What S3 Actually Is (Skip the Marketing BS)
S3 launched in 2006 when AWS was still figuring out what "cloud" meant.
Nearly 20 years later, it's become the storage everyone copies because it solved the fundamental problem: reliable, scalable object storage without the nightmare of managing your own infrastructure. Gartner consistently ranks AWS as a leader in cloud storage services.
Here's what you need to know:
S3 stores files (they call them "objects") in buckets. Think of it as a giant key-value store where the key is the file path and the value is your data. Dead simple concept, but the implementation handles edge cases that would make you want to quit engineering.
Why Object Storage Doesn't Suck Like File Systems
Traditional file systems shit the bed when you hit certain limits. Try storing 100 million files in a directory and watch your server cry. S3 doesn't have this problem because it's not pretending to be a file system.
Every file is an "object" with a [key (the path) and metadata](https://docs.aws.amazon.com/Amazon
S3/latest/userguide/UsingMetadata.html).
No directories, no inodes, no filesystem corruption when your server decides to reboot during a write operation. Spotify stores millions of tracks using this exact architecture for their streaming platform.

# This is how you think about S3
- just key-value pairs
my-bucket/users/123/profile.jpg
my-bucket/uploads/2025/01/18/document.pdf
my-bucket/backups/db-dump-20250118.sql.gz
The 99.999999999% durability sounds like marketing bullshit until you realize they replicate your data across multiple data centers automatically.
I've never actually lost data in S3, which is more than I can say for the RAID arrays I managed in 2010.
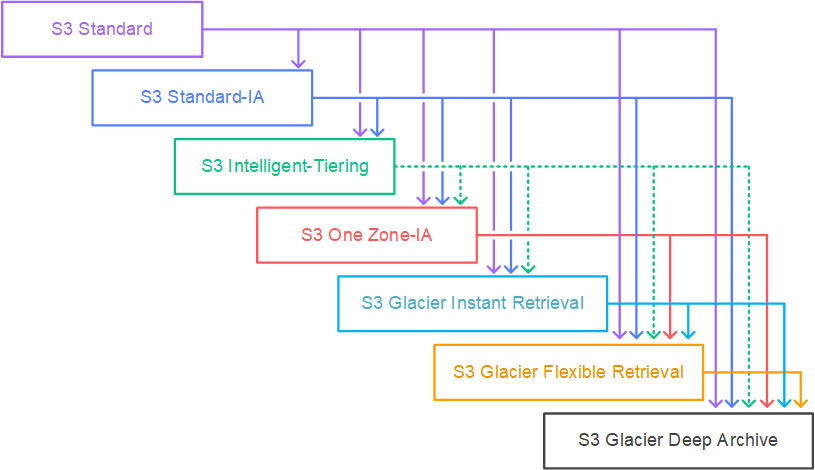
Storage Classes (Where Your Money Goes)
S3 has eight storage classes, which sounds complicated until you realize most people only use three:
Standard for stuff you need right now, Intelligent-Tiering for everything else, and Glacier Deep Archive for backups you hope to never touch.
Standard costs $0.023/GB for instant access. Glacier Deep Archive drops to $0.00099/GB but takes 12+ hours to retrieve your data.
The genius move is Intelligent-Tiering
- it automatically shuffles data between tiers based on access patterns without you having to guess. Airbnb uses this approach to manage their data lake costs.
I learned this the hard way when our backup costs hit $50K/month because everything was in Standard.
Switching to Intelligent-Tiering cut that to $15K overnight.
AWS doesn't make this obvious in their pricing calculator.
Integrations (The Real Reason People Stick With AWS)
S3 works with pretty much everything AWS makes, which is both a blessing and a trap.
Need a CDN? CloudFront reads from S 3.
Want to process files automatically? Lambda triggers when objects change.
Need to run SQL on CSV files? Athena queries S3 directly.
The integration ecosystem is AWS's moat.
Once you're storing everything in S3, using other AWS services becomes trivial. Want to switch to Google Cloud? Good luck migrating petabytes of data and rewriting all your Lambda functions.
I've built data pipelines where S3 events trigger Lambda functions that write to Kinesis streams that feed into EMR clusters that output back to S 3. It works, but you're locked into AWS forever.
Security (Don't Fuck This Up)
S3 security is layered, which means there are multiple ways to accidentally expose your data to the internet. [Bucket policies](https://docs.aws.amazon.com/Amazon
S3/latest/userguide/bucket-policies.html) control who can access your bucket, [IAM policies](https://docs.aws.amazon.com/IAM/latest/User
Guide/reference_policies_examples_s3.html) control what users can do, and if you mess up either one, your data is public.
The good news is [encryption is on by default](https://docs.aws.amazon.com/Amazon
S3/latest/userguide/UsingEncryption.html) now.
AWS learned from too many security breaches where people forgot to enable encryption. Still doesn't help if you make your bucket public, though.
For compliance nerds, S3 Object Lock prevents anyone (including you) from deleting or modifying objects for a set period.
Perfect for backups and regulatory requirements where "oops, I deleted everything" isn't an acceptable excuse. Financial institutions rely on this for SEC compliance and FINRA record retention.
Why It's Expensive But Worth It
S3 starts cheap with a 5GB free tier, then hits you with the real costs once you're hooked.
Storage is $0.023/GB in US regions, but the requests add up fast: $0.0004 per 1,000 GETs and $0.005 per 1,000 PUTs.
The real cost is data transfer.
Moving data out of S3 costs $0.09/GB, which gets painful fast if you're serving large files directly. That's why everyone puts CloudFront in front of S3.
But here's the thing: try building equivalent reliability yourself.
Factor in the cost of hiring ops engineers, buying servers, managing backups, and dealing with data center outages. S3 suddenly looks reasonable. Stripe's engineering team estimates they save millions annually by using S3 instead of self-managed storage infrastructure.