Terraform 1.13.x supposedly has "performance improvements" but honestly, it still feels like running infrastructure deploys through molasses. The fundamental problem isn't bugs - it's architecture. HashiCorp's own performance documentation acknowledges these issues, but the core engine design hasn't fundamentally changed since 2014.
The Real Performance Killers
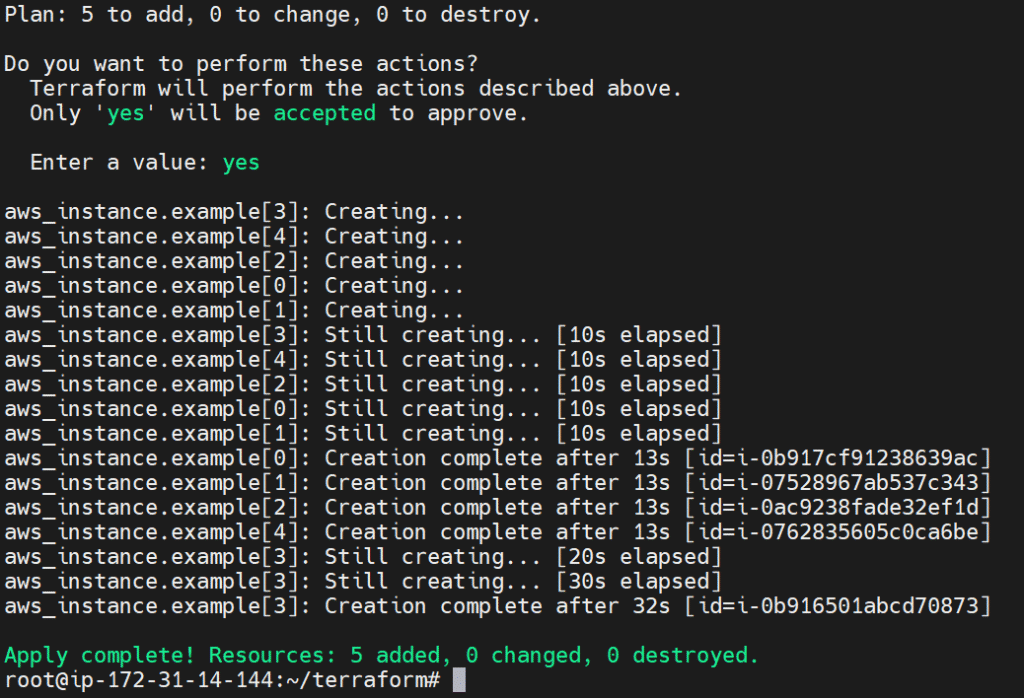
AWS Will Randomly Fuck You Over: API throttling hits right when you need it least. I've had terraform apply running smoothly for 20 minutes, then AWS decides to start throttling EC2 API calls and suddenly everything grinds to a halt. AWS throws RequestLimitExceeded errors when their API decides you're making too many requests. The AWS provider troubleshooting guide basically tells you "wait and retry" - real helpful.

State Files That Grow Like Cancer: Once your state file hits 10MB, every terraform plan becomes a coffee break. I've seen state files grow to 50MB because some genius decided to manage hundreds of Route53 records through Terraform. Remote state on S3 adds another layer of "please wait while we download 50MB just to check if you changed one variable." The state performance documentation says "use smaller state files" but doesn't explain how to fix a 100MB monster that's already managing production.
Dependency Hell: Terraform builds this beautiful dependency graph that forces everything to run sequentially when you need it parallel. Need an RDS instance that depends on a subnet that depends on a VPC? Hope you weren't planning to deploy quickly. The dependency graph gets more twisted than Christmas lights.

Real Performance Numbers (From Actual Hell)
Here's what actually happens when you deploy with Terraform:
- "Simple" deployments (5-10 resources): 2-8 minutes if you're lucky. 15 minutes if AWS is having a bad day.
- Medium deployments (50-100 resources): 10-30 minutes. Budget an hour if you hit provider timeouts.
- Large deployments (500+ resources): Clear your afternoon. I've had applies run for 2+ hours, especially with EKS clusters that take 15 minutes just to spin up.
Terraform Enterprise's default 512MB memory limit is a joke for anything serious. You'll hit OOM errors on deployments that should be routine.
Multi-Cloud = Multi-Pain
Managing AWS, Azure, and GCP in one configuration? Each cloud has different timeout behaviors. AWS might throttle you, Azure will give you cryptic errors about resource providers, and GCP will just randomly decide your service account doesn't have permissions it had 5 minutes ago.
Cross-cloud dependencies are where dreams go to die. Need a GCP instance to connect to AWS RDS? Everything becomes sequential and you're back to watching progress bars like it's 1995. The multi-cloud architecture guides make it look simple but conveniently skip the part where everything takes 3x longer than single-cloud deployments.