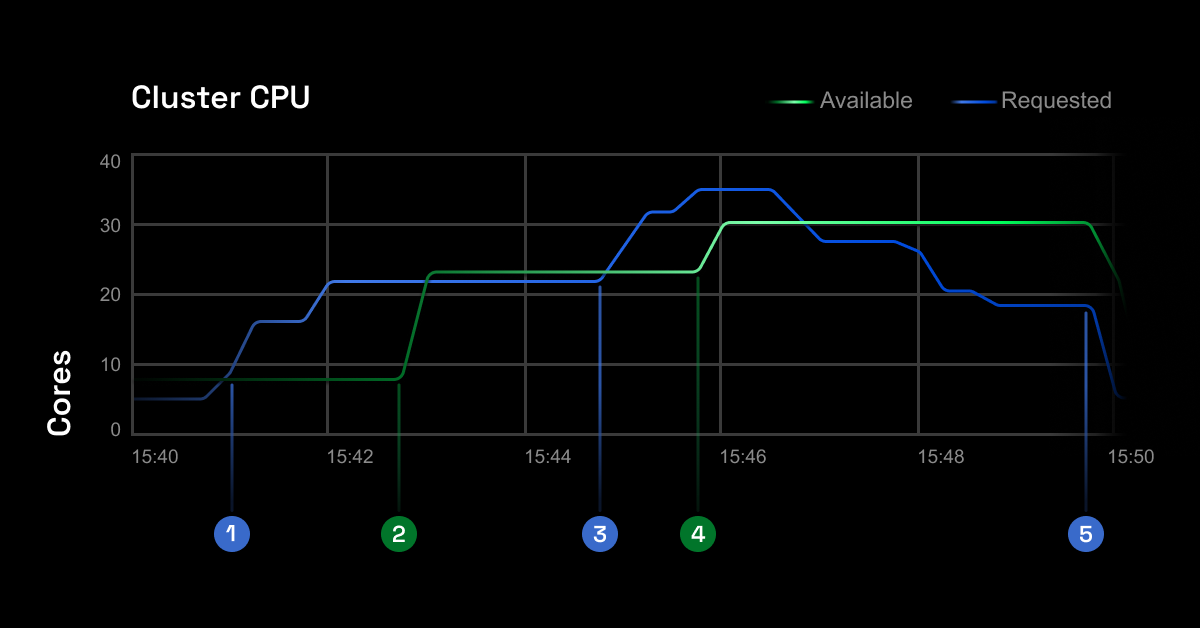
Bottom line: it handles the tedious optimization work so you can focus on building features instead of playing whack-a-mole with cloud costs every sprint.